







第二篇隔了这么久,一个是因为有工作任务,第二个也是因为为了编译64位的hadoop2.7.1耽误了。到现在也不确定64位系统到底需不需要自己编译hadoop2,反正我编译了才安装成功的。
首先:先介绍环境虚拟机安装的VM12,系统是centOS6.5 ,hdoop2.7.1,JDK是1.7因为hadoop2官网测试了JDK1.6喝1.7都是稳定的,1.8应该也行但是此时官网暂时没测。
编译参照了:http://my.oschina.net/ordinance/blog/521931?fromerr=34qORjYs
安装参照了:http://blog.csdn.net/woshisunxiangfu/article/details/44026207
第一步:先到官网下载2.7.1-src版本的源码,然后安装JDK(不要搞成jre了),因为编译64位源码需要JDK里面的一些tools。大家不要看到还需要编译就觉得好难,只要下好工具,其实过程中没出啥错误,出了小错按照提示也基本搞定了,无非是缺少什么工具或者是JDK不对之类的。
第二步:编译,编译的话网上有许多教程,都差不多的,这里我就列举了需要哪些工具:

就这么几个,Ant,findbugs,Maven,Protobuf(反正是需要不知道具体干啥用的),jdk1.7(一定要是JDK才可以编译jre不行)大家别嫌太多其实是体力活,就是安装还有配置环境变量,每个一个安装完就用xxxx -version之类的试一试,没问题就是安装好了。
第三步:顺便啰嗦一句安装JDK吧,前面编译的时候其实都装好了。
安装JDK1.7或者1.6都行。
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html 选择版本
1) 下载jdk-7u79-linux-x64.tar.gz,解压到/usr/lib/jdk1.7.0_79。
2) 在/root/.bash_profile中添加如下配置:
export JAVA_HOME=/usr/lib/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
3) 使环境变量生效,#source ~/.bash_profile 可能会提示没有权限问题,切换root用户或者直接重启一下也行。
4) 安装验证#java -version 有打印结果就证明基本是安装对了。
第四步:无密码登录,就是一个拷贝生成的秘钥问题
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
验证ssh,# ssh localhost
这一步是为了无密码登录,网上也有id_rsa.pub的,其实只是加密算法不同,效果都一样,第一次安装后执行localhost可能会弹出一大堆,其实只是让你选yes/no 选yes就OK了。
第五步:安装编译好的hadoop-2.7.1
1) 编译好的文件目录为:/root/hadoop/hadoop-2.7.1
2) 在/root /hadoop/目录下,建立tmp、hdfs/name、hdfs/data目录,执行如下命令
#mkdir /root/hadoop/tmp
#mkdir /root/hadoop/hdfs
#mkdir /root/hadoop/hdfs/data
#mkdir /root/hadoop/hdfs/name
3) 设置hadoop环境变量,就在当前用户下的目录中配置,#vi ~/.bash_profile
# set hadoop path
export HADOOP_HOME=/root /hadoop/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin
使环境变量生效,$source ~/.bash_profile
第六步:配置hadoop相关的xml文件,其实没有太多内容。单机版本的比较少,这部分基本和参照的例子中配置一样,只是路径略有不同,大家按照路径配就可以了。
进入$HADOOP_HOME/etc/hadoop目录,配置 hadoop-env.sh等。涉及的配置文件如下:
hadoop-2.7.1/etc/hadoop/hadoop-env.sh
hadoop-2.7.1/etc/hadoop/yarn-env.sh
hadoop-2.7.1/etc/hadoop/core-site.xml
hadoop-2.7.1/etc/hadoop/hdfs-site.xml
hadoop-2.7.1/etc/hadoop/mapred-site.xml
hadoop-2.7.1/etc/hadoop/yarn-site.xml
1)配置hadoop-env.sh
# java环境
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jdk1.6.0_45
2)配置yarn-env.sh
#export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/lib/jdk1.6.0_45
3)配置core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
4)配置hdfs-site.xml
添加如下配置
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/hdfs/name</value>
<description>namenode上存储hdfs元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
5)配置mapred-site.xml
添加以下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6)配置yarn-site.xml
添加以下配置:
<configuration>
<property>
<!-- 这是配置hadoop里mapreduce的一个混洗 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 注意我们将端口改了等下启动这块的时候也要将端口更改一下 -->
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8099</value>
</property>
</configuration>
第七步:启动hadoop,进入hadoop2.7.1目录中
1)初始化HDFS系统,植入hadoop2.7.1目录执行以下命令
bin/hdfs namenode -format 截图如下: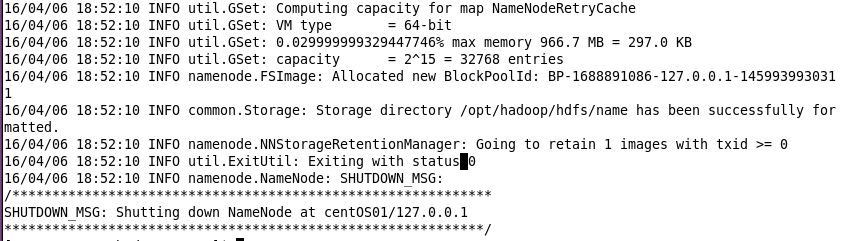
2)开启namenode和datanode守护进程,执行以下命令
sbin/start-dfs.sh 截图如下:
3)执行jps,直接在当前目录下打jps,截图如下:
4)打开hadoop的管理界面和一个yarn的界面
http://localhost:8099 这个端口我们有修改过,大家可以自行修改。
http://localhost:50070 这个是默认的没有改过,都是这个端口。
目前单机版的hadoop搭建工作就完成了,下一篇是往HDFS中导入数据。















 5715
5715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









