







Python的并发处理能力臭名昭著。先撇开线程以及GIL方面的问题不说,我觉得多线程问题的根源不在技术上而在于理念。大部分关于Pyhon线程和多进程的资料虽然都很不错,但却过于细节。这些资料讲的都是虎头蛇尾,到了真正实际使用的部分却草草结束了。
1、传统例子
在DDG https://duckduckgo.com/ 搜索“Python threading tutorial”关键字,结果基本上却都是相同的类+队列的示例。
标准线程多进程,生产者/消费者示例:
#Example.py
'''
Standard Producer/Consumer Threading Pattern
'''
import time
import threading
import Queue
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
# queue.get() blocks the current thread until
# an item is retrieved.
msg = self._queue.get()
# Checks if the current message is
# the "Poison Pill"
if isinstance(msg, str) and msg == 'quit':
# if so, exists the loop
break
# "Processes" (or in our case, prints) the queue item
print "I'm a thread, and I received %s!!" % msg
# Always be friendly!
print 'Bye byes!'
def Producer():
# Queue is used to share items between
# the threads.
queue = Queue.Queue()
# Create an instance of the worker
worker = Consumer(queue)
# start calls the internal run() method to
# kick off the thread
worker.start()
# variable to keep track of when we started
start_time = time.time()
# While under 5 seconds..
while time.time() - start_time < 5:
# "Produce" a piece of work and stick it in
# the queue for the Consumer to process
queue.put('something at %s' % time.time())
# Sleep a bit just to avoid an absurd number of messages
time.sleep(1)
# This the "poison pill" method of killing a thread.
queue.put('quit')
# wait for the thread to close down
worker.join()
if __name__ == '__main__':
Producer()
Mmm.. 感觉像是java代码
在此我不想印证采用生产者/消费者模式来处理线程/多进程是错误的— 确实没问题。实际上这也是解决很多问题的最佳选择。但是,我却不认为这是日常工作中常用的方式。
2、问题所在
一开始,你需要一个执行下面操作的铺垫类。接着,你需要创建一个传递对象的队列,并在队列两端实时监听以完成任务。(很有可能需要两个队列互相通信或者存储数据)
Worker越多,问题越大.
下一步,你可能会考虑把这些worker放入一个线程池一边提高Python的处理速度。下面是
IBM tutorial 上关于线程较好的示例代码。这是大家常用到的利用多线程处理web页面的场景
#Example2.py
'''
A more realistic thread pool example
'''
import time
import threading
import Queue
import urllib2
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
content = self._queue.get()
if isinstance(content, str) and content == 'quit':
break
response = urllib2.urlopen(content)
print 'Bye byes!'
def Producer():
urls = [
'http://www.python.org', 'http://www.yahoo.com'
'http://www.scala.org', 'http://www.google.com'
# etc..
]
queue = Queue.Queue()
worker_threads = build_worker_pool(queue, 4)
start_time = time.time()
# Add the urls to process
for url in urls:
queue.put(url)
# Add the poison pillv
for worker in worker_threads:
queue.put('quit')
for worker in worker_threads:
worker.join()
print 'Done! Time taken: {}'.format(time.time() - start_time)
def build_worker_pool(queue, size):
workers = []
for _ in range(size):
worker = Consumer(queue)
worker.start()
workers.append(worker)
return workers
if __name__ == '__main__':
Producer()
感觉效果应该很好,但是看看这些代码!初始化方法、线程跟踪,最糟的是,如果你也和我一样是个容易犯死锁问题的人,这里的join语句就要出错了。这样就开始变得更加复杂了!
到现在为止都做了些什么?基本上没什么。上面的代码都是些基础功能,而且很容易出错。(天啊,我忘了写上在队列对象上调用task_done()方法(我懒得修复这个问题在重新截图)),这真是性价比太低。所幸的是,我们有更好的办法.
3、引入:Map
Map 是个很酷的小功能,也是简化Python并发代码的关键。对那些不太熟悉Map的来说,它有点类似Lisp.它就是序列化的功能映射功能. e.g.
urls = [', ']
results = map(urllib2.urlopen, urls)
这里调用urlopen方法,并把之前的调用结果全都返回并按顺序存储到一个集合中。这有点类似
results = []
for url in urls:
results.append(urllib2.urlopen(url))
Map能够处理集合按顺序遍历,最终将调用产生的结果保存在一个简单的集合当中。
为什么要提到它?因为在引入需要的包文件后,Map能大大简化并发的复杂度!

支持Map并发的包文件有两个:
Multiprocessing,还有少为人知的但却功能强大的子文件 multiprocessing.dummy. .
Digression这是啥东西?没听说过线程引用叫dummy的多进程包文件。我也是直到最近才知道。它在多进程的说明文档中也只被提到了一句。它的效果也只是让大家直到有这么个东西而已。这可真是营销的失误!
Dummy是一个多进程包的完整拷贝。唯一不同的是,多进程包使用进程,而dummy使用线程(自然也有Python本身的一些限制)。所以一个有的另一个也有。这样在两种模式间切换就十分简单,并且在判断框架调用时使用的是IO还是CPU模式非常有帮助。
4、开始使用 multiprocessing & Map
准备使用带有并发的map功能首先要导入相关包文件:
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
然后初始化:
pool = ThreadPool()
就这么简单一句解决了example2.py中build_worker_pool的功能. 具体来讲,它首先创建一些有效的worker启动它并将其保存在一些变量中以便随时访问。
pool对象需要一些参数,但现在最紧要的就是:进程。它可以限定线程池中worker的数量。如果不填,它将采用系统的内核数作为初值。
一般情况下,如果你进行的是计算密集型多进程任务,内核越多意味着速度越快(当然这是有前提的)。但如果是涉及到网络计算方面,影响的因素就千差万别。所以最好还是能给出合适的线程池大小数。
pool = ThreadPool(4) # Sets the pool size to 4
如果运行的线程很多,频繁的切换线程会十分影响工作效率。所以最好还是能通过调试找出任务调度的时间平衡点。
好的,既然已经建好了线程池对象还有那些简单的并发内容。咱们就来重写一些example2.py中的url opener吧!
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
# etc..
]
# Make the Pool of workers
pool = ThreadPool(4)
# Open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
pool.close()
pool.join()
# results = []
# for url in urls:
# result = urllib2.urlopen(url)
# results.append(result)
# # ------- VERSUS ------- #
# # ------- 4 Pool ------- #
# pool = ThreadPool(4)
# results = pool.map(urllib2.urlopen, urls)
# # ------- 8 Pool ------- #
# pool = ThreadPool(8)
# results = pool.map(urllib2.urlopen, urls)
# # ------- 13 Pool ------- #
# pool = ThreadPool(13)
# results = pool.map(urllib2.urlopen, urls)
# Single thread: 14.4 Seconds
# 4 Pool: 3.1 Seconds
# 8 Pool: 1.4 Seconds
# 13 Pool: 1.3 Seconds看吧!只用4行代码就搞定了!其中三行还是固定写法。使用map方法简单的搞定了之前需要40行代码做的事!为了增加趣味性,我分别统计了不同线程池大小的运行时间。
效果惊人!看来调试一下确实很有用。当线程池大小超过9以后,在我本机上的运行效果已相差无几。
5、示例 2:生成缩略图
生成上千张图像的缩略图:
现在咱们看一年计算密集型的任务!我最常遇到的这类问题之一就是大量图像文件夹的处理。
其中一项任务就是创建缩略图。这也是并发中比较成熟的一项功能了。
基础单线程创建过程
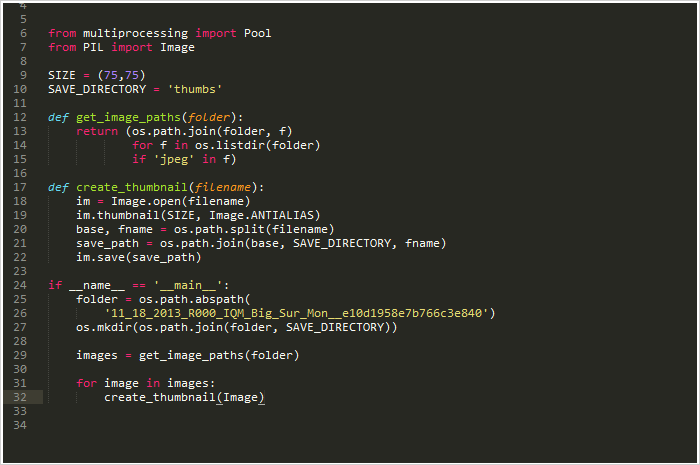
作为示例来说稍微有点复杂。但其实就是传一个文件夹目录进来,获取到里面所有的图片,分别创建好缩略图然后保存到各自的目录当中。
在我的电脑上,处理大约6000张图片大约耗时27.9秒.
如果使用并发map处理替代其中的for循环:
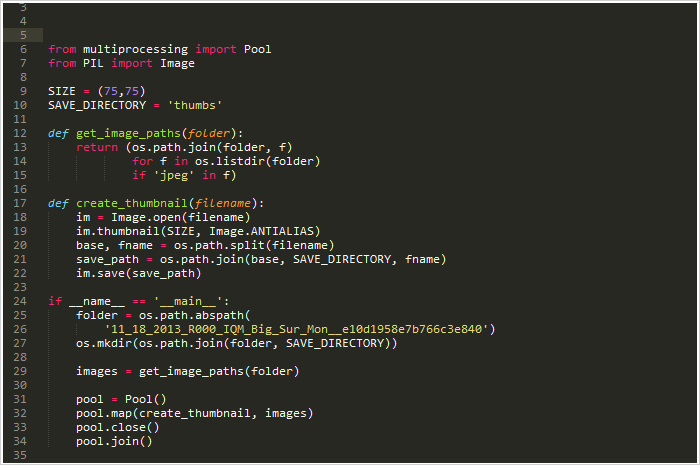
只用了5.6 秒!
就改了几行代码速度却能得到如此巨大的提升。最终版本的处理速度还要更快。因为我们将计算密集型与IO密集型任务分派到各自独立的线程和进程当中,这也许会容易造成死锁,但相对于map强劲的功能,通过简单的调试我们最终总能设计出优美、高可靠性的程序。就现在而言,也别无它法。
好了。来感受一下一行代码的并发程序吧。
6、关于Python并行任务技巧的几点补完
早上逛微博发现了SegmentFault上的这篇文章:关于Python并行任务技巧 。看过之后大有裨益。顺手试了试后遇到几个小坑,记录下来作为补完(作者也有点语焉不详哦^_^)。
6.1 传入的function,只能接收一个传入参数
一开始以为在传入的序列里用tuple可以自动解包成多个参数传进去,可惜实践后是不行的:
#coding=utf8
from multiprocessing import Pool
def do_add(n1, n2):
return n1+n2
pool = Pool(5)
print pool.map(do_add, [(1,2),(3,4),(5,6)])
pool.close()
pool.join()
执行后结果就报错了:
Traceback (most recent call last):
File "mt.py", line 8, in <module>
print pool.map(do_add, [(1,2),(3,4),(5,6)])
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/multiprocessing/pool.py", line 250, in map
return self.map_async(func, iterable, chunksize).get()
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/multiprocessing/pool.py", line 554, in get
raise self._value
TypeError: do_add() takes exactly 2 arguments (1 given)6.2 传入的function必须处理必要的异常
传入的function如果要做长期执行,比如放一个死循环在里面长期执行的话,必须处理必要的异常,不然ctrl+c杀不掉进程,比如:
#coding=utf8
from multiprocessing import Pool
import time
def do_add(n1):
while True:
time.sleep(1)
print n1
pool = Pool(5)
print pool.map(do_add, [1,2,3,4,5,6])
pool.close()
pool.join()这段代码一跑起来是ctrl+c杀不掉的,最后只能把console整个关掉才行。 不过这么写就ok了:
#coding=utf8
from multiprocessing import Pool
import time
def do_add(n1):
try:
while True:
time.sleep(1)
print n1
except:
return n1
pool = Pool(5)
print pool.map(do_add, [1,2,3,4,5,6])
pool.close()
pool.join()补完的补完,有网友提供了解决办法,使用functools的partial可以解决,详见 爆栈
6.3 如何更加高效
第三点是为什么要在子进程里用死循环让其长期执行。窃以为作者的直接把上千个任务暴力丢给进程池的做法并不是最高效的方式,即便是正在执行的进程数和CPU数能匹配得切到好处,但是一大堆的进程切换的开销也会有相当的负担。但是创建几个长期运行的工作进程,每个工作进程处理多个任务,省略掉了大量开启关闭进程的开销,原理上来说会效率高一些。不过这个问题我没有实测过。再不过其实从原理上来说这个开销虽然有但是并不是有多么大,很多时候完全可以忽略,比如作者用的例子。 所以其实更确切一点的需求反而是用于实现生产者消费者模式。因为在作者的例子里,任务数是固定的,不可控的,更多的时候我们反而是需要用生产者创建任务,由worker进程去执行任务。举个例子,生产者监听一个redis的队列,有新url放进去的时候就通知worker进程去取。
代码如下:
#coding=utf8
from multiprocessing import Pool, Queue
import redis
import requests
queue = Queue(20)
def consumer():
r = redis.Redis(host='127.0.0.1',port=6379,db=1)
while True:
k, url = r.blpop(['pool',])
queue.put(url)
def worker():
while True:
url = queue.get()
print requests.get(url).text
def process(ptype):
try:
if ptype:
consumer()
else:
worker()
except:
pass
pool = Pool(5)
print pool.map(process, [1,0,0,0,0])
pool.close()
pool.join()
比起经典的方式来说简单很多,效率高,易懂,而且没什么死锁的陷阱。
7、Refer:
(1)英文原文:https://medium.com/p/40e9b2b36148
(2)原文代码:https://github.com/chriskiehl/Blog/tree/master/40e9b2b36148
(3)关于Python并行任务技巧的几点补充 http://liming.me/2014/01/12/python-multitask-fixed/
(4)在单核 CPU、Python GIL 限制下,多线程需要加锁吗?
https://github.com/onlytiancai/codesnip/blob/master/python/sprace.py
(5)gevent程序员指南 http://xlambda.com/gevent-tutorial/#_8
(6)进程、线程和协程的理解
(7)python 多进程: from multiprocessing.pool import ThreadPool
http://hi.baidu.com/0xcea4/item/ddd133c187a6277089ad9e4b
http://outofmemory.cn/code-snippet/6723/Python-many-process-bingfa-multiprocessing
(8)python的threading和multiprocessing模块初探
http://blog.csdn.net/zhaozhi406/article/details/8137670
(9)使用Python进行并发编程
http://python.jobbole.com/81255/
(10)Python最广为使用的并发库futures使用入门与内部原理
https://mp.weixin.qq.com/s/NBBDou4rIMo9KibVb4fjeg















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









