







1.hive 2个大文件倾斜join如何解决?
设置maxSize和preRedecer的大小,能保证数据的均匀分配。 

注意: 设置Reduce和perReducer就行,性能还不错
MAP阶段优化
•mapred.map.tasks 无效
•num_map_tasks切割大小影响参数
–mapred.max.split.size 默认: 256M
–mapred.min.split.size 默认: 1B
–dfs.block.size 默认:128M
•切割算法
–splitSize = max[minSize,min(maxSize,blockSize)]
–minSize = \({mapred.min.split.size}
–maxSize = \){mapred.max.split.size}
•列裁剪 hive.optimize.cp=true
•map端聚合 hive.map.aggr=true
•Map端谓语下推 hive.optimize.ppd=true
Shuffle阶段优化
•压缩中间数据
–减少磁盘操作
–减少网络传输数据量
•配置方法
–mapred.compress.map.output 设为true
–mapred.compress.output.compression.codec
•org.apache.hadoop.io.compress.LzoCodec
•org.apache.hadoop.io.compress.SnappyCodec
REDUCE阶段优化
• mapred.reduce.tasks 直接设置
• num_reduce_tasks大小影响参数
– hive.exec.reducers.max 默认:999
– hive.exec.reducers.bytes.per.reducer 默认:1G
• 切割算法 (numRTasks重点, 设置perReducer)
– numRTasks = min[maxReducers,input.size/perReducer]
• maxReducers = \({hive.exec.reducers.max}
• perReducer = \){hive.exec.reducers.bytes.per.reducer}
2.MapReduce原理,仔细点
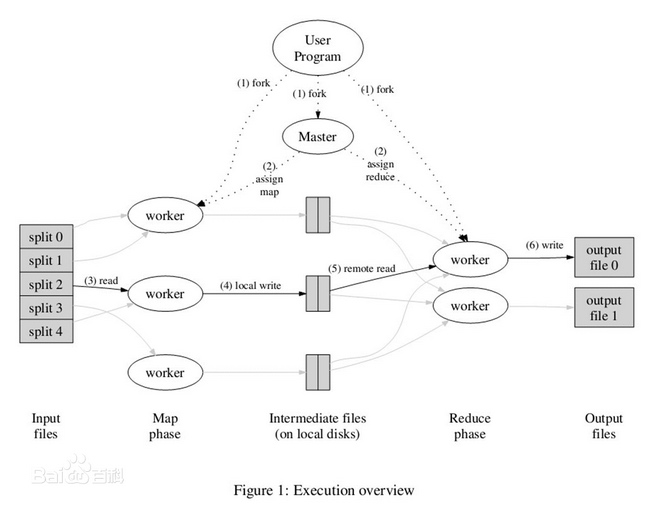 

一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。
1. MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4(文件块);然后使用fork将用户进程拷贝到集群内其它机器上。
2. user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或Reduce作业),worker数量可由用户指定的。
3. 被分配了Map作业的worker,开始读取对应文件块的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业(包含多个map函数)从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
4. 缓存的中间键值对会被定期写入本地磁盘。主控进程知道Reduce的个数,比如R个(通常用户指定)。然后主控进程通常选择一个哈希函数作用于键并产生0~R-1个桶编号。Map任务输出的每个键都被哈希起作用,根据哈希结果将Map的结果存放到R个本地文件中的一个(后来每个文件都会指派一个Reduce任务)。
5. master通知分配了Reduce作业的worker它负责的分区在什么位置。当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
6. reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
7. 当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
8. 所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。















 3398
3398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









