






分布式事务
我们首先考虑一致性的特殊情况,即分布式事务的情况。分布式事务对于一致性的要求是强一致性,因此对于我们后续讨论有一定的借鉴意义。
这里我们用到一个经典的例子:bob给smith转账,强一致性的要求一定是需要对外来说bob减钱的同时smith加钱。
因为假设卖家更新成功之后买家立马就能看到卖家的更新,则称为强一致性;
单机环境下是这样的:
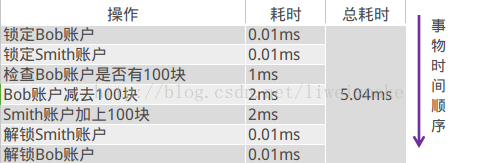
简单讲就是有关bob的减钱和smith的加钱都转同一个库来做,可以采用数据库的事务特性轻松支持。保证bob给smith转账的安全性。
而分布式环境就变这样了:
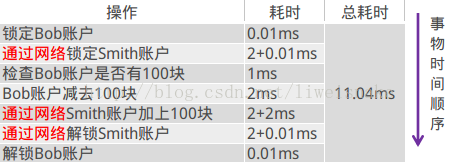
假设应用服务器是A,bob端的数据库是B,smith端的数据是C,那么A做成一个转账,需要B事务成功提交,并且C事务成功提交。然而因为网络的影响,可能出现两种情况:
1. 如果bob扣款成功,而网络通知smith失败了,则会出现bob的钱减了,smith的钱没加
2. 如果bob扣款不成功,而smith加钱成功了,则会出现smith钱增加了,但是bob的钱也没减少
2PC
这种不一致的问题困扰着大家。任意一边出错想要回滚另一边都不是简单的数据库回滚的事情( 因为此时已经成功提交),而是需要做业务的逆向操作,而不同业务的逆操作都不同,导致复杂性增加。考虑数据库事务的执行实际上是先将执行操作写入binlog,等到最后通过一个commit指令将binlog的内容一次更新到表中,或者写到一半通过一个rollback指令将binlog中的内容回滚。于是乎,可以想到使用2个阶段来执行这个过程,第一阶段,写入binlog;第二阶段执行commit或者rollback。这就是著名的两阶段提交协议(2PC)。如果仔细考虑,会发现两阶段协议并没有解决问题,只不过降低了出错的概率而已,因为第二阶段同样存在上面的两种情况。注意最终状态是多台机器的状态&&的 结果。以下是两阶段协议的时序图:
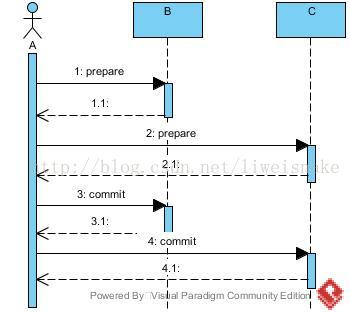
1. 考虑prepare阶段的响应(因为请求阶段和执行阶段都可以在最后响应中体现出来),对于分布式环境中,任意时刻考虑3种状态:成功、失败、超时。
a.成功。不必处理,执行后续行为commit。
b.失败。这是执行阶段出错,执行后续行为rollback。
c.超时。这可能是执行阶段太慢,也可能是网络阶段太慢或丢包,但是保守处理,超时可以当做出错。
可以看出,prepare阶段的问题能够完全避免。
2. 考虑commit阶段,同样考虑成功失败超时3种状态。
a. 成功。整个事务成功执行
b. 失败。提交出错,假设此时前面的B已经提交成功了,则同样面临需要回滚B却无法回滚的问题,因为B已经提交成功了。
c. 超时。同上。
还有一种例外情况,即prepare阶段完成后A挂了,则B,C即进入不知所措的状态。
可以看出,在2PC中事务无法做到像单机一样安全,只不过降低了出问题的概率。
3PC
针对如何解决2PC中的例外情况,出现了3阶段提交协议。3阶段的主要改进是把2阶段的prepare再分为canCommit和preCommit两个阶段。
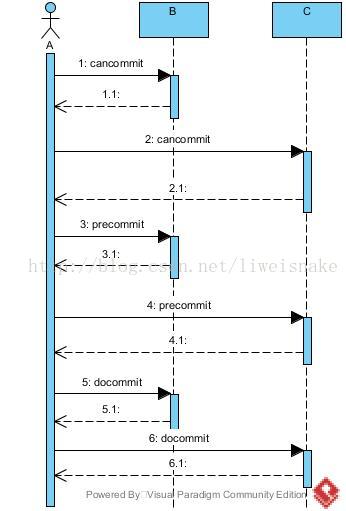
1. 考虑cancommit阶段的响应。
a.成功。不必处理,执行后续行为precommit。
b.失败。说明无法执行,无须后续提交或回滚行为。
c.超时。保守处理,超时可以当做失败。
2. 考虑precommit阶段的响应。
a.成功。不必处理,执行后续行为docommit。
b.失败。执行阶段出错,执行后续行为rollback。
c.超时。执行阶段太慢,也可能是网络阶段太慢或丢包,但是保守处理,超时可以当做出错。
3. 考虑cancommit阶段的响应。
a.成功。整个事务成功执行。
b.失败。提交出错,假设此时前面的B已经提交成功了,则同样面临无法回滚的问题。
c.超时。保守处理,超时可以当做失败。
例外情况,即自cancommit返回成功后的任意阶段A挂掉了,那么BC同样能够知道这个事务正在发生(因为cancommit已经提交了足够信息让BC知晓此事),于是BC可以在无A的情况下继续执行后续的阶段(比如BC投票启动新的A',并提供A'足够信息)。于是3PC正好解决了2PC的例外情况。
但是3PC仍然存在类似2PC的问题,即最后阶段失败或超时同样有可能出现数据不一致的问题。所以3PC仍然只是降低了发生概率,并没有真正解决问题。
XTS
工业界的对分布式事务的应用是如何呢?可以参考某宝的知名分布式框架XTS。
XTS本质上是2PC(实际上如果引入3PC会多2n次网络交互,在量大时反而更加不安全)。XTS引入协调者A的server部分,实际上是一个大集群,以配置的方式接入各种需要分布式事务的业务,集群由专门的团队维护,保证其可用性和性能;而协调者A的client部分则通过发起方调用,prepare阶段时,先通过client将本次事务信息发送到server,落库,然后即时推送prepare请求到B和C,当收到B,C的响应时把他们状态入库,如果正常,则做commit提交;否则会用定时任务去推送未完成的状态直到完成。上文提到的prepare之后协调者A挂了这种情况,在server集群的保证下,几乎很少会发生。而上文提到的所有超时的情况,都可以通过定时任务推送拿到一个确定的状态而不是盲目的选择回滚或者提交。另外由于B和C都是集群,很少会发生多次请求过去无响应的情况。直到最后一种情况就是commit时B成功了C失败了,或者反过来B失败C成功,这种情况成为悬挂事务,最终等待人工来解决,据说每天都有几笔到几十笔。
无疑XTS作为2PC在工业界的应用,是相当了不起的设计,通过各种方式规避了各种可能的不一致性,在性能,效率等方面做到了平衡。
分布式开放消息系统(RocketMQ)的原理与实践 http://www.jianshu.com/p/453c6e7ff81c
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/7667636.html,如需转载请自行联系原作者














 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









