






公布人:南京大学PASA大数据实验室顾荣
前言
在上一篇《 Tachyon源代码结构分析(一)》中,我们介绍了Tachyon的四大模块(Client模块、Master模块、Worker模块以及Common模块)的基本功能及其相互关系。从本篇開始我们開始介绍各个模块的详细功能实现以及各个模块的源代码结构。本篇接下来主要对Common模块以及Client模块进行源代码结构分析。
版本号选择
Tachyon眼下的最新公布版为0.6.0,最新开发版为0.7.0-SNAPSHOT。
本篇我们选择的Tachyon版本号为0.6.0。
官方链接:Tachyon-0.6.0
Common模块
Common模块是为Client、Master、Worker所共享的模块,提供了一些配置、常量、路径等通用的调用函数。
Common模块主要包含tachyon.conf包、tachyon.io包、tachyon.util包以及直接从属于tachyon包的类。
以下我们对Common模块所包括的包和源文件进行分析:
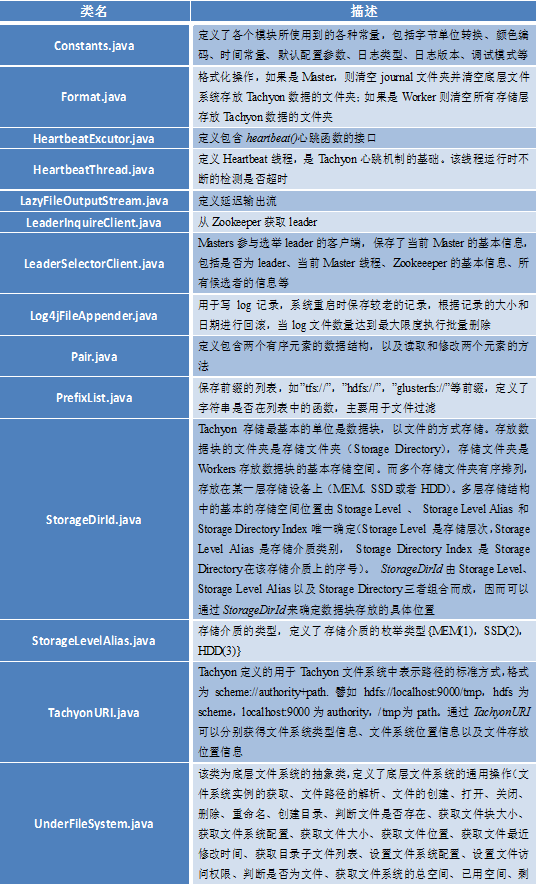
▪ tachyon包
直接从属于tachyon包的类没有统一的性质。每一个类定义了为一个或者多个模块所须要的功能。我们列出下表解释每一个类的详细含义。
▪ tachyon.conf包
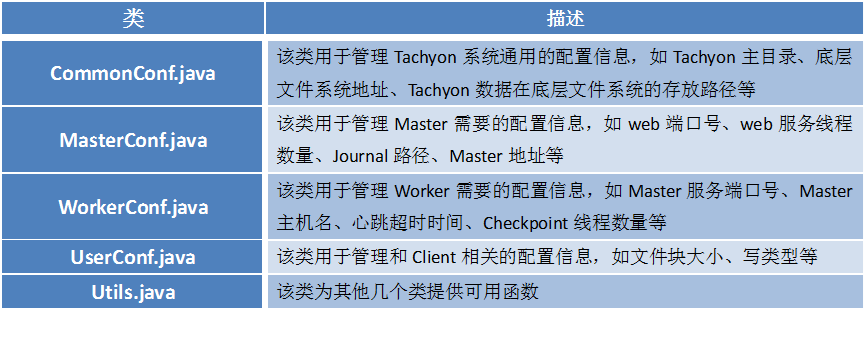
tachyon.conf包包括五个类,分别为CommonConf、MasterConf、WorkerConf、UserConf和Utils。
CommonConf用于管理通用的配置信息。MasterConf用于管理Master模块须要的配置信息。WorkerConf用于管理Worker模块须要的配置信息;UserConf用于管理Client相关的配置信息;Utils为其它四个类提供可调用的函数。在之后的版本号中。CommonConf、MasterConf、WorkerConf和UserConf将会被集中管理。
▪ tachyon.io包
tachyon.io包是Tachyon自己定义的用于读写数据缓存的包,ByteBufferReader和JavaByteBufferReader是继承关系。封装了ByteBuffer的读功能。ByteBufferWriter和JavaByteBufferWriter是继承关系,封装了ByteBuffer的写功能。这四个类的作用主要是方便各个模块调用Tachyon自己定义的类来进行数据缓存的读写訪问,在Tachyon本身的代码结构中。这四个类并未被调用。
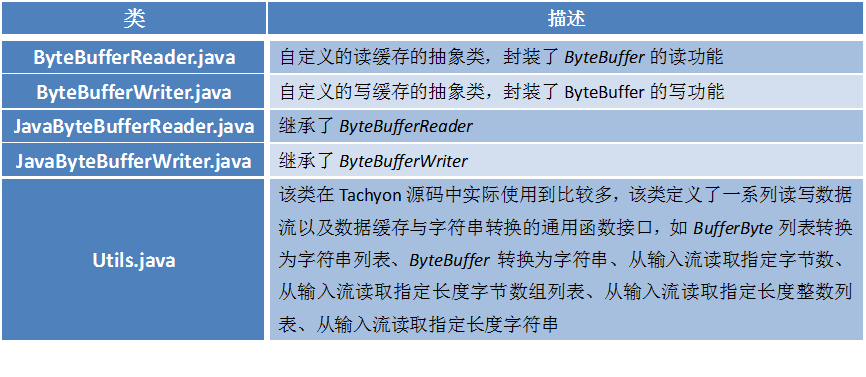

图1. tachyon.io类图
▪ tachyon.util包
tachyon.util包体现了Common模块典型的特征。它定义了为其它一个或者多个模块所须要使用但不方便直接定义的功能,以避免减少软件模块的内聚性。tachyon.util包眼下定义了四个类。分别为CommonUtils、NetworkUtils、ThreadFactoryUtils、UfsUtils。CommonUtils定义了为Tachyon全部模块所共享的通用函数操作。NetworkUtils定义了为Tachyon全部模块所共享的与网络相关的通用函数操作。TheadFactoryUtils定义了工厂创建线程的两种方式;UfsUtils定义了和底层文件系统相关的通用函数操作。

Client模块
Client模块是用户与Tachyon交互的模块,该模块向用户打开了通向Tachyon的大门。总的来说,Client模块由五个包组成,各自是:tachyon.client、tachyon.client.table、tachyon.command、tachyon.hadoop、tachyon.example。这五个包分别负责Client模块不同的功能。tachyon.client向用户提供訪问Tachyon文件系统的API接口;tachyon.client.table包事实上是tachyon.client的一个子包,作用主要是定义Tachyon中表格数据的操作;tachyon.command包向用户提供命令行訪问Tachyon文件系统的接口。tachyon.hadoop包向用户提供了在hadoop程序开发中。使用Tachyon文件系统的接口;tachyon.example包向用户提供了可执行測试例子。
之所以将这些包归为Client模块主要是由于这些包都是面向用户的,为用户编程和使用提供方便。以下我们来进行各个包的具体解析。
▪ tachyon.client包
tachyon.client包是用户编程开发直接须要使用的包,该包提供了对Tachyon文件系统一系列操作的接口。包含对在Tachyon文件系统中创建文件、删除文件、读写文件、获取文件信息等,同一时候定义了文件的读写方式、文件和文件块的输入输出流等。
下表具体介绍了该包的功能。

用户接触比較多的主要是TachyonFS、TachyonFile、FileInStream、FileOutStream、ReadType以及WriteType,通过调用这几个类定义的方法能够方便的对Tachyon文件系统进行读写、改动、删除等訪问操作。
除此以外,下图还包括了table包,table包定义了Tachyon文件系统中的表格。在TachyonFS中调用createRawTable()被创建。
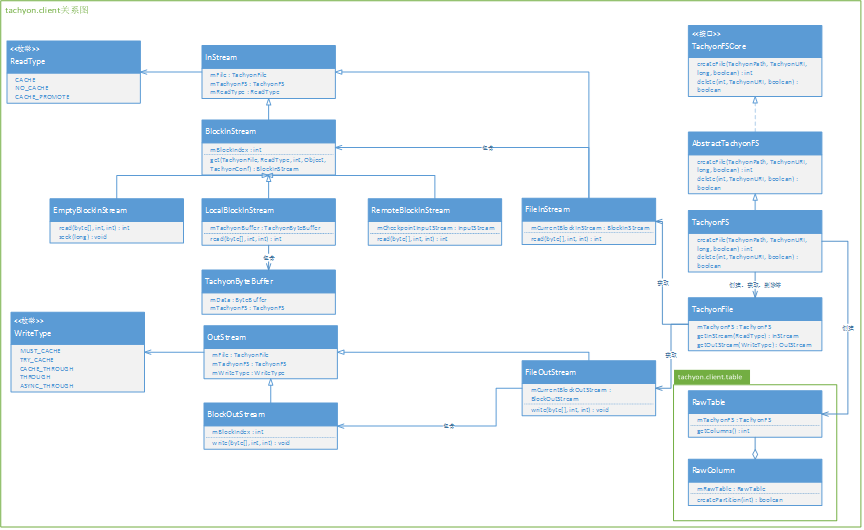
图2. tachyon.client类图
▪ tachyon.client.table包
该包主要用来进行表格的定义和处理,包括两个类:RawColumn和RawTable。
▪ tachyon.command包
Command包也是和用户直接交互的,用户在shell端输入命令对Tachyon文件系统直接进行操作。眼下支持的命令包括cat、copyFromLocal、copyToLocal、count、fileinfo、free、location、ls、lsr、mkdir、pin、printUsage、rename、report、request、rm、rmr、tail、touch、unpin。Command包包括两个类:TFsShell和Utils。

▪ tachyon.hadoop包
该包的存在主要是为了方便hadoop用户直接以Tachyon作为底层文件系统,hadoop计算的数据结果特别是频繁读取的数据保存到Tachyon文件系统中能够提高读写效率。hadoop定义了文件系统处理的抽象类org.apache.hadoop.fs.FileSystem,抽象出文件系统操作的基本函数接口。为了直接对Tachyon文件系统操作。仅仅须要继承并实现org.apache.hadoop.fs.FileSystem抽象类。这里AbstractTFS直接继承了FileSystem抽象类。实现了对Tachyon文件系统操作的基本函数。而TFS和TFSFT都继承了AbstractTFS。主要差别在于是否使用zookeeper模式。在MapReduce计算框架中。我们对文件系统的操作都是基于FileSystem。因而。通过继承关系的动态绑定特性。所存取的数据都会保存到Tachyon文件系统中,从而大幅度提高MapReduce计算框架的效率。
当然。该包不仅对于hadoop计算框架有效,对于spark等计算框架也相同有效。hadoop和spark中使用Tachyon作为底层文件系统的方法能够參考http://blog.csdn.net/u014252240/article/details/41810849
hadoop包中各类的基本关系如图3所看到的:
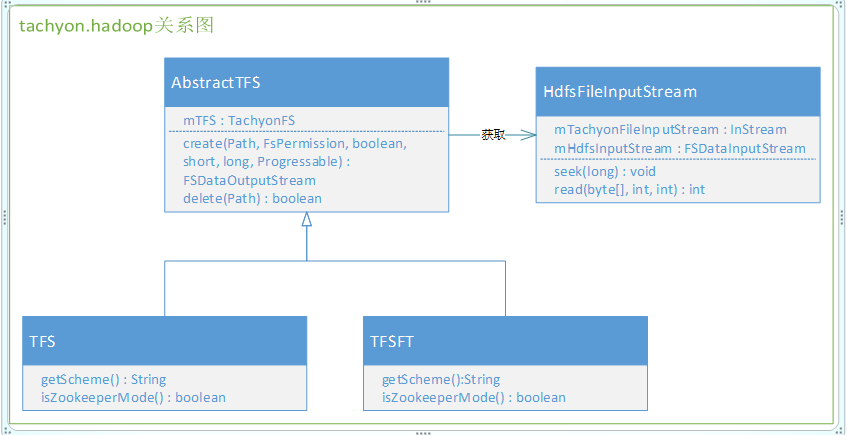
图3. tachyon.hadoop关系图

▪ tachyon.example包
该包定义了使用Tachyon的一些实际用例,也能够用来检測Tachyon安装是否正确。该包的測试例子能够通过命令行命令bin/tachyon runTest <Basic| BasicRawTable | BasicCheckpoint | BasicNonByteBuffer> <MUST_CACHE |TRY_CACHE | CACHE_THROUGH | THROUGH | ASYNC_THROUGH>来执行。
譬如。假设要执行BasicOperations測试例子,能够使用bin/tachyon runTest Basic CACHE_THROUGH。example中的例子包含BasicCheckpoint、BasicNonBytesBufferOperations、BasicOperations、BasicRawTableOperations、Performance。另外Utils相同为全部类提供通用的操作。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









