







redo(重做信息)是Oracle在在线(或归档)重做日志文件中记录的信息,万一出现失败时可以利用这些数据来“重放”(或重做)事务。undo(撤销信息)是Oracle在undo段中记录的信息,用于取消或回滚事务。
1 什么是redo
重做日志文件(redo log file)对Oracle数据库来说至关重要。它们是数据库的事务日志。Oracle维护着两类重做日志文件:在线(online)重做日志文件和归档(archived)重做日志文件。这两类重做日志文件都用于恢复;其主要目的是,万一实例失败或介质失败,它们就能派上用场。
如果数据库所在主机掉电,导致实例失败,Oracle会使用在线重做日志将系统恰好恢复到掉电之前的那个时间点。如果磁盘驱动器出现故障(这是一个介质失败),Oracle会 使用归档重做日志以及在线重做日志将该驱动器上的数据备份恢复到适当的时间点。另外,如果你“无意地”截除了一个表,或者删除了某些重要的信息,然后提交 了这个操作,那么可以恢复受影响数据的一个备份,并使用在线和归档重做日志文件把它恢复到这个“意外”发生前的时间点。
归档重做日志文件实际上就是已填满的“旧”在线重做日志文件的副本。系统将日志文件填满时,ARCH进程会在另一个位置建立在线重做日志文件的一个副本,也可以在本地和远程位置上建立多个另外的副本。如果由于磁盘驱动器损坏或者其他物理故障而导致失败,就会用这些归档重做日志文件来执行介质恢复。Oracle拿到这些归档重做日志文件,并把它们应用于数据文件的备份,使这些数据文件能“赶上”数据库的其余部分。归档重做日志文件是数据库的事务历史。
利用闪回技术(flashback),可以执行闪回查询(也就是说,查询过去某个时间点的数据),取消数据库表的删除,将表置回到以前某个时间的状态,等等。因此,现在使用备份和归档重做日志文件来完成传统恢复的情况越来越少。不过,执行恢复是DBA最重要的任务,而且DBA在数据库恢复方面绝对不能犯错误。
每个Oracle数据库都至少有两个在线重做日志组,每个组中至少有一个成员(重做日志文件)。这些在线重做日志组以循环方式使用。Oracle会写组1中的日志文件,等写到组1中文件的最后时,将切换到日志文件组2,开始写这个组中的文件。等到把日志文件组2写满时,会再次切换回日志文件组1(假设只有两个重做日志文件组;如果有3个重做日志文件组,Oracle当然会继续写第3个组)。
数据库之所以成为数据库(而不是文件系统等其他事物),是因为它有自己独有的一些特征,重做日志或事务日志就是其中重要的特性之一。重做日志可能是数据库中最重要的恢复结构,不过,如果没有其他部分(如undo段、分布式事务恢复等),但靠重做日志什么也做不了。重做日志是数据库区别于传统文件系统的一个主要因素。Oracle正写到一半的时候有可能发生掉电,利用在线重做日志,我们就能有效地从这个掉电失败中恢复。归档重做日志则允许我们从介质失败中恢复,如硬盘损坏,或者由于人为错误而导致数据丢失。如果没有重做日志,数据库提供id保护就比文件系统多不了多少。
2 什么是undo
从概念上讲,undo正好与redo相对。你对数据执行修改时,数据库会生成undo信息,这样万一你执行的事务或语句由于某种原因失败了,或者如果你用一条ROLLBACK语句请求回滚,就可以利用这些undo信息将数据放回到修改前的样子。redo用于在失败时重放事务(即恢复事务),undo则用于取消一条语句或一组语句的作用。与redo不同,undo在数据库内部存储在一组特殊的段中,这称为undo段(undo segment)。
“回滚段”(rollback segment)和“undo段“(undo segment)一般认为是同义词。使用手动undo管理时,DBA会创建”回滚段“。使用自动undo管理时,系统将根据需要自动地创建和销毁”undo段“。
通常对undo有一个误解,认为undo用 于数据库物理地恢复到执行语句或事务之前的样子,但实际上并非如此。数据库只是逻辑地恢复到原来的样子,所有修改都被逻辑地取消,但是数据结构以及数据库块本身在回滚后可能大不相同。原因在于:在所有多用户系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要功能之一就是协调对数据的并发访问。也许我们的事务在修改一些块,而一般来讲往往会有许多其他的事务也在修改这些块。因此,不能简单地将一个块放回到我们的事务开始前的样子,这样会撤销其他人 (其他事务)的工作!
例如,假设我们的事务执行了一个INSERT语句,这条语句导致分配一个新区段(也就是说,导致表的空间增大)。通过执行这个INSET,我们将得到一个新的块,格式化这个块以便使用,并在其中放上一些数据。此时,可能出现另外某个事务,它也向这个块中插入数据。如果要回滚我们的事务,显然不能取消对这个块的格式化和空间分配。因此,Oracle回滚时,它实际上会做与先前逻辑上相反的工作。对于每个INSERT,Oracle会完成一个DELETE。对于每个DELETE,Oracle会执行一个INSERT。对于每个UPDATE,Oracle则会执行一个“反UPDATE“,或者执行另一个UPDATE将修改前的行放回去。
这种undo生成对于直接路径操作(direct path operation)不适用,直接路径操作能够绕过表上的undo生成。
怎么才能看到undo生成(undo generation)具体是怎样的呢?也许最容易的方法就是遵循以下步骤:
(1) 创建一个空表。
(2) 对它做一个全部扫描,观察读表所执行的I/O数量。
(3) 在表中填入许多行(但没有提交)
(4) 回滚这个工作,并撤销。
(5) 再次进行全表扫描,观察所执行的I/O数量。
scott@ORCL>create table t
2 as
3 select *
4 from all_objects
5 where 1=0;
表已创建。然后查询这个表,这里在SQL*Plus中启用了AUTOTRACE,以便能测试I/O。
在这个例子中,每次(即每个用例)都会做两次全表扫描。我们的目标只是测试每个用例中第二次完成的I/O。这样可以避免统计在解析和优化期间优化器可能完成的额外I/O。
最初,这个查询需要0个I/O来完成这个表的全表扫描:
scott@ORCL>select * from t;
未选定行
scott@ORCL>set autotrace traceonly statistics
scott@ORCL>select * from t;
未选定行
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
1344 bytes sent via SQL*Net to client
509 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
scott@ORCL>set autotrace off接下来,向表中增加大量数据。这会使它“扩大“,不过随后再将其回滚:
scott@ORCL>insert into t select * from all_objects;
已创建71902行。
scott@ORCL>rollback;
回退已完成。现在,如果再次查询这个表,会发现这一次读表所需的I/O比先前多得多:
scott@ORCL>select * from t;
未选定行
scott@ORCL>set autotrace traceonly statistics
scott@ORCL>select * from t;
未选定行
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
1086 consistent gets
0 physical reads
0 redo size
1344 bytes sent via SQL*Net to client
509 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed前面的INSERT导致将一些块增加到表的高水位线(high-water mark,HWM)之下,这些块没有因为回滚而消失,它们还在那里,而且已经格式化,只不过现在为空。全表扫描必须读取这些块,看看其中是否包含行。这说明,回滚只是一个“将数据库还原“的逻辑操作。数据库并非真的还原成原来的样子,只是逻辑上相同而已。
2.1 redo和undo如何协作
尽管undo信息存储在undo表空间或undo段中,但也会受到redo的保护。换句话说,会把undo数据当成是表数据或索引数据一样,对undo的修改会生成一些redo,这些redo将计入日志。为什么会这样呢?稍后在讨论系统崩溃时发生的情况时将会解释它,到时你会明白了。将undo数据增加到undo段中,并像其他部分的数据一样在缓冲区缓存中得到缓存。
INSERT-UPDATE-DELETE示例场景
作为一个例子,我们将分析对于下面这组语句可能发生什么情况:
insert into t (x,y) values (1,1);
update t set x = x+1 where x = 1;
delete from t where x = 2;我们会沿着不同的路径完成这个事务,从而得到以下问题的答案:
? 如果系统在处理这些语句的不同时间点上失败,会发生什么情况?
? 如果在某个时间点上ROLLBACK,会发生什么情况?
? 如果成功并COMMIT,会发生什么情况?
1. INSERT
对于第一条INSERT INTO T语句,redo和undo都会生成。所生成的undo信息足以使INSERT“消失“。INSERT INTO T生成的redo信息则足以让这个插入”再次发生“。
这里缓存了一些已修改的undo块、索引块和表数据块。这些块得到重做日志缓冲区中相应条目的“保护“。
? 假想场景:系统现在崩溃
SGA会被清空,但是我们并不需要SGA里的任何内容。重启动时就好像这个事务从来没有发生过一样。没有将任何已修改的块刷新输出到磁盘,也没有任何redo刷新输出到磁盘。我们不需要这些undo或redo信息来实现实例失败恢复。
? 假想场景:缓冲区缓存现在已满
在这种情况下,DBWR必须留出空间,要把已修改的块从缓存刷新输出。如果是这样,DBWR首先要求LGWR将保护这些数据库块的redo条目刷新输出。DBWR将任何有修改的块写至磁盘之前,LGWR必须先刷新输出与这些块相关的redo信息。这是有道理的——如果我们要刷新输出表T中已修改的块,但没有刷新输出与undo块关联的redo条目,倘若系统失败了,此时就会有一个已修改的表T块,而没有与之相关的redo信息。在写出这些块之前需要先刷新输出重做日志缓存区,这样就能重做(重做)所有必要的修改,将SGA放回到现在的状态,从而能发生回滚。
我们生成了一些已修改的表和索引块。这些块有一些与之关联的undo段块,这3类块都会生成redo来保护自己。重做日志缓冲区 会在以下情况刷新输出:每3秒一次;缓冲区1/3满时或者包含了1MB的缓冲数据;或者是只要发生提交就会刷新输出。重做日志缓冲区还有可能会在处理期间的某一点上刷新输出。
2 UPDATE
UPDATE所带来的工作与INSERT大体一样。不过UPDATE生成的undo量更大;由于存在更新,所以需要保存一些“前“映像。
块缓冲区缓存中会有更多新的undo段块。为了撤销这个更新,如果必要,已修改的数据库表和索引块也会放在缓存中。我们还生成了更多的重做日志缓存区条目。下面假设前面的插入语句生成了一些重做日志,其中有些重做日志已经刷新输出到磁盘上,有些还放在缓存中。
? 假想场景:系统现在崩溃
启动时,Oracle会读取重做日志,发现针对这个事务的一些重做日志条目。给定系统的当前状态,利用重做日志文件中对应插入的redo条目,并利用仍在缓冲区中对应插入的redo信息,Oracle会“前滚”插入。现在有一些undo块(用以撤销插入)、已修改的表块(刚插入后的状态),以及已修改的索引块(刚插入后的状态)。由于系统正在进行崩溃恢复,而且我们的会话还不再连接(这是当然),Oracle发现这个事务从未提交,因此会将其回滚。它取刚刚在缓冲区缓存中前滚得到的undo,并将这些undo应用到数据和索引块,使数据和索引块“恢复”为插入发生前的样子。现在一切都回到从前。磁盘上的块可能会反映前面的INSERT,也可能不反映(这取决于在崩溃前是否已经将块刷新输出)。如果磁盘上的块确实反映了插入,而实际上现在插入已经被撤销,当从缓冲区缓存刷新输出块时,数据文件就会反映出插入已撤销。如果磁盘上的块本来就没有反映前面的插入,就不用去管它——这些块以后肯定会被覆盖。
这个场景涵盖了崩溃恢复的基本细节。系统将其作为一个两步的过程来完成。首先前滚,把系统放到失败点上,然后回滚尚未提交的所有工作。这个动作会再次同步数据文件。它会重放已经进行的工作,并撤销尚未完成的所有工作。
? 假想场景:应用回滚事务
此时,Oracle会发现这个事务的undo信息可能在缓存的undo段块中(基本上是这样),也可能已经刷新输出到磁盘上(对于非常大的事务,就往往是这种情况)。它会把undo信息应用到缓冲区缓存中的数据和索引块上,或者倘若数据和索引块已经不在缓存中,则要从磁盘将数据和索引块读入缓存,再对其应用undo。这些块会恢复为其原来的行值,并刷新输出到数据文件。
这个场景比系统崩溃更常见。需要指出,有一点很有用:回滚过程中从不涉及重做日志。只有恢复和归档时会当前重做日志。这对于调优是一个很重要的概念:重做日志是用来写的(而不是用于读)。Oracle不会在正常的处理中读取重做日志。只要你有足够的设备,使得ARCH读文件时,LGWR能写到另一个不同的设备,那么就不存在重做日志竞争。Oracle的目标是:可以顺序地写日志,而且在写日志时别人不会读日志。
3. DELETE
同样,DELETE会生成undo,块将被修改,并把redo发送到重做日志缓冲区。这与前面没有太大的不同。实际上,它与UPDATE如此类似。
4. COMMIT
我们已经看到了多种失败场景和不同的路径,现在终于到COMMIT了。在此,Oracle会把重做日志缓冲区刷新输出到磁盘。
已修改的块放在缓冲区缓存中;可能有一些块已经刷新输出到磁盘上。重做这个事务所需的全部redo都安全地存放在磁盘上,现在修改已经是永久的了。如果从数据文件直接读取数据,可能会看到块还是事务发生前的样子,因为很有可能DBWR还没有(从缓冲区缓存)写出这些块。这没有关系,如果出现失败,可以利用重做日志文件来得到最新的块。undo信息会一直存在,除非undo段回绕重用这些undo块。如果某些对象受到影响,Oracle会使用这个undo信息为需要这些对象的会话提供对象的一致读。
3 提交和回滚处理
3.1 COMMIT做什么
COMMIT通常是一个非常快的操作,而不论事务大小如何。
不论事务有多大,COMMIT的响应时间一般都很“平”(flat,可以理解为无高低变化)。这是因为COMMIT并没有太多的工作去做,不过它所做的确实至关重要。
这 一点很重要,之所以要了解并掌握这个事实,原因之一是:这样你就能心无芥蒂地让事务有足够的大小。许多开发人员会人为地限制事务的大 小,分别提交太多的行,而不是一个逻辑工作单元完成后才提交。这样做主要是出于一种错误的信念,即认为可以节省稀有的系统资源,而实际上这只是增加了资源 的使用。如果一行的COMMIT需要X个时间单位,1,000次COMMIT也同样需要X个时间单位,倘若采用以下方式执行工作,即每行提交一次共执行1,000次COMMIT,就会需要1000*X各时间单位才能完成。如果只在必要时才提交(即逻辑工作单元结束时),不仅能提高性能,还能减少对共享资源的竞争(日志文件、各种内部闩等)。通过一个简单的例子就能展示出过多的提交要花费更长的时间。这里将使用一个Java应用,不过对于大多数其他客户程序来说,结果可能都是类似的,只有PL/SQL除外。首先,下面是我们要插入的示例表:
scott@ORCL>create table test
2 (
3 ID NUMBER not null,
4 CODE VARCHAR2(20),
5 DESCR VARCHAR2(20),
6 INSERT_USER VARCHAR2(30) ,
7 INSERT_DATE DATE
8 );
表已创建。
scott@ORCL>desc test
名称
是否为空? 类型
------------- -------- ------------------------
ID
NOT NULL NUMBER
CODE
VARCHAR2(20)
DESCR
VARCHAR2(20)
INSERT_USER
VARCHAR2(30)
INSERT_DATE
DATEJava程序要接受两个输入:要插入(INSERT)的行数(iters),以及两次提交之间插入的行数(commitCnt)。它先连接到数据库,将autocommit(自动提交)设置为off(所有Java代码都应该这么做),然后将doInserts()方法共调用3次:
? 第一次调用只是“热身”(确保所有类都已经加载)。
? 第二次调用指定了要插入(INSERT)的行数,并指定一次提交多少行(即每N行提交一次)。
? 最后一次调用将要插入的行数和一次提交的行数设置为相同的值(也就是说,所有行都插入之后才提交)。
然后关闭连接,并退出:
import corp.creditease.rsc.service.IDataCarrierService;
import corp.creditease.rsc.service.impl.DataCarrierServiceImpl;
import org.junit.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Date;
/**
* Created by Anna on 2017/7/21.
*/
public class Test1 {
public static void main(String arr[]) throws Exception {
try {
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
Connection con = DriverManager.getConnection
("jdbc:oracle:thin:@localhost:1521:orcl",
"scott", "123456");
Integer iters = new Integer(arr[0]);
Integer commitCnt = new Integer(arr[1]);
con.setAutoCommit(false);
doInserts(con, 1, 1);
doInserts(con, iters.intValue(), commitCnt.intValue());
doInserts(con, iters.intValue(), iters.intValue());
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
static void doInserts(Connection con, int count, int commitCount)
throws Exception {
PreparedStatement ps =
con.prepareStatement
("insert into test " +
"(id, code, descr, insert_user, insert_date)"
+ " values (?,?,?, user, sysdate)");
int rowcnt = 0;
int committed = 0;
long start = new Date().getTime();
for (int i = 0; i < count; i++) {
ps.setInt(1, i);
ps.setString(2, "PS - code" + i);
ps.setString(3, "PS - desc" + i);
ps.executeUpdate();
rowcnt++;
if (rowcnt == commitCount) {
con.commit();
rowcnt = 0;
committed++;
}
}
con.commit();
long end = new Date().getTime();
System.out.println
("pstatement " + count + " times in " +
(end - start) + " milli seconds committed = " + committed);
}
}
doInserts()方法相当简单。首先准备(解析)一条INSERT语句,以便多次反复绑定/执行这个INSERT。
然后根据要插入的行数循环,反复绑定和执行这个INSERT。另外,它会检查一个行计数器,查看是否需要COMMIT,或者是否已经不在循环范围内。还要注意,我们分别在循环之前和循环之后获取了当前时间,从而监视并报告耗用的时间。
下面根据不同的输入发放运行这个代码:
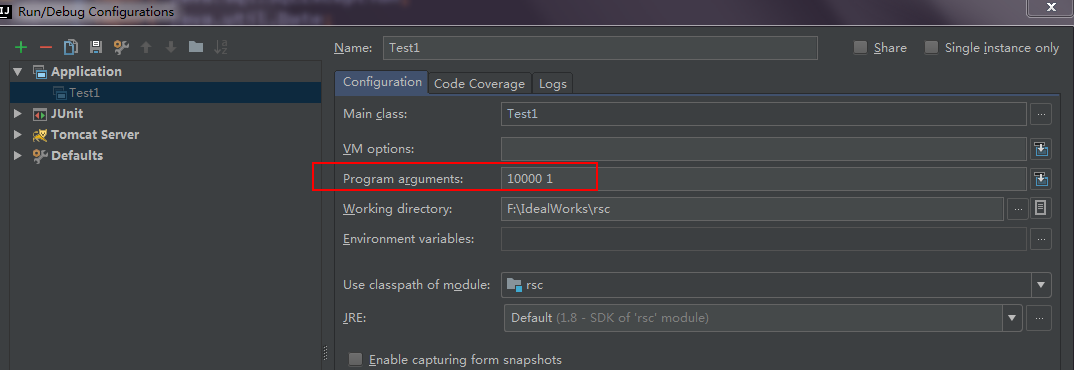
pstatement 1 times in 0 milli seconds committed = 1
pstatement 10000 times in 5501 milli seconds committed = 10000
pstatement 10000 times in 1961 milli seconds committed = 1----------------------------------------------------------------------------------------
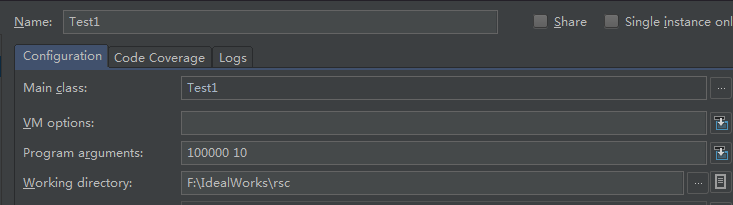
pstatement 1 times in 0 milli seconds committed = 1
pstatement 100000 times in 20721 milli seconds committed = 10000
pstatement 100000 times in 9157 milli seconds committed = 1----------------------------------------------------------------------------------------
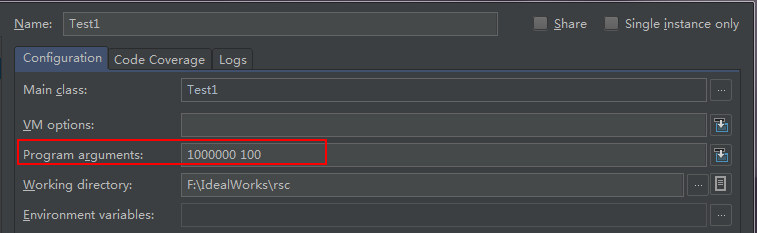
pstatement 1 times in 31 milli seconds committed = 1
pstatement 1000000 times in 113189 milli seconds committed = 10000
pstatement 1000000 times in 95054 milli seconds committed = 1
可以看到,提交得越多,花费的时间就越长。这只是单用户的情况,如果有多个用户在做同样的工作,所有这些用户都过于频繁地提交,那么得到的数字将飞速增长。
在其他类似的情况下,我们也不止一次地听到过同样的“故事”。例如,如果不使用绑定变量,而且频繁地完成硬解析,这会严重地降低并发性,原因是存在库缓存竞争和过量的CPU占用。即使转而使用绑定变量,如果过于频繁地软解析,也会带来大量的开销(导致过多软解析的原因可能是:执意地关闭游标,尽管稍后就会重用这些游标)。必须在必要时才完成操作,COMMIT就是这样的一种操作。最好根据业务需求来确定事务的大小,而不是错误地为了减少数据库上的资源使用而“压缩”事务。
在这个例子中,COMMIT的开销存在两个因素:
? 显然会增加与数据库的往返通信。如果每个记录都提交,生成的往返通信量就会大得多。
? 每次提交时,必须等待redo写至磁盘。这会导致“等待”。在这种情况下,等待称为“日志文件同步”(log file sync)。
? 只需对这个Java应用稍做修改就可以观察到后面这一条。我们将做两件事情:
? 增加一个DBMS_MONITOR调用,启用对等待事件的SQL跟踪。在Oracle9i中,则要使用alter session set events ‘10046 trace name context forever, level 12’,因为
DBMS_MONITOR是Oracle 10g中新增的。
? 把con.commit()调用改为一条完成提交的SQL语句调用。如果使用内置的JDBC commit()调用,这不会向跟踪文件发出SQL COMMIT语句,而TKPROF(用于格式化跟踪文件的工具)也不会报告完成COMMIT所花费的时间。
如果在每个INSERT之后都提交,几乎每次都要等待。尽管每次只等待很短的时间,但是由于经常要等待,这些时间就会累积起来。与之形成鲜明对比,如果只提交一次,就不会等待很长时间(实际上,这个时间实在太短了,以至于简直无法度量)。这说明,COMMIT是一个很快的操作;我们希望响应时间或多或少是“平”的,而不是所完成工作量的一个函数。
那么,为什么COMMIT的响应时间相当“平”,而不论事务大小呢?在数据库中执行COMMIT之前,困难的工作都已经做了。我们已经修改了数据库中的数据,所以99.9%的工作都已经完成。例如,已经发生了以下操作:
? 已经在SGA中生成了undo块。
? 已经在SGA中生成了已修改数据块。
? 已经在SGA中生成了对于前两项的缓存redo。
? 取决于前三项的大小,以及这些工作花费的时间,前面的每个数据(或某些数据)可能已经刷新输出到磁盘。
? 已经得到了所需的全部锁。
执行COMMIT时,余下的工作只是:
1. 为事务生成一个SCN。SCN是Oracle使用的一种简单的计时机制,用于保证事务的顺序,并支持失败恢复。SCN还用于保证数据库中的读一致性和检查点。可以把SCN看作一个钟摆,每次有人COMMIT时,SCN都会增1.
2. LGWR将所有余下的缓存重做日志条目写到磁盘,并把SCN记录到在线重做日志文件中。这一步就是真正的COMMIT。如果出现了这一步,即已经提交。事务条目会从V$TRANSACTION中“删除”,这说明我们已经提交。
3. V$LOCK中记录着我们的会话持有的锁,这些所都将被释放,而排队等待这些锁的每一个人都会被唤醒,可以继续完成他们的工作。
4. 如果事务修改的某些块还在缓冲区缓存中,则会以一种快速的模式访问并“清理”。块清除(Block cleanout)是指清除存储在数据库块首部的与锁相关的信息。实质上讲,我们在清除块上的事务信息,这样下一个访问这个块的人就不用再这么做了。我们采用一种无需生成重做日志信息的方式来完成块清除,这样可以省去以后的大量工作。
可以看到,处理COMMIT所要做的工作很少。其中耗时最长的操作要算LGWR执行的活动(一般是这样),因为这些磁盘写是物理磁盘I/O。不过,这里LGWR花费的时间并不会太多,之所以能大幅减少这个操作的时间,原因是LGWR一直在以连续的方式刷新输出重做日志缓冲区的内容。在你工作期间,LGWR并非缓存着你做的所有工作;实际上,随着你的工作的进行,LGWR会在后台增量式地刷新输出重做日志缓冲区的内容。这样做是为了避免COMMIT等待很长时间来一次性刷新输出所有的redo。
因此,即使我们有一个长时间运行的事务,但在提交之前,它生成的许多缓存重做日志已经刷新输出到磁盘了(而不是全部等到提交时才刷新输出)。这也有不好的一面,COMMIT时,我们必须等待,直到尚未写出的所有缓存redo都已经安全写到磁盘上才行。也就是说,对LGWR的调用是一个同步(synchronous)调用。尽管LGWR本身可以使用异步I/O并行地写至日志文件,但是我们的事务会一直等待LGWR完成所有写操作,并收到数据都已在磁盘上的确认才会返回。
PL/SQL提供了提交时优化(commit-time optimization)。LGWR是一个同步调用,我们要等待它完成所有写操作。PL/SQL引擎不同,要认识到直到PL/SQL例程完成之前,客户并不知道这个PL/SQL例程中是否发生了COMMIT,所以PL/SQL引擎完成的是异步提交。它不会等待LGWR完成;相反,PL/SQL引擎会从COMMIT调用立即返回。不过,等到PL/SQL例程完成,我们从数据库返回客户时,PL/SQL例程则要等待LGWR完成所有尚未完成的COMMIT。因此,如果在PL/SQL中提交了100次,然后返回客户,会发现由于存在这种优化,你只会等待LGWR一次,而不是100次。指导原则是,应该在逻辑工作单元完成时才提交,而不要在此之前草率地提交。
如果你在执行分布式事务或者以最大可能性模式执行Data Guard,PL/SQL中的这种提交时优化可能会被挂起。因为此时存在两个参与者,PL/SQL必须等待提交确实完成后才能继续。
为了说明COMMIT是一个“响应时间很平”的操作,下面将生成不同大小的redo,并测试插入(INSERT)和提交(COMMIT)的时间。为此,还是在SQL*Plus中使用AUTOTRACE。首先创建一个大表(要把其中的测试数据插入到另一个表中),再创建一个空表:
scott@ORCL>@D:\app\Administrator\product\11.2.0\big_table.sql 100000
表已创建。
表已更改。
原值 3: l_rows number := &1;
新值 3: l_rows number := 100000;
PL/SQL 过程已成功完成。
表已更改。
PL/SQL 过程已成功完成。
COUNT(*)
----------
100000
scott@ORCL>create table t as select * from big_table where 1=0;
表已创建。然后在SQL*Plus中运行以下命令:
scott@ORCL>set timing on
scott@ORCL>set autotrace on statistics;
scott@ORCL>insert into t select * from big_table where rownum <= 10;
已创建10行。
已用时间: 00: 00: 00.18
统计信息
----------------------------------------------------------
459 recursive calls
56 db block gets
72 consistent gets
6 physical reads
7196 redo size
1134 bytes sent via SQL*Net to client
1301 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
10 rows processed
scott@ORCL>commit;
提交完成。
已用时间: 00: 00: 00.03
scott@ORCL>insert into t select * from big_table where rownum <= 100;
已创建100行。
已用时间: 00: 00: 00.03
统计信息
----------------------------------------------------------
1 recursive calls
13 db block gets
8 consistent gets
0 physical reads
9936 redo size
1134 bytes sent via SQL*Net to client
1302 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
100 rows processed
scott@ORCL>commit;
提交完成。
已用时间: 00: 00: 00.00
scott@ORCL>insert into t select * from big_table where rownum <= 1000;
已创建1000行。
已用时间: 00: 00: 00.04
统计信息
----------------------------------------------------------
65 recursive calls
208 db block gets
66 consistent gets
15 physical reads
113008 redo size
1134 bytes sent via SQL*Net to client
1303 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
1000 rows processed
scott@ORCL>commit;
提交完成。
已用时间: 00: 00: 00.00
scott@ORCL>insert into t select * from big_table where rownum <= 10000;
已创建10000行。
已用时间: 00: 00: 00.07
统计信息
----------------------------------------------------------
449 recursive calls
1807 db block gets
523 consistent gets
128 physical reads
1136052 redo size
1134 bytes sent via SQL*Net to client
1304 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
10000 rows processed
scott@ORCL>commit;
提交完成。
已用时间: 00: 00: 00.00
scott@ORCL>insert into t select * from big_table where rownum <= 100000;
已创建100000行。
已用时间: 00: 00: 04.73
统计信息
----------------------------------------------------------
353 recursive calls
13306 db block gets
4315 consistent gets
1283 physical reads
12054296 redo size
1135 bytes sent via SQL*Net to client
1305 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
100000 rows processed
scott@ORCL>commit;
提交完成。
已用时间: 00: 00: 00.00在此监视AUTOTRACE提供的redo size(redo大小)统计,并通过set timing on监视计时信息。
尝试插入不同数目的行(行数从10到100,000,每次增加一个数量级)。
插入行数 插入时间(秒) redo大小(字节) 提交时间(秒)
10 00.18 7196 00.03
100 00.03 9936 00.00
1,000 00.04 113008 00.00
10,000 00.07 1136052 00.00
100,000 04.73 12054296 00.00
可以看到,使用一个精确度为百分之一秒的计数器度量时,随着生成不同数量的redo(从7196字节到12MB),却几乎测不出COMMIT时间的差异。在我们处理和生成重做日志时,LGWR也没有闲着,它在后台不断地将缓存的重做信息刷新输出到磁盘上。所以,我们生成12MB的重做日志信息时,LGWR一直在忙着,可能每1MB左右刷新输出一次。等到COMMIT时,剩下的重做日志信息(即尚未写出到磁盘的redo)已经不多了,可能与创建10行数据生成的重做日志信息相差无几。不论生成了多少redo,结果应该是类似的(但可能不完全一样)。
3.2 ROLLBACK做什么
把COMMIT改为ROLLBACK,可能会得到完全不同的结果。回滚时间绝对是所修改数据量的一个函数。修改上一节中的脚本,要求完成一个ROLLBACK(只需把COMMIT改成ROLLBACK),计时信息将完全不同。
ROLLBACK必须物理地撤销我们所做的工作。类似于COMMIT,必须完成一系列操作。在到达ROLLBACK之前,数据库已经做了大量的工作。可能已经发生的操作如下:
1. 已经在SGA中生成了undo块。
2. 已经在SGA中生成了已修改数据块。
3. 已经在SGA中生成了对于前两项的缓存redo。
4. 取决于前三项的大小,以及这些工作花费的时间,前面的每个数据(或某些数据)可能已经刷新输出到磁盘。
5. 已经得到了所需的全部锁。
ROLLBACK时,要做以下工作:
1. 撤销已做的所有修改。其完成方式如下:从undo段读回数据,然后实际上逆向执行前面所做的操作,并将undo条目标记为已用。如果先前插入了一行,ROLLBACK会将其删除。如果更新了一行,回滚就会取消更新。如果删除了一行,回滚将把它再次插入。
2. 会话持有的所有锁都将释放,如果有人在排队等待我们持有的锁,就会被唤醒。
与此不同,COMMIT只是将重做日志缓冲区中剩余的数据刷新到磁盘。与ROLLBACK相比,COMMIT完成的工作非常少。这里的关键是,除非不得已,否则不会希望回滚。回滚操作的开销很大,因为你花了大量的时间做工作,还要花大量的时间撤销这些工作。除非你有把握肯定会COMMIT你的工作,否则干脆什么也别做。
4 分析redo
作为一名开发人员,应该能够测量你的操作生成了多少redo,这往往很重要。生成的redo越多,你的操作花费的时间就越长,整个系统也会越慢。你不光在影响你自己的会话,还会影响每一个会话。redo管理是数据库中的一个串行点。任何Oracle实例都只有一个LGWR,最终所有事务都会归于LGWR,要求这个进程管理它们的redo,并COMMIT其事务,LGWR要做的越多,系统就会越慢。通过查看一个操作会生成多少redo,并对一个问题的多种解决方法进行测试,可以从中找出最佳的方法。
4.1 测量redo
要查看生成的redo量相当简单,可以使用了SQL*Plus的内置特性AUTOTRACE。不过AUTOTRACE只能用于简单的DML,对其他操作就力所不能及了,例如,它无法查看一个存储过程调用做了什么。为此,我们需要访问两个动态性能视图:
1. V$MYSTAT,其中有会话的提交信息。
2. V$STATNAME,这个视图能告诉我们V$MYSTAT中的每一行表示什么(所查看的统计名)。
因为我经常要做这种测量,所以使用了两个脚本,分别为mystat和mystat2。mystat.sql脚本把我感兴趣的统计初始值(如redo大小)保存在一个SQL*Plus变量中。
mystat.sql:
set verify off
column value new_val V
define S="&1"
set autotrace off
select a.name, b.value
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and lower(a.name) like '%' || lower('&S')||'%'
/mystat2.sql脚本只是打印出该统计的初始值和结束值之差:
set verify off
select a.name, b.value V, to_char(b.value-&V,'999,999,999,999') diff
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and lower(a.name) like '%' || lower('&S')||'%'
/下面,可以测量一个给定事务会生成多少redo。我们只需这样做:
@mystat "redo size"
...process...
@mystat2例如:
scott@ORCL>@D:\app\Administrator\product\11.2.0\mystat "redo size"
NAME VALUE
---------------------------------------------------------------- ----------
redo size 28053348
redo size for lost write detection 0
redo size for direct writes 7576
已用时间: 00: 00: 00.12
scott@ORCL>insert into t select * from big_table;
已创建100000行。
已用时间: 00: 00: 00.97
scott@ORCL>@D:\app\Administrator\product\11.2.0\mystat2
NAME V DIFF
---------------------------------------------------------------- ---------- ----------------
redo size 39946884 39,939,308
redo size for lost write detection 0 -7,576
redo size for direct writes 7576 0
已用时间: 00: 00: 00.01如上所示,这个INSERT生成了大约39MB的redo。你可能想与一个直接路径INSERT生成的redo做个比较,如下:
scott@ORCL>@D:\app\Administrator\product\11.2.0\mystat "redo size"
NAME VALUE
---------------------------------------------------------------- ----------
redo size 39946884
redo size for lost write detection 0
redo size for direct writes 7576
已用时间: 00: 00: 00.01
scott@ORCL>insert /*+ APPEND */ into t select * from big_table;
已创建100000行。
已用时间: 00: 00: 00.45
scott@ORCL>@D:\app\Administrator\product\11.2.0\mystat2
NAME V DIFF
---------------------------------------------------------------- ---------- ----------------
redo size 39980616 39,973,040
redo size for lost write detection 0 -7,576
redo size for direct writes 10072 2,496
已用时间: 00: 00: 00.00
scott@ORCL>set echo off4.2 redo生成和BEFORE/AFTER触发器
BEFORE触发器要额外的redo信息,即使它根本没有修改行中的任何值。
1. BEFORE或AFTER触发器不影响DELETE生成的redo。
2. 在Oracle9i Release 2 及以前版本中,BEFORE或AFTER触发器会使INSERT生成同样数量的额外redo。在Oracle 10g中,则不会生成任何额外的redo。
3.在Oracle9i Release 2及以前的所有版本中,UPDATE生成的redo只受BEFORE触发器的影响。AFTER触发器不会增加任何额外的redo。不过,在Oracle 10g中,情况又有所变化。具体表现为:
3.1 总的来讲,如果一个表没有触发器,对其更新期间生成的redo量总是比Oracle9i及以前版本中要少。看来这是Oracle着力解决的一个关键问题:对于触发器的表,要减少这种表更新所生成的redo量。
3.2 在Oracle 10g中,如果表有一个BEFORE触发器,则其更新期间生成的redo量比9i中更大。
3.3 如果表有AFTER触发器,则更新所生成的redo量与9i中一样。
为了完成这个测试,我们要使用一个表T,定义如下:
create table t ( x int, y char(N), z date );但是,创建时N的大小是可变的。在这个例子中,将使用N=30、100、500、1,000和2,000来得到不同宽度的行。针对不同大小的Y列运行测试,再来分析结果。使用了一个很小的日志表来保存多次运行的结果:
scott@ORCL>create table log ( what varchar2(15), -- will be no trigger, after or before
2 op varchar2(10), -- will be insert/update or delete
3 rowsize int, -- will be the size of Y
4 redo_size int, -- will be the redo generated
5 rowcnt int ) -- will be the count of rows affected
6 ;
表已创建。这里使用以下DO_WORK存储过程来生成事务,并记录所生成的redo。子过程REPORT是一个本地过程(只在DO_WORK过程中可见),它只是在屏幕上报告发生了什么,并把结果保存到LOG表中:
scott@ORCL>create or replace procedure do_work( p_what in varchar2 )
2 as
3 l_redo_size number;
4 l_cnt number := 200;
5
6 procedure report( l_op in varchar2 )
7 is
8 begin
9 select v$mystat.value-l_redo_size
10 into l_redo_size
11 from v$mystat, v$statname
12 where v$mystat.statistic# = v$statname.statistic#
13 and v$statname.name = 'redo size';
14
15 dbms_output.put_line(l_op || ' redo size = ' || l_redo_size ||
16 ' rows = ' || l_cnt || ' ' ||
17 to_char(l_redo_size/l_cnt,'99,999.9') ||
18 ' bytes/row' );
19 insert into log
20 select p_what, l_op, data_length, l_redo_size, l_cnt
21 from user_tab_columns
22 where table_name = 'T'
23 and column_name = 'Y';
24 end;
25
26 procedure set_redo_size
27 as
28 begin
29 select v$mystat.value
30 into l_redo_size
31 from v$mystat, v$statname
32 where v$mystat.statistic# = v$statname.statistic#
33 and v$statname.name = 'redo size';
34 end;
35
36 begin
37 set_redo_size;
38 insert into t
39 select object_id, object_name, created
40 from all_objects
41 where rownum <= l_cnt;
42 l_cnt := sql%rowcount;
43 commit;
44 report('insert');
45
46 set_redo_size;
47 update t set y=lower(y);
48 l_cnt := sql%rowcount;
49 commit;
50 report('update');
51
52 set_redo_size;
53 delete from t;
54 l_cnt := sql%rowcount;
55 commit;
56 report('delete');
57 end;
58 /
过程已创建。下面将Y列的宽度设置为2,000,然后运行以下脚本来测试3种场景:没有触发器、有BEFORE触发器,以及有AFTER触发器。
scott@ORCL>alter table t modify y char(2000);
表已更改。
scott@ORCL>exec do_work('no trigger');
insert redo size = 474996 rows = 200 2,375.0 bytes/row
update redo size = 1593920 rows = 200 7,969.6 bytes/row
delete redo size = 472872 rows = 200 2,364.4 bytes/row
PL/SQL 过程已成功完成。
scott@ORCL>create or replace trigger before_insert_update_delete
2 before insert or update or delete on T for each row
3 begin
4 null;
5 end;
6 /
触发器已创建
scott@ORCL>truncate table t;
表被截断。
scott@ORCL>exec do_work('before trigger');
insert redo size = 470580 rows = 200 2,352.9 bytes/row
update redo size = 894620 rows = 200 4,473.1 bytes/row
delete redo size = 472528 rows = 200 2,362.6 bytes/row
PL/SQL 过程已成功完成。
scott@ORCL>drop trigger before_insert_update_delete;
触发器已删除。
scott@ORCL>create or replace trigger after_insert_update_delete
2 after insert or update or delete on T
3 for each row
4 begin
5 null;
6 end;
7 /
触发器已创建
scott@ORCL>truncate table t;
表被截断。
scott@ORCL>exec do_work( 'after trigger' );
insert redo size = 501564 rows = 200 2,507.8 bytes/row
update redo size = 854880 rows = 200 4,274.4 bytes/row
delete redo size = 472836 rows = 200 2,364.2 bytes/row
PL/SQL 过程已成功完成。
前面的输出是在把Y大小设置为2,000字节时运行脚本所得到的。完成所有运行后,就能查询LOG表,并看到以下结果:
scott@ORCL>break on op skip 1
scott@ORCL>set numformat 999,999
scott@ORCL>select op, rowsize, no_trig,
2 before_trig-no_trig, after_trig-no_trig
3 from
4 ( select op, rowsize,
5 sum(decode( what, 'no trigger', redo_size/rowcnt,0 ) ) no_trig,
6 sum(decode( what, 'before trigger', redo_size/rowcnt, 0 ) ) before_trig,
7 sum(decode( what, 'after trigger', redo_size/rowcnt, 0 ) ) after_trig
8 from log
9 group by op, rowsize
10 )
11 order by op, rowsize
12 /
OP ROWSIZE NO_TRIG BEFORE_TRIG-NO_TRIG AFTER_TRIG-NO_TRIG
---------- -------- -------- ------------------- ------------------
delete 2,000 2,364 -2 -0
insert 2,000 2,375 -22 133
update 2,000 7,970 -3,497 -3,695
日志模式(ARCHIVELOG和NOARCHIVELOG模式)不会影响这些结果,这两种模式得到的结果数一样。
触发器对redo生成的影响
DML操作 AFTER触发器 BEFORE触发器
(10g) (10g)
DELETE 不影响 不影响
INSERT 常量redo 常量redo
UPDATE 增加redo 增加redo
现在你应该知道怎么来估计redo量:
1. 估计你的“事务”大小(你要修改多少数据)。
2. 在要修改的数据量基础上再加10%~20%的开销,具体增加多大的开销取决于你要修改的行数。修改行越多,增加的开销就越小。
3. 对于UPDATE,要把这个估计值加倍。
在大多数情况下,这将是一个很好的估计。UPDATE的估计值加倍只是一个猜测,实际上这取决于你修改了多少数据。之所以加倍,是因为在此假设要取一个X字节的行,并把它更新(UPDATE)为另一个X字节的行。如果你取一个小行(数据量较少的行),要把它更新为一个大行(数据量较多的行),就不用对这个值加倍(这更像是一个INSERT)。如果取一个大行,而把它更新为一个小行,也不用对这个值加倍(这更像是一个DELETE)。加倍只是一种“最坏情况”,因为许多选项和特性会对此产生影响,例如,存在索引或者没有索引也会影响这个底线。维护索引结构所必须的工作量对不同的UPDATE来说是不同的,此外还有一些影响因素。除了前面所述的固定开销外,还必须把触发器的副作用考虑在内。另外要考虑到Oracle为你执行的隐式操作(如外键上的ON DELETE CASCADE设置)。有了这些考虑,你就能适当地估计redo量以便调整事务大小以及实现性能优化。
4.3 能关掉重做日志生成吗
不能。因为重做日志对于数据库至关重要;它不是开销,不是浪费。重做日志对你来说确确实实必不可少。这是无法改变的事实,也是数据库采用的工作方式。如果你真的“关闭了redo”,那么磁盘驱动器的任何暂时失败、掉电或每个软件崩溃都会导致整个数据库不可用,而且不可恢复。有些情况下 执行某些操作时确实可以不生成重做日志。
4.3.1 在SQL中设置NOLOGGING
有些SQL语句和操作支持使用NOLOGGING子句。这并不是说:这个对象的所有操作在执行时都不生成重做日志,而是说有些特定操作生成的redo会比平常(即不使用NOLOGGING子句时)少得多。只是说“redo”少得多,而不是“完全没有redo“。所有操作都会生成一些redo——不论日志模式是什么,所有数据字典操作都会计入日志。只不过使用NOLOGGING子句后,生成的redo量可能会显著减少。下面是使用NOLOGGING子句的一个例子。
为此先在采用ARCHIVELOG模式运行的一个数据库中运行以下命令:
sys@ORCL>select log_mode from v$database;
LOG_MODE
------------
ARCHIVELOG
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat "redo size"
NAME VALUE
---------------------------------------------------------------- ----------
redo size 0
redo size for lost write detection 0
redo size for direct writes 0
sys@ORCL>set echo off
sys@ORCL>create table t
2 as
3 select * from all_objects;
表已创建。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat2
NAME V DIFF
---------------------------------------------------------------- ---------- ----
------------
redo size 8535120 8,535,120
redo size for lost write detection 0 0
redo size for direct writes 8442060 8,442,060
sys@ORCL>set echo off这个CREATE TABLE生成了大约8.5MB的redo信息。接下来删除这个表,再重建,不过这一次采用NOLOGGING模式:
sys@ORCL>drop table t;
表已删除。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat "redo size"
NAME VALUE
---------------------------------------------------------------- ----------
redo size 8578096
redo size for lost write detection 0
redo size for direct writes 8442060
sys@ORCL>set echo off
sys@ORCL>create table t
2 NOLOGGING
3 as
4 select * from all_objects;
表已创建。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat2
NAME V DIFF
---------------------------------------------------------------- ---------- ----------------
redo size 8663676 221,616
redo size for lost write detection 0 -8,442,060
redo size for direct writes 8443828 1,768
sys@ORCL>set echo off这一次,只生成了221KB的redo信息。
可以看到,差距很悬殊:原来有8.5MB的redo,现在只有221KB。8.5MB是实际的表数据本身;现在它直接写至磁盘,对此没有生成重做日志。
如果对一个NOARCHIVELOG模式的数据库运行这个测试,就看不到什么差别。在NOARCHIVELOG模式的数据库中,除了数据字典的修改外,CREATE TABLE不会记录日志。如果你想在NOARCHIVELOG模式的数据库上看到差别,可以把对表T的DROP TABLE和CREATE TABLE换成DROP INDEX和CREATE INDEX。默认情况下,不论数据库以何种模式运行,这些操作都会生成日志。从这个例子可以得出一个很有意义的提示:要按生产环境中所采用的模式来测试你的系统,因为不同的模式可能导致不同的行为。你的生产系统可能采用AUCHIVELOG模式运行;倘若你执行的大量操作在ARCHIVELOG模式下会生成redo,而在NOARCHIVELOG模式下不会生成redo,你肯定想在测试时就发现这一点!
必须非常谨慎地使用NOLOGGING模式,而且要与负责备份和恢复的人沟通之后才能使用。下面假设你创建了一个非日志模式的表,并作为应用的一部分(例如,升级脚本中使用了CREATE TABLE AS SELECT NOLOGGING)。用户白天修改了这个表。那天晚上,表所在的磁盘出了故障。“没关系“,DBA说”数据库在用ARCHIVELOG模式运行,我们可以执行介质恢复“。不过问题是,现在无法从归档重做日志恢复最初创建的表,因为根本没有生成日志,使得出现介质失败后DBA无法全面地恢复数据库。这个表将无法恢复。
关于NOLOGGING操作,需要注意以下几点:
1. 事实上,还是会生成一定数量的redo。这些redo的作用是保护数据字典。这是不可避免的。与以前(不使用NOLOGGING)相比,尽管生成的redo量要少多了,但是确实会有一些redo。
2. NOLOGGING不能避免所有后续操作生成redo。在前面的例子中,我创建的并非不生成日志的表。只是创建表(CREATE TABLE)这一个操作没有生成日志。所有后续的“正常“操作(如INSERT、UPDATE和DELETE)还是会生成日志。其他特殊的操作(如使用SQL*Loader的直接路径加载,或使用INSERT /*+ APPEND */语法的直接路径插入)不生成日志(除非你ALTER这个表,再次启用完全的日志模式)。不过,一般来说,应用对这个表执行的操作都会生成日志。
3. 在一个ARCHIVELOG模式的数据库上执行NOLOGGING操作后,必须尽快为受影响的数据文件建立一个新的基准备份,从而避免由于介质失败而丢失对这些对象的后续修改。实际上,我们并不会丢失后来做出的修改,因为这些修改确实在重做日志中;我们真正丢失的只是要应用这些修改的数据(即最初的数据)。
4.3.2 在索引上设置NOLOGGING
使用NOLOGGING选项有两种方法。1. NOLOGGING关键字潜在SQL命令中。2. 在段(索引或表)上设置NOLOGGING属性,从而隐式地采用NOLOGGING模式来执行操作。例如,可以把一个索引或表修改为默认采用NOLOGGING模式。这说明,以后重建这个索引不会生成日志(其他索引和表本身可能还会生成redo,但是这个索引不会):
sys@ORCL>create index t_idx on t(object_name);
索引已创建。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat "redo size"
NAME VALUE
---------------------------------------------------------------- ----------
redo size 11644980
redo size for lost write detection 0
redo size for direct writes 11389496
sys@ORCL>set echo offsys@ORCL>alter index t_idx rebuild;
索引已更改。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat2
NAME V DIFF
---------------------------------------------------------------- ---------- ----------------
redo size 14635016 3,245,520
redo size for lost write detection 0 -11,389,496
redo size for direct writes 14335208 2,945,712
sys@ORCL>set echo off这个索引采用LOGGING模式(默认),重建这个索引会生成 3.2MB 的重做日志。不过,可以如下修改这个索引:
sys@ORCL>alter index t_idx nologging;
索引已更改。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat "redo size"
NAME VALUE
---------------------------------------------------------------- ----------
redo size 14637616
redo size for lost write detection 0
redo size for direct writes 14335208
sys@ORCL>set echo off
sys@ORCL>alter index t_idx rebuild;
索引已更改。
sys@ORCL>@D:\app\Administrator\product\11.2.0\mystat2
NAME V DIFF
---------------------------------------------------------------- ---------- ----------------
redo size 14685008 349,800
redo size for lost write detection 0 -14,335,208
redo size for direct writes 14340044 4,836
sys@ORCL>set echo off现在它只生成349KB的redo。但是,现在这个索引没有得到保护(unprotected),如果它所在的数据文件失败而必须从一个备份恢复,我们就会丢失这个索引数据。现在索引是不可恢复的,所以需要做一个备份。或者,DBA也可以干脆创建索引,因为完全可以从表数据直接创建索引。
4.3.3 NOLOGGING小结
可以采用NOLOGGING模式执行以下操作:
1. 索引的创建和ALTER(重建)。
2. 表的批量INSERT(通过/*+APPEND */提示使用“直接路径插入“。或采用SQL*Loader直接路径加载)。表数据不生成redo,但是所有索引修改会生成redo,但是所有索引修改会生成redo(尽管表不生成日志,但这个表上的索引却会生成redo!)。
3. LOB操作(对大对象的更新不必生成日志)。
4. 通过CREATE TABLE AS SELECT创建表。
5. 各种ALTER TABLE操作,如MOVE和SPLIT。
在一个ARCHIVELOG模式的数据库上,如果NOLOGGING使用得当,可以加快许多操作的速度,因为它能显著减少生成的重做日志量。假设你有一个表,需要从一个表空间移到另一个表空间。可以适当地调度这个操作,让它在备份之后紧接着发生,这样就能把表ALTER为NOLOGGING模式,移到表,创建索引(也不生成日志),然后再把表ALTER回LOGGING模式。现在,原先需要X小时才能完成的操作可能只需要X/2小时。要想适当地使用这个特性,需要DBA的参与,或者必须与负责数据库备份和恢复(或任何备用数据库)的人沟通。
4.4 为什么不能分配一个新日志?
Thread 1 cannot allocate new log, sequence 1466
Checkpoint not complete
Current log# 3 seq# 1465 mem# 0: /home/ora10g/oradata/ora10g/redo03.log警告消息中也可能指出Archival required而不是Checkpoint not complete,但是效果几乎都一样。如果数据库试图重用一个在线重做日志文件,但是发现做不到,就会把这样一条消息写到服务器上的alert.log中。如果DBWR还没有完成重做日志所保护数据的检查点(checkpointing),或者ARCH还没有把重做日志文件复制到归档目标,就会发生这种情况。对最终用户来说,这个时间点上数据库实际上停止了。它会原地不动。DBWR或ARCH将得到最大的优先级以将redo块刷新输出的磁盘。完成了检查点或归档之后,一切又回归正常。数据库之所以暂停用户的活动,这是因为此时已经没地方记录用户所做的修改了。Oracle试图重用一个在线重做日志文件,但是由于归档进程尚未完成这个文件的复制(Archival required),所以Oracle必须等待(相应地,最终用户也必须等待),直到能安全地重用这个重做日志文件为止。
如果你看到会话因为一个“日志文件切换”、“日志缓冲区空间”或“日志文件切换检查点或归档未完成”等待了很长时间,就很可能遇到了这个问题。如果日志文件大小不合适,或者DBWR和ARCH太慢(需要由DBA或系统管理员调优),在漫长的数据库修改期间,你就会注意到这个问题。“起始”数据库一般会把重做日志的大小定得太小,不适用较大的工作量(包括数据字典本身的起始数据库构建)。一旦启动数据库的加载,你会注意到,前1,000行进行得很快,然后就会呈喷射状进行:1,000进行得很快,然后暂停,接下来又进行得很快,然后又暂停,如此等等。这些就是很明确的提示,说明你遭遇了这个问题。
要解决这个问题,有几种做法:
1. 让DBWR更快一些。让你的DBA对DBWR调优,为此可以启用ASYNC I/O、使用DBWR I/O从属进程,或者使用多个DBWR进程。看看系统产生的I/O,查看是否有一个磁盘(或一组磁盘)“太热”,相应地需要将数据散布开。这个建议对ARCH也适用。这种做法的好处是,你不用付出什么代价就能有所收获,性能会提高,而且不必修改任何逻辑/结构/代码。
2. 增加更多重做日志文件。在某些情况下,这会延迟Checkpoint not complete的出现,而且过一段时间后,可以把Checkpoint not complete延迟得足够长,使得这个错误可能根本不会出现(因为你给DBWR留出了足够的活动空间来建立检查点)。这个方法也同样适用于Archival required消息。这种方法的好处是可以消除系统中的“暂停”。其缺点是会消耗更多的磁盘空间。
3. 重新创建更大的日志文件。这会扩大填写在线重做日志与重用这个在线重做日志文件之间的时间间隔。如果重做日志文件的使用呈“喷射状”,这种方法同样适用于Archival required消息。倘若一段时间内会大量生成日志(如每晚加载、批处理等),其后一段数据却相当平静,如果有更大的在线重做日志,就能让ARCH在平静的期间有足够的时间“赶上来”。这种方法的优缺点与前面增加更多文件的方法是一样的。另外,它可能会延迟检查点的发生,由于(至少)每个日志切换都会发生检查点,而现在日志切换间隔会更大。
4. 让检查点发生得更频繁、更连续。可以使用一个更小的块缓冲区缓存(不太好),或者使用诸如FAST_START_MTTR_TARGET、LOG_CHECKPOINT_INTERVAL和LOG_CHECKPOINT_TIMEOUT之类的参数设置。这会强制DBWR更 频繁地刷新输出脏块。这种方法的好处是,失败恢复的时间会减少。在线重做日志中应用的工作肯定更少。其缺点是,如果经常修改块,可能会更频繁地写至磁盘。 缓冲区缓存本该更有效的,但由于频繁地写磁盘,会导致缓冲区缓存不能充分发挥作用,这可能会影响块清除机制。
4.5 块清除
块清除(block cleanout),即生成所修改数据库块上与“锁定”有关的信息。
数据锁实际上是数据的属性,存储在块首部。下一次访问这个块时,可能必须“清理”这个块,要将这些事务信息删除。这个动作会生成redo,并导致变脏(原本并不脏,因为数据本身没有修改),这说明一个简单的SELECT有可能生成redo,而且可能导致完成下一个检查点时将大量的块写至磁盘。不过,在大多数正常的情况下,这是不会发生的。如果系统中主要是小型或中型事务(OLTP),或者数据仓库会执行直接路径加载或使用DBMS_STATS在加载操作后分析表,你会发现块通常已经得到“清理”。COMMIT时处理的步骤之一是:如果块还在SGA中,就要再次访问这些块,如果可以访问(没有别人在修改这些块),则对这些块完成清理。这个活动称为提交清除(commit cleanout),即清除已修改块上事务信息。最理想的是,COMMIT可以完成块清除,这样后面的SELECT(读)就不必再清理了。只有块的UPDATE才会真正清除残余的事务信息,由于UPDATE已经在生成redo,所用注意不到这个清除工作。
可以强制清除不发生来观察它的副作用,并了解提交清除是怎么工作的。在与我们的事务相关的提交列表中,Oracle会记录已修改的块列表。这些列表都有20个块,Oracle会根据需要分配多个这样的列表,直至达到某个临界点。如果我们修改的块加起来超过了块缓冲区缓存大小的10%,Oracle会停止为我们分配新的列表。例如,如果缓冲区缓存设置为可以缓存3,000个块,Oracle会为我们维护最多300个块(3,000的10%)。COMMIT时,Oracle会处理这些包含20个块指针的列表,如果块仍可用,它会执行一个很快的清理。所以,只要我们修改的块数没有超过缓存中总块数的10%,而且块仍在缓存中并且是可用的,Oracle就会在COMMIT时清理这些块。否则,它只会将其忽略(也就是说不清理)。
在下表中填入了5000行,并COMMIT。测量到此为止生成的redo量。然后运行一个SELECT,它会访问每个块,最后测量这个SELECT生成的redo量。
SELECT会生成redo。不仅如此,它还会把这些修改块“弄脏”,导致DBWR再次将块写入磁盘。这是因为块清除的缘故。接下来,我会再一次运行SELECT,可以看到这回没有生成redo。这在意料之中,因为此时块都已经“干净”了。
sys@ORCL>create table t
2 ( x char(2000),
3 y char(2000),
4 z char(2000)
5 )
6 /
表已创建。
sys@ORCL>insert into t
2 select 'x', 'y', 'z'
3 from all_objects
4 where rownum <= 50000;
已创建50000行。
统计信息
----------------------------------------------------------
4152 recursive calls
233091 db block gets
64054 consistent gets
564 physical reads
326484496 redo size
1137 bytes sent via SQL*Net to client
1317 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
31 sorts (memory)
0 sorts (disk)
50000 rows processed
sys@ORCL>commit;
提交完成。上述表 每个块中包含一行(我的数据库中块大小为8KB)。
scott@ORCL> show parameter db_block_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_block_size integer 8192现在测量读数据是生成的redo量:
sys@ORCL>select *
2 from t;
已选择50000行。
统计信息
----------------------------------------------------------
5 recursive calls
0 db block gets
100076 consistent gets
50116 physical reads
4004 redo size
302570630 bytes sent via SQL*Net to client
37182 bytes received via SQL*Net from client
3335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
50000 rows processed可见,这个SELECT在处理期间生成了大约 4KB 的redo。这表示对T进行全表扫描时修改了 4KB的块首部。DBWR会在将来某个时间把这些已修改的块写回到磁盘上。现在,如果再次运行这个查询:
sys@ORCL>select *
2 from t;
已选择50000行。
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
99951 consistent gets
50001 physical reads
0 redo size
302570630 bytes sent via SQL*Net to client
37182 bytes received via SQL*Net from client
3335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
50000 rows processed可以看到,这一次没有生成redo,块都是干净的。
如果把缓冲区缓存设置为能保存至少50,000个块,再次运行前面的例子。会发现,无论哪一个SELECT,生成的redo都很少甚至没有——我们不必在其中任何一个SELECT语句期间清理脏块。这是因为,我们修改的5000个块完全可以在缓冲区缓存的10%中放下,而且我们是独家用户。别人不会动数据,不会有人导致我们的数据刷新输出到磁盘,也没有人在访问这些块。在实际系统中,有些情况下,至少某些块不会进行清除,这是正常的。
如果执行一个大的INSERT(如上所述)、UPDATE或DELETE,这种块清除行为的影响最大,它会影响数据库中的许多块(缓存中10%以上的块都会完成块清除)。在此之后,第一个“接触”块的查询会生成少量的redo,并把块弄脏,如果DBWR已经将块刷新输出或者实例已经关闭,可能就会因为这个查询而导致重写这些块,并完全清理缓冲区缓存。如果Oracle不对块完成这种延迟清除,那么COMMIT的处理就会与事务本身一样长。COMMIT必须重新访问每一个块,可能还要从磁盘将块再次读入(它们可能已经刷新输出)。
假设你更新(UPDATE)了大量数据,然后COMMIT。现在对这些数据运行一个查询来验证结果。看上去查询生成了大量写I/O和redo。
在一个OLTP系统中,可能从来不会看到这种情况发生,因为OLTP系统的特点是事务都很短小,只会影响为数不多的一些块。根据设计,所有或者大多数事务都短而精。只是修改几个块,而且这些块都会得到清理。在一个数据仓库中,如果加载之后要对数据执行大量UPDATE,就要把块清除作为设计中要考虑的一个因素。有些操作会在“干净”的块上创建数据。例如,CREATE TABLE AS SELECT、直接路径加载的数据以及直接路径插入的数据都会创建“干净”的块。UPDATE、正常的INSERT或DELETE创建的块则可能需要在第一次读时完成块清除。如果你有如下的处理,就会受到块清除的影响:
1. 将大量新数据批量加载到数据仓库中;
2. 在刚刚加载的所有数据上运行UPDATE(产生需要清理的块);
3. 让人们查询这些数据。
如果块需要清理,第一接触这个数据的查询将带来一些额外的处理。
应该在UPDATE之 后自己主动地“接触”数据。你刚刚加载或修改了大量的数据;现在至少需要分析这些数据。可能要自行运行一些报告来验证数据已经加载。这些报告会完成块清 除,这样下一个查询就不必再做这个工作了。更好的做法是:由于你刚刚批量加载了数据,现在需要以某种方式刷新统计。通过运行DBMS_STATS实用程序来收集统计,就能很好地清理所有块,这是因为它只是使用SQL来查询信息,会在查询当中很自然地完成块清除。
4.6 日志竞争
如果你遭遇到日志竞争,可能会看到对“日志文件同步”事件的等待时间相当长,另外Statspack报告的“日志文件并行写”事件中写次数(写I/O数)可能很大。如果观察到这种情况,就说明你遇到了重做日志的竞争;重做日志写得不够快。发生这种情况可能有许多原因。其中一个应用原因是:提交得太过频繁,例如在重复执行INSERT的循环中反复提交。如果提交得太频繁,这不仅是不好的编程实践,肯定还会引入大量日志文件同步等待。假设你的所有事务都有适当的大小(完全遵从业务规则的要求,而没有过于频繁地提交),但还是看到了这种日志文件等待,这就有其他原因了。其中最常见的原因如下:
1. redo放在一个慢速设备上:磁盘表现不佳。
2. redo与其他频繁访问的文件放在同一个设备上。redo设计为要采用顺序写,而且要放在专用的设备上。如果系统的其他组件(甚至其他Oracle组件)试图与LGWR同时读写这个设备,你就会遭遇某种程度的竞争。在此,只要有可能,你就会希望确保LGWR拥有这些设备的独占访问权限。
3. 已缓冲方式装载日志设备。你在使用一个“cooked”文件系统(而不是RAW磁盘)。操作系统在缓冲数据,而数据库也在缓冲数据(重做日志缓冲区)。这种双缓冲会让速度慢下来。如果可能,应该以一种“直接”方式了装载设备。具体操作依据操作系统和设备的不同而有所变化,但一般都可以直接装载。
4. redo采用了一种慢速技术,如RAID-5。RAID-5很合适读,但是用于写时表现则很差。COMMIT期间 我们必须等待LGWR以确保数据写到磁盘上。
只有有可能,实际上你会希望至少有5个专用设备来记录日志,最好还有第6个设备来镜像归档日志。由于当前往往使用9GB、20GB、36GB、200GB、300GB和更大的磁盘,要想拥有这么多专用设备变得更加困难。但是如果能留出4块你能找到的最小、最快的磁盘,再有一个或两个大磁盘,就可以很好地促进LGWR和ARCH的工作。
在线重做日志文件是一组Oracle文件,最适合使用RAW磁盘(原始磁盘)。在线重做日志文件不用备份,所以将在线重做日志文件放在RAW分区上而不是cooked文件系统上,这不会影响你的任何备份脚本。ARCH总能把RAW日志转变为cooked文件系统文件(不能使用一个RAW设备来建立归档)。
4.7 临时表和redo/undo
临时表不会为它们的块生成redo。因此,对临时表的操作不是“可恢复的”。修改临时表中的一个块时,不会将这个修改记录到重做日志文件中。不过,临时表确实会生成undo,而且这个undo会计入日志。因此,临时表也会生成一些redo。这是因为你能回滚到事务中的一个SAVEPOINT。可以擦除对临时表的后50个INSERT,而只留下前50个。临时表可以有约束,正常表有的一切临时表都可以有。可能有一条INSERT语句要向临时表中插入500行,但插入到第500行时失败了,这就要求回滚这条语句。由于临时表一般表现得就像“正常”表一样,所以临时表必须生成undo。由于undo数据必须建立日志,因此临时表会为所生成的undo生成一些重做日志。
在临时表上运行的SQL语句主要是INSERT和SELECT。幸运的是,INSERT只生成极少的undo(需要把块恢复为插入前的“没有”状态,而存储“没有”不需要多少空间),另外SELECT根本不生成undo。
我建立了一个小测试来演示使用临时表时生成的redo量,同时这也暗示了临时表生成的undo量,因为对于临时表,只会为undo生成日志。为了说明这一点,我采用了配置相同的“永久”表和“临时”表,然后对各个表执行相同的操作,测量每次生成的redo量。这里使用的表如下:
scott@ORCL>create table perm
2 ( x char(2000) ,
3 y char(2000) ,
4 z char(2000) )
5 /
表已创建。
scott@ORCL>create global temporary table temp
2 ( x char(2000) ,
3 y char(2000) ,
4 z char(2000) )
5 on commit preserve rows
6 /
表已创建。建立了一个小的存储过程,它能执行任意的SQL,并报告SQL生成的redo量。
使用这个例程分别在临时表和永久表上执行INSERT、UPDATE和DELETE:
scott@ORCL>create or replace procedure do_sql( p_sql in varchar2 )
2 as
3 l_start_redo number;
4 l_redo number;
5 begin
6 select v$mystat.value
7 into l_start_redo
8 from v$mystat, v$statname
9 where v$mystat.statistic# = v$statname.statistic#
10 and v$statname.name = 'redo size';
11
12 execute immediate p_sql;
13 commit;
14
15 select v$mystat.value-l_start_redo
16 into l_redo
17 from v$mystat, v$statname
18 where v$mystat.statistic# = v$statname.statistic#
19 and v$statname.name = 'redo size';
20
21 dbms_output.put_line
22 ( to_char(l_redo,'9,999,999') ||' bytes of redo generated for "' ||
23 substr( replace( p_sql, chr(10), ' '), 1, 25 ) || '"...' );
24 end;
25 /
过程已创建。接下来,对PERM表和TEMP表运行同样的INSERT、UPDATE和DELETE:
scott@ORCL>set serveroutput on format wrapped
scott@ORCL>begin
2 do_sql( 'insert into perm
3 select 1,1,1
4 from all_objects
5 where rownum <= 500' );
6
7 do_sql( 'insert into temp
8 select 1,1,1
9 from all_objects
10 where rownum <= 500' );
11 dbms_output.new_line;
12
13 do_sql( 'update perm set x = 2' );
14 do_sql( 'update temp set x = 2' );
15 dbms_output.new_line;
16
17 do_sql( 'delete from perm' );
18 do_sql( 'delete from temp' );
19 end;
20 /
3,293,240 bytes of redo generated for "insert into perm select"...
66,432 bytes of redo generated for "insert into temp select"...
2,182,288 bytes of redo generated for "update perm set x = 2"...
1,100,296 bytes of redo generated for "update temp set x = 2"...
3,215,200 bytes of redo generated for "delete from perm"...
3,215,328 bytes of redo generated for "delete from temp"...
PL/SQL 过程已成功完成。
可以看到:
1. 对“实际”表(永久表)的INSERT生成了大量redo。而对临时表几乎没有生成任何redo。对临时表的INSERT只会生成很少的undo数据,而且对于临时表只会为undo数据建立日志。
2. 实际表的UPDATE生成的redo大约是临时表更新所生成redo的两倍。必须保存UPDATE的大约一半(即“前映像”)。对于临时表来说,不必保存“后映像”(redo)。
3. DELETE需要几乎相同的redo空间。因为对DELETE的undo很大,而对已修改块的redo很小。因此,对临时表的DELETE与对永久表的DELETE几乎相同。
关于临时表上的DML活动,可以得出以下一般结论:
1. INSERT会生成很少甚至不生成undo/redo活动
2. DELETE在临时表上生成的redo与正常表上生成的redo同样多
3. 临时表的UPDATE会生成正常表UPDATE一半的redo
对于最后一个结论,需要指出有一些例外情况。例如,如果我用2,000字节的数据UPDATE(更新)完全为NULL的一列,生成的undo数据就非常少。这个UPDATE表现得就像是INSERT。另一方面,如果我把有2,000字节数据的一列UPDATE为全NULL,对redo生成来说,这就表现得像是DELETE。平均来讲,可以这样认为:临时表UPDATE与实际表UPDATE生成的undo/redo相比,前者是后者的50%。
一般来讲,关于创建的redo量有一个常识。如果你完成的操作导致创建undo数据,则可以确定逆向完成这个操作(撤销操作)的难易程度。如果INSERT2,000字节,逆向操作就很容易,只需回退到无字节即可。如果删除了(DELETE)2,000字节,逆向操作就是要插入2,000字节。在这种情况下,redo量就很大。
避免删除临时表。可以使用TRUNCATE,或者只是让临时表在COMMIT之后或会话终止时自动置空。执行方法不会生成undo,相应地也不会生成redo。你可能会尽量避免更新临时表,除非由于某种原因必须这样做。把临时表主要用于插入(INSERT)和选择(SELECT)。采用这种方式,就能更优地使用临时表不生成redo的特有能力。
5 分析undo
5.1 什么操作会生成最多和最少的undo?
如果存在索引(或者实际上表就是索引组织表),这将显著地影响生成的undo量,因为索引是一种复杂的数据结构,可能会生成相当多的undo信息。
一般来讲,INSERT生成的undo最少,因为Oracle为此需记录的只是要“删除”的一个rowid(行ID)。UPDATE一般排名第二(在大多数情况下)。对于UPDATE,只需记录修改的字节。一般只更新(UPDATE)了整个数据行中很少的一部分。因此,必须在undo中记录行的一小部分。一般来讲,DELETE生成的undo最多。对于DELETE,Oracle必须把整行的前映像记录到undo段中。INSERT只生成需要建立日志的很少的undo。UPDATE生成的undo量等于所修改数据的前映像大小,DELETE会生成整个数据集写至undo段。
与加索引列的更新相比,对一个未加索引的列进行更新不仅执行得更快,生成的undo也会好得多。例如,下面创建一个有两列的表,这两列包含相同的数据,但是其中一列加了索引:
scott@ORCL>create table t
2 as
3 select object_name unindexed,
4 object_name indexed
5 from all_objects
6 /
表已创建。
scott@ORCL>create index t_idx on t(indexed);
索引已创建。
scott@ORCL>exec dbms_stats.gather_table_stats(user,'T');
PL/SQL 过程已成功完成。下面更新这个表,首先,更新未加索引的列,然后更新加索引的列。我们需要一个新的V$查询来测量各种情况下生成的undo量。以下查询可以完成这个工作。它先从V$MYSTAT得到我们的会话ID(SID),在使用这个会话ID在V$SESSION视图中找到相应的会话记录,并获取事务地址(TADDR)。然后使用TADDR拉出(查出)我们的V$TRANSACTION记录(如果有),选择USED_UBLK列,即已用undo块的个数。由于我们目前不在一个事务中,这个查询现在应该返回0行:
scott@ORCL>select used_ublk
2 from v$transaction
3 where addr = (select taddr
4 from v$session
5 where sid = (select sid
6 from v$mystat
7 where rownum = 1 )
8 )
9 /
未选定行然后在每个UPDATE之后再使用这个查询:
scott@ORCL>update t set unindexed = lower(unindexed);
已更新71869行。
scott@ORCL>select used_ublk
2 from v$transaction
3 where addr = (select taddr
4 from v$session
5 where sid = (select sid
6 from v$mystat
7 where rownum = 1 )
8 )
9 /
USED_UBLK
----------
1229
scott@ORCL>commit;
提交完成。
scott@ORCL>select used_ublk
2 from v$transaction
3 where addr = (select taddr
4 from v$session
5 where sid = (select sid
6 from v$mystat
7 where rownum = 1 )
8 )
9 /
未选定行
这个UPDATE使用了1229个块存储其undo。提交会“解放”这些块,或者将其释放,所以如果再次对V$TRANSACTION运行这个查询,它还会显示no rows selected。
更新同样的数据时,不过这一次是加索引的列,会观察到下面的结果:
scott@ORCL>update t set indexed = lower(indexed);
已更新71869行。
scott@ORCL>select used_ublk
2 from v$transaction
3 where addr = (select taddr
4 from v$session
5 where sid = (select sid
6 from v$mystat
7 where rownum = 1 )
8 )
9 /
USED_UBLK
----------
2763
scott@ORCL>commit;
提交完成。
scott@ORCL>select used_ublk
2 from v$transaction
3 where addr = (select taddr
4 from v$session
5 where sid = (select sid
6 from v$mystat
7 where rownum = 1 )
8 )
9 /
未选定行更新加索引的列会生成 2倍多的undo。这是因为索引结构本身所固有的复杂性,而且我们更新了这个表中的每一行,移动了这个结构中的每一个索引键值。
5.2 ORA-01555:snapshot too old错误
导致这个错的一个原因:提交得太过频繁。
1. undo段太小,不足以在系统上执行工作。
2. 程序跨COMMIT获取(实际上这是前一点的一个变体)。
3. 块清除
前两点与Oracle的读一致性模型直接相关。查询的结果是预定的,在Oracle去获取第一行之前,结果就已经定好了。Oracle使用undo段来回滚自查询开始以来有修改的块,从而提供数据库的一致时间点“快照”。例如执行以下语句:
update t set x = 5 where x = 2;
insert into t select * from t where x = 2;
delete from t where x = 2;
select * from t where x = 2;执行每条语句时都会看到T的一个读一致视图以及X=2的行集,而不论数据库中还有哪些并发的活动。
所有“读”这个表的语句都利用了这种读一致性。在上面所示的例子中,UPDATE读这个表,找到X=2的行(然后UPDATE这些行)。INSERT也要读表,找到X=2的行,然后INSERT,等等。由于两个语句都使用了undo段,都是为了回滚失败的事务并提供读一致性,这就导致了ORA-01555错误。
前面列的第三项也会导致ORA-01555,因为它可能在只有一个会话的数据库中发生,而且这个会话并没有修改出现ORA-01555错误时所查询的表!
ORA-01555错误的几种解决方案,一般来说可以采用下面的方法:
1. 适当地设置参数UNDO_RETENTION(要大于执行运行时间最长的事务所需的时间)。可以用V$UNDOSTAT来确定长时间运行的查询的持续时间。另外,要确保磁盘上已经预留了足够的空间,使undo段能根据所请求的UNDO_RETENTION增大。
2. 使用手动undo管理时加大或增加更多的回滚段。这样在长时间运行的查询执行期间,覆盖undo数据的可能性就能降低。
3. 减少查询的运行时间(调优)。这样就能降低对undo段的需求,不需求太大的undo段。
4. 收集相关对象的统计信息。由于大批量的UPDATE或INSERT会导致块清除(block cleanout),所以需要在大批量UPDATE或大量加载之后以某种方式收集统计信息。
5.2.1 undo段确实太小
一种场景是:你的系统中事务很小。正因如此,只需要分配非常少的undo段空间。假如,假设存在以下情况:
? 每个事务平均生成8KB的undo。
? 平均每秒完成其中5个事务(每秒生成40KB的undo,每分钟生成2,400KB的undo)。
? 有一个生成1MB undo的事务平均每分钟出现一次。总的说来,每分钟会生成大约3.5MB的undo。
? 你为系统配置了15MB的undo。
处理事务时,相对于这个数据库的undo需求,这完全够了。undo段会回绕,平均每3~4分钟左右会重用一次undo段空间。
不过,在同样的环境中,可能有一些报告需求。其中一些查询需要运行相当长的时间,可能是5分钟。这就有问题了。如果这些查询需要执行5分钟,而且它们需要查询开始时的一个数据视图,你就极有可能遭遇ORA-01555错误。由于你的undo段会在这个查询执行期间回绕,要知道查询开始以来生成的一些undo信息已经没有了,这些信息已经被覆盖。如果你命中了一个块,而这个块几乎在查询开始的同时被修改,这个块的undo信息就会因为undo段回绕而丢掉,你将收到一个ORA-01555错误。
以下是一个小例子。假设我们有一个表,其中有块1、2、3、…、1,000,000。下表显示了可能出现的事件序列。
长时间运行的查询时间表
时间(分:秒) 动作
0:00 查询开始
0:01 另一个会话更新(UPDATE)块1,000,000。将块1,000,000的undo信息记录到某个undo段
0:01 这个UPDATE会话提交(COMMIT)。它生成的undo数据还在undo段中,但是倘若我们需要空间, 选择允许覆盖这个信息
1:00 我们的查询还在运行。现在更新到块200,000
1:01 进行了大量活动。现在已经生成了稍大于14MB的undo
3:00 查询还在兢兢业业地工作着。现在处理到块600,000左右
4:00 undo段开始回绕,并重用查询开始时(0:00)活动的空间。具体地讲,我们已经重用了原先0:01时刻 UPDATE 块1,000,000时所用的undo段空间
5:00 查询终于到了块1,000,000。它发现自查询开始以来这个块已经修改过。它找到undo段,试图发现对应这一块的undo来得到一个一致读。此时,它发现所需要的信息已经不存在了。这就产生了ORA-01555错误,查询失败
具体就是这样的。如果如此设置undo段大小,使得很有可能在执行查询期间重用这些undo段,而且查询要访问被修改的数据,那就也有可能不断地遭遇ORA-01555错误。此时必须把UNDO_RETENTION参数设置得高一些,让Oracle负责确定要保留多少undo段的大小,让它们更大一些(或者有更多的undo段)。你要配置足够的undo,在长时间运行的查询期间应当能够维持。在前面的例子中,只是针对修改数据的事务来确定系统undo段的大小,而忘记了还有考虑系统的其他组件。
倘若手动地管理undo段,undo段从来不会因为查询而扩大;只有INSERT、UPDATE和DELETE才会让undo段增长。只有当执行一个长时间运行的UPDATE事务时才会扩大手动回滚段。
为了演示这种效果,我们将创建一个非常小的undo表空间,并有一个生成许多小事务的会话,实际上这能确保这个undo表空间回绕,多次重用所分配的空间,而不论UNDO_RETENTION设置为多大,因为我们不允许undo表空间增长。使用这个undo段的会话将修改一个表T。它使用T的一个全表扫描,自顶向下地读表;在另一个会话中,执行一个查询,它通过一个索引读表T,这个查询会稍微有些随机地读表:先读第1行,然后是第1,000行,接下来是第500行,再后面是第20,001行,如此等等。这样一来,我们可能会非常随机地访问块,并在查询的处理期间多次访问块。这种情况下得到ORA-01555错误的机率几乎是100%。所以,在一个会话中首先执行以下命令:
scott@ORCL>create undo tablespace undo_small
2 datafile 'D:\app\Administrator\oradata\orcl\undosmall.dbf' size 2m
3 autoextend off
4 /
表空间已创建。
scott@ORCL>alter system set undo_tablespace = undo_small;
系统已更改。现在,建立表T来查询和修改。注意 在这个表中随机地对数据排序。CREATE TABLE AS SELECT力图按查询获取的顺序将行放在块中。我们的目的只是把行弄乱,使它们不至于认为地有某种顺序,从而得到随机的分布:
scott@ORCL>create table t
2 as
3 select *
4 from all_objects
5 order by dbms_random.random;
表已创建。
scott@ORCL>alter table t add constraint t_pk primary key(object_id)
2 /
表已更改。
scott@ORCL>exec dbms_stats.gather_table_stats( user, 'T', cascade=> true );
PL/SQL 过程已成功完成。现在可以执行修改了:
scott@ORCL>begin
2 for x in ( select rowid rid from t )
3 loop
4 update t set object_name = lower(object_name) where rowid = x.rid;
5 commit;
6 end loop;
7 end;
8 /在运行这个修改的同时,在另一个会话中运行一个查询。这个查询要读表T,并处理每个记录。获取下一个记录之前处理每个记录所花的时间大约为1/100秒(使用DBMS_LOCK.SLEEP(0.01)来模拟)。在查询中使用了FIRST_ROWS提示,使之使用前面创建的索引,从而通过索引(按OBJECT_ID排序)来读出表中的行。由于数据是随机地插入到表中的,我们可能会相当随机地查询表中的块。这个查询只运行几秒就会失败:
scott@ORCL>declare
2 cursor c is
3 select /*+ first_rows */ object_name
4 from t
5 order by object_id;
6
7 l_object_name t.object_name%type;
8 l_rowcnt number := 0;
9 begin
10 open c;
11 loop
12 fetch c into l_object_name;
13 exit when c%notfound;
14 dbms_lock.sleep( 0.01 );
15 l_rowcnt := l_rowcnt+1;
16 end loop;
17 close c;
18 exception
19 when others then
20 dbms_output.put_line( 'rows fetched = ' || l_rowcnt );
21 raise;
22 end;
23 /
rows fetched = 56
declare
*
第 1 行出现错误:
ORA-01555: 快照过旧: 回退段号 32 (名称为 "_SYSSMU32_4133326864$") 过小
ORA-06512: 在 line 21
可以看到,在遭遇ORA-01555:snapshot too old错误而失败之前,它只处理了56个记录。要修正这个错误,我们要保证做到两点:
1. 数据库中UNDO_RETENTION要设置得足够长,以保证这个读进程完成。这样数据库就能扩大undo表空间来保留足够的undo,使我们能够完成工作。
2. undo表空间可以增长,或者为之手动分配更多的磁盘空间。
对于这个例子,我认为这个长时间运行的进程需要大约600秒才能完成。我的UNDO_RETENTION设置为900(单位是秒,所以undo保持大约15分钟)。我修改了undo表空间的数据文件,使之一次扩大1MB,直到最大达到2GB:
scott@ORCL>column file_name new_val F
scott@ORCL>select file_name
2 from dba_data_files
3 where tablespace_name = 'UNDO_SMALL';
FILE_NAME
--------------------------------------------------------------------------------
D:\APP\ADMINISTRATOR\ORADATA\ORCL\UNDOSMALL.DBF
scott@ORCL>alter database
2 datafile '&F'
3 autoextend on
4 next 1m
5 maxsize 2048m;
原值 2: datafile '&F'
新值 2: datafile 'D:\APP\ADMINISTRATOR\ORADATA\ORCL\UNDOSMALL.DBF'
数据库已更改。再次并发地运行这些进程时,两个进程都能顺利完成。这一次undo表空间的数据文件扩大了,因为在此允许undo表空间扩大,而且根据我设置的undo保持时间可知:
scott@ORCL>select bytes/1024/1024
2 from dba_data_files
3 where tablespace_name = 'UNDO_SMALL';
BYTES/1024/1024
---------------
19因此,这里没有收到错误,我们成功地完成了工作,而且undo扩大得足够大,可以满足我们的需要。在这个例子中,之所以会得到错误只是因为我们通过索引来读表T,而且在全表上执行随机读。如果不是这样,而是执行全表扫描,在这个特例中很可能不会遇到ORA-01555错误。原因是SELECT和UPDATE都要对T执行全表扫描,而SELECT扫描很可能在UPDATE之前进行(SELECT只需要读,而UPDATE不仅要读还有更新,因此可能更慢一些)。如果执行随机读,SELECT就更有可能要读已修改的块(即块中的多行已经被UPDATE修改而且已经提交)。这就展示了ORA-01555的“阴险”,这个错误的出现取决于并发会话如何访问和管理底层表。
5.2.2 延迟的块清除
块清除是导致ORA-01555错误错误的原因,尽管很难完全杜绝,不过好在毕竟并不多见,因为可能出现块清除的情况不常发生。在块清除过程中,如果一个块已被修改,下一个会话访问这个块时,可能必须查看最 后一个修改这个块的事务是否还是活动的。一旦确定该事务不再活动,就会完成块清除,这样另一个会话访问这个块时就不必再历经同样的过程。要完成块清除,Oracle会从块首部确定前一个事务所用的undo段,然后确定从undo首部能不能看出这个块是否已经提交。
可以用以下两种方式完成这种确认。
一种方式是Oracle可以确定这个事务很久以前就已经提交,它在undo段事务表中的事务槽已经被覆盖。
另一种情况是COMMIT SCN还在undo段的事务表中,这说明事务只是稍早前刚提交,其事务槽尚未被覆盖。
要从一个延迟的块清除收到ORA-01555错误,以下条件都必须满足:
1. 首先做了一个修改并COMMIT,块没有自动清理(即没有自动完成“提交清除”,例如修改了太多的块,在SGA块缓冲区缓存的10%中放不下)。
2. 其他会话没有接触这些块,而且在我们这个“倒霉”的查询(稍后显示)命中这些块之前,任何会话都不会接触它们。
3. 开始一个长时间运行的查询。这个查询最后会读其中的一些块。这个查询从SCN t1开始,这就是读一致SCN,必须将数据回滚到这一点来得到读一致性。开始查询时,上述修改事务的事务条目还在undo段的事务表中。
4. 查询期间,系统中执行了多个提交。执行事务没有接触执行已修改的块。
5. 由于出现了大量的COMMIT,undo段中的事务表要回绕并重用事务槽。最重要的是,将循环地重用原来修改事务的事务条目。另外,系统重用了undo段的区段,以避免对undo段首部块本身的一致读。
6. 此外,由于提交太多,undo段中记录的最低SCN现在超过了t1(高于查询的读一致SCN)。
如果查询到达某个块,而这个块在查询开始之前已经修改并提交,就会遇到麻烦。正常情况下,会回到块所指的undo段,找到修改了这个块的事务的状态(换句话说,它会找到事务的COMMIT SCN)。如果这个COMMIT SCN小于t1,查询就可以使用这个块。如果该事务的COMMIT SCN大于t1,查询就必须回滚这个块。不过,问题是,在这种特殊的情况下,查询无法确定块的COMMIT SCN是大于还是小于t1。相应地,不清楚查询能否使用这个块映像。这就导致了ORA-01555错误。
为 了真正看到这种情况,我们将在一个表中创建多个需要清理的块。然后在这个表上打开一个游标,并允许对另外某个表完成许多小事务(不是那个刚更新并打开了游标的表)。最后尝试为该游标获取数据。现在,我们认为游标 应该能看到所有数据,因为我们是在打开游标之前完成并提交了表修改。倘若此时 得到ORA-01555错误,就说明存在前面所述的问题。要建立这个例子,我们将使用:
1. 2MB UNDO_SMALL undo 表空间。
2. 4MB的缓冲区缓存,足以放下大约500个块。这样我们就可以将一些脏块刷新输出到磁盘来观察这种现象。
scott@ORCL>create table big
2 as
3 select a.*, rpad('*',1000,'*') data
4 from all_objects a;
表已创建。
scott@ORCL>exec dbms_stats.gather_table_stats( user, 'BIG' );
PL/SQL 过程已成功完成。
由于使用了这么大的数据字段,每个块中大约有6~7行,所以这个表中有大量的块。接下来,我们创建将由多个小事务修改的小表:
scott@ORCL>create table small ( x int, y char(500) );
表已创建。
scott@ORCL>insert into small select rownum, 'x' from all_users;
已创建39行。
scott@ORCL>commit;
提交完成。
scott@ORCL>exec dbms_stats.gather_table_stats( user, 'SMALL' );
PL/SQL 过程已成功完成。下面把那个大表“弄脏”。由于undo表空间非常小,所以希望尽可能多地更新这个大表的块,同时生成尽可能少的undo。为此,将使用一个UPDATE语句来执行该任务。实质上讲,下面的子查询要找出每个块上的“第一个”行rowid。这个子查询会返回每一个数据库块的一个rowid(标识了这个块的一行)。我们将更新这一行,设置一个VARCHAR2(1)字段。这样我们就能更新表中的所有块(在这个例子中,块数大约比8,000稍多一点),缓冲区缓存中将会充斥着必须写出的脏块(现在只有500个块的空间)。仍然必须保证只能使用那个小undo表空间。为做到这一点,而且不超过undo表空间的容量,下面构造一个UPDATE语句,它只更新每个块上的“第一行”。ROW_NUMBER()内置分析函数是这个操作中使用的一个工具;它把数字1指派给表中的数据库块的“第1行”,在这个块上只会更新这一行:
scott@ORCL>update big
2 set temporary = temporary
3 where rowid in
4 (
5 select r
6 from (
7 select rowid r, row_number() over
8 (partition by dbms_rowid.rowid_block_number(rowid) order by rowid)rn
9 from big
10 )
11 where rn = 1
12 )
13 /
已更新11979行。
scott@ORCL>commit;
提交完成。现在我们知道磁盘上有大量脏块。我们已经写出了一些,但是没有足够的空间把它们都放下。接下来打开一个游标,但是尚未获取任何数据行。打开游标时,结果集是预定的,所以即使Oracle并没有具体处理一行数据,打开结果集这个动作本身就确定了“一致时间点”,即结果集必须相对于那个时间点一致。现在要获取刚刚更新并提交的数据,而且我们知道没有别人修改这个数据,现在应该能获取这些数据行而不需要如何undo。但是此时就会“冒出”延迟块清除。修改这些块的事务太新了,所以Oracle必须验证在我们开始之前这个事务是否已经提交,如果这个信息(也存储在undo表空间中)被覆盖,查询就会失败。以下打开了游标:
scott@ORCL>variable x refcursor
scott@ORCL>exec open :x for select * from big;
PL/SQL 过程已成功完成。
启动9个SQL*Plus会话
每个会话运行的脚本如下:
begin
for i in 1 .. 1000
loop
update small set y = i where x= &1;
commit;
end loop;
end;
/这样一来,就有了9个会话分别在一个循环中启动多个事务。我们观察到下面的结果:
ERROR:
ORA-01555: snapshot too old: rollback segment number 23 with name "_SYSSMU23$"
too small
no rows selected它需要许多条件,所有这些条件必须同时存在才会出现这种情况。首先要有需要清理的块,收集统计信息的DBMS_STATS调用就能消除这种块。尽管大批量的更新和大量加载是造成块清除最常见的理由,但是利用DBMS_STATS调用的话,这些操作就不再成为问题,因为在这种操作之后总要对表执行分析。大多数事务只会接触很少的块,而不到块缓冲区缓存的10%;因此,它们不会生成需要清理的块。万一你发现遭遇了这个问题,即选择(SELECT)一个表时(没有应用其他DML操作)出现了ORA-01555错误,能你可以试试以下解决方案:
1. 首先,保证使用的事务“大小适当”。确保没有不必要地过于频繁地提交。
2. 使用DBMS_STATS扫描相关的对象,加载之后完成这些对象的清理。由于块清除是极大量的UPDATE或INSERT造成的,所以很有必要这样做。
3. 允许undo表空间扩大,为之留出扩展的空间,并增加undo保持时间。这样在长时间运行查询期间,undo段事务表中的事务槽被覆盖的可能性就会降低。针对导致ORA-01555错误的另一个原因(undo段太小),也同样可以采用这个解决方案(这两个原因有紧密的关系;块清除问题就是因为处理查询期间遇到了undo段重用,而undo段大小正是重用undo段的一个根本原因)。实际上,如果把undo表空间设置为一次自动扩展1MB,而且undo保持时间为900秒,再运行前面的例子,对表BIG的查询就能成功地完成了。
4. 减少查询的运行时间(调优)。















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









