






一:了解集群的原理:
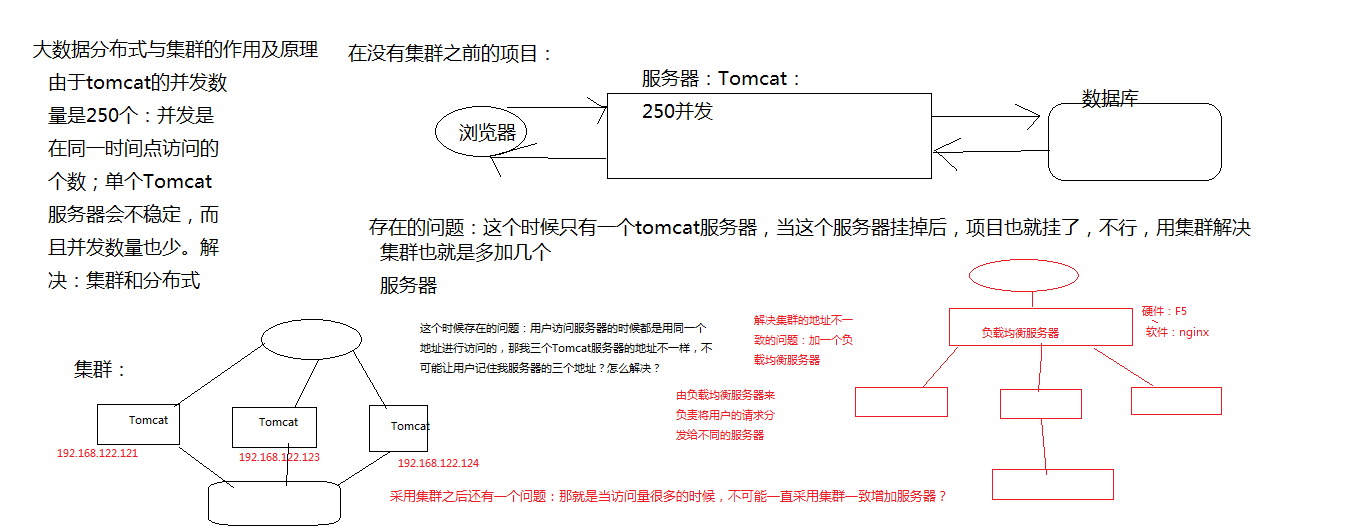
二:集群环境的搭建之前的准备工作:集群环境的搭建需要退回到hadoop分布式搭建之前:这个时候可以在安装hadoop之前在虚拟机中拍一个快照
如果没有拍快照怎么解决:
1,先停掉Hadoop的运行 :stop-dfs.sh
2检查是否停掉:jps:看里面是否还有与Hadoop相关的程序在运行
3如果没有相关的进程运行就删除hadoop的安装软件:rm -rf hadoop(Hadoop的安装文件名);压缩包也一并删除
4 重亲虚拟机
5重启xshell :在看之前安装的hadoop软件是否还有,没有的话就可以进行下面的步骤,有的话重启xshell ::reboot
注意:在这之前要确定jdk的安装是没有问题的;jdk的安装参照上一个文件
三:集群的虚拟机节点的克隆
3,1克隆节点
准备工作:如果自己的电脑性能不是很好的话;要降低虚拟机的内存和删除不必要的设备
点击内存:修改到最低的512m
可以把能删除的设备都删除了:声卡之类的
1,选择已经做好上面步骤的虚拟机:右键---》管理--》克隆
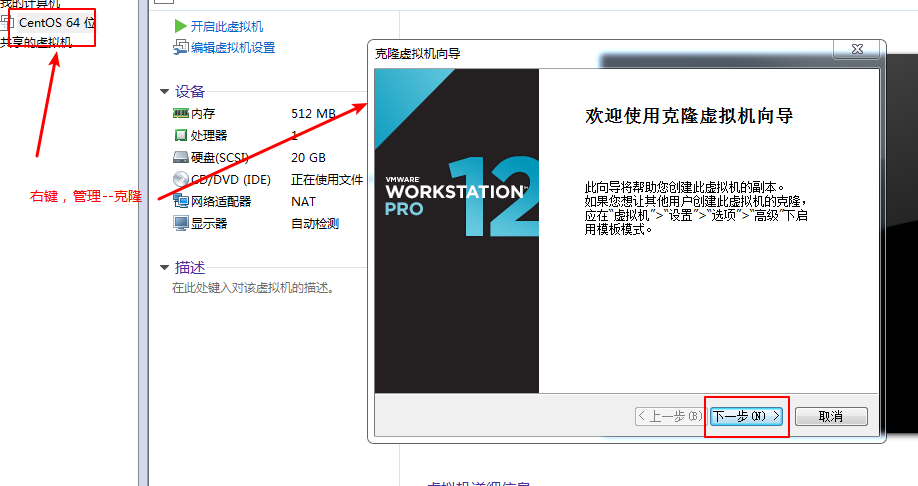
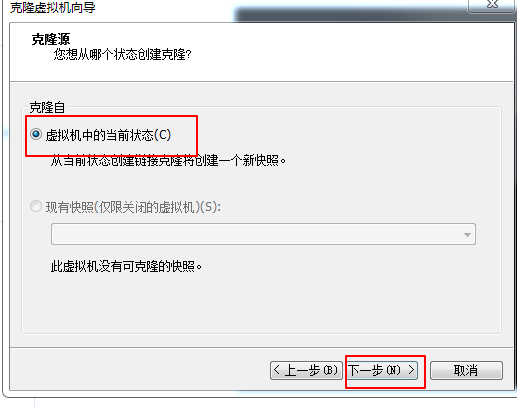
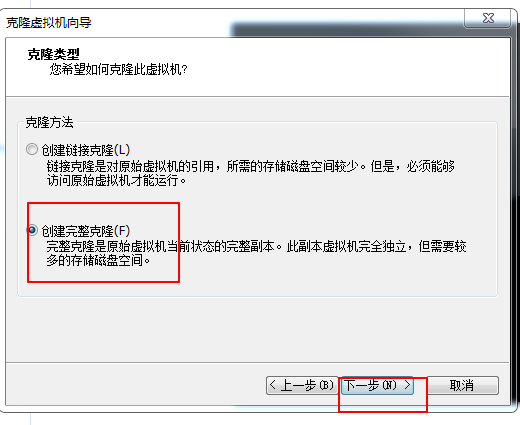
后面就是下一步和等待克隆完成。
然后再根据自己的电脑的性能选择克隆的节点的数目:本机克隆了两个
3,2 克隆的节点(虚拟机)的检查和环境配置
3,2,1启动全部的虚拟机
3,2,2登录虚拟机---》检查各个虚拟机节点的jdk是否安装完成:java -version:出现已经安装的对应的jdk版本就说明已经安装成功
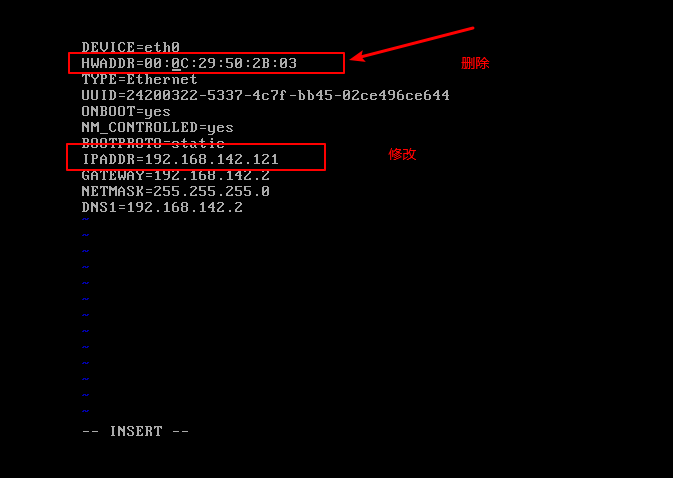
3,2,3ip配置:进入需要配置的文件:vim /etc/sysconfig/network-scripts/ifcfg-eth0
第一步:删除一个配置:
第二步:修改一个IPADDR的地址为之前配置的虚拟机的网段之内的数值:例如192.168.142.122
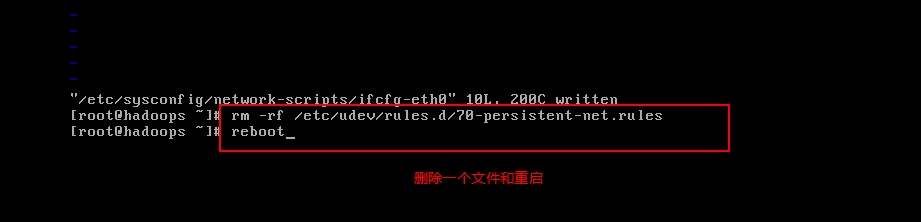
第三步:删除一个文件和重启
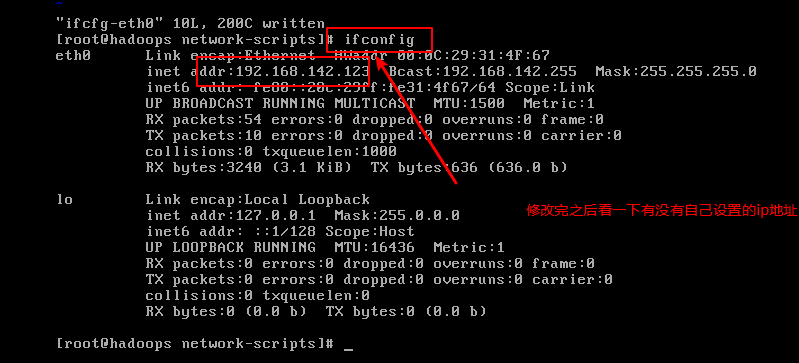
第四步:检查ip是否配置正确:输入命令:ipconfig能够看到已经配置的网址
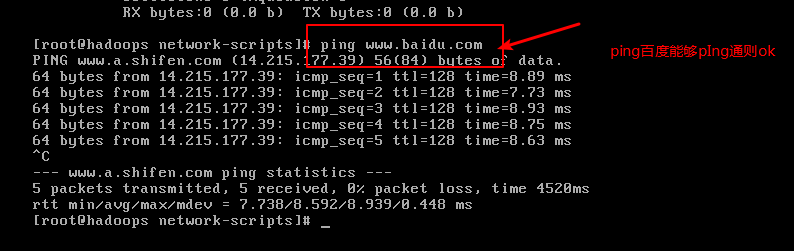
第五步:ping www.bai.du.com看看是否能ping通
3,2,4为了在xshell中的方便使用:在windows中配置映射地址

这里的名字不可以重复,但是ip地址可以重复
3,2,5在xshell中 创建,启动,连接三个虚拟机节点
这个时候因为已经在上一步中配置了映射:在新建对话的时候可以都输入映射的名字
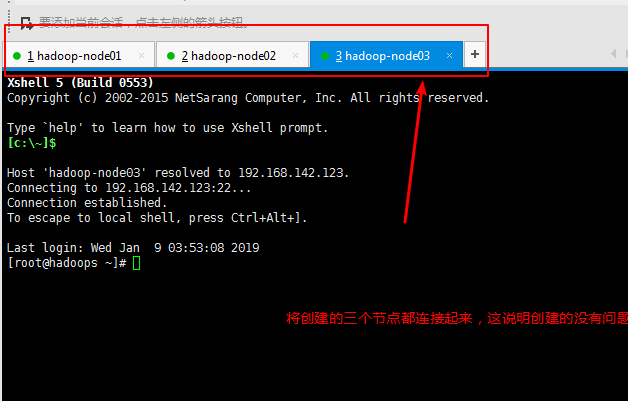
如果三个节点都能启动起来,那么说明节点克隆和映射配置成功;但是这时候还有一个问题:那就是这个时候三个节点的主机名是一样的(因为是克隆过来的),修改主机名和配置的映射地址一致
3,2,6命令: vim /etc/sysconfig/network
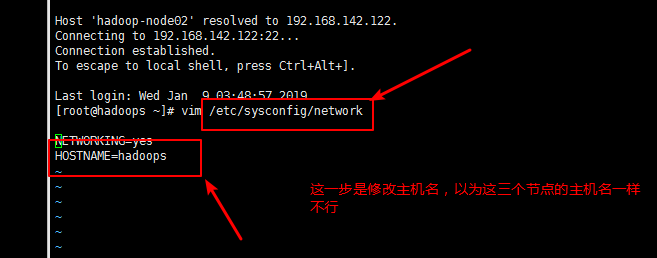
注意:所有的虚拟机节点都必须修改:修改完之后的效果如下
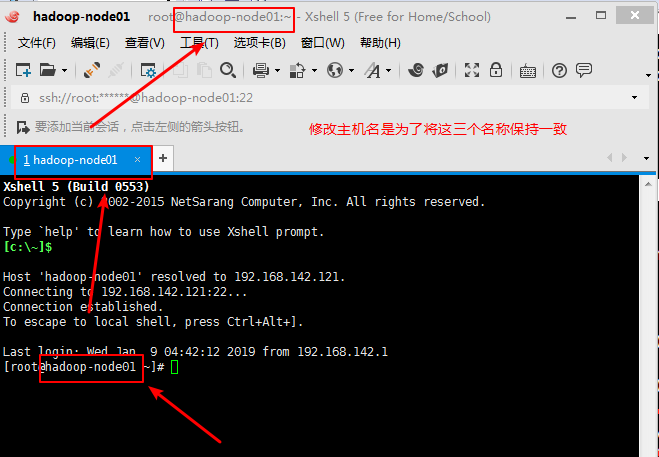
3,2,7修改主机映射
命令:vim /etc/hosts
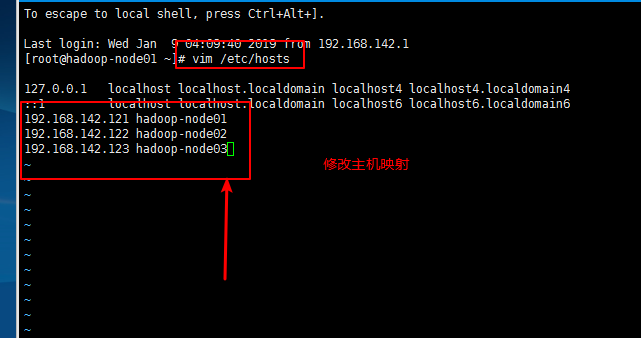
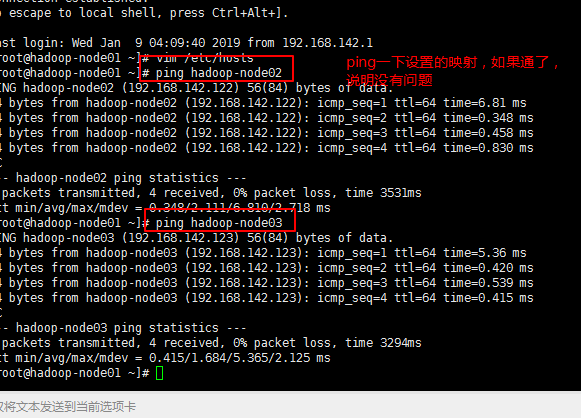
3,2,8验证主机映射是否修改正确:
ping一下设置的各个主机映射地址:例如:ping hadoop-node02:成功则配置ok,否则检查;效果如下:
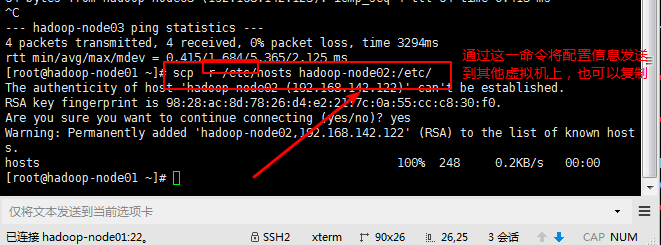
3,2,9这个也是要在三个节点中都需要修改的:有两种方法:一是一个节点一个节点的修改,二是将被克隆的节点主机(namenode节点)的修改文件发送给其他节点
发送的命令:scp -r /etc/hosts hadoop-node02:/etc/;
注意:每个节点都要发送一次
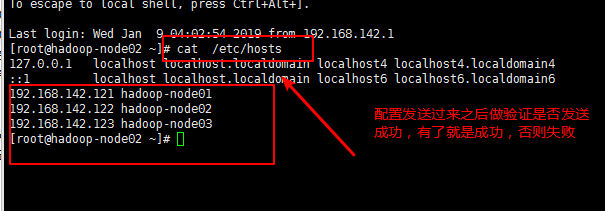
3,2,10发送完成之后可以在对应的节点中查看是否已经发送正确
命令:cat /etc/hosts
3,2,11配置免密登录:是为了namenode节点对其他节点的免密访问
第一步生成的对应的公钥和私钥:
命令: ssh-keygen ;然后四次回车;效果图如下
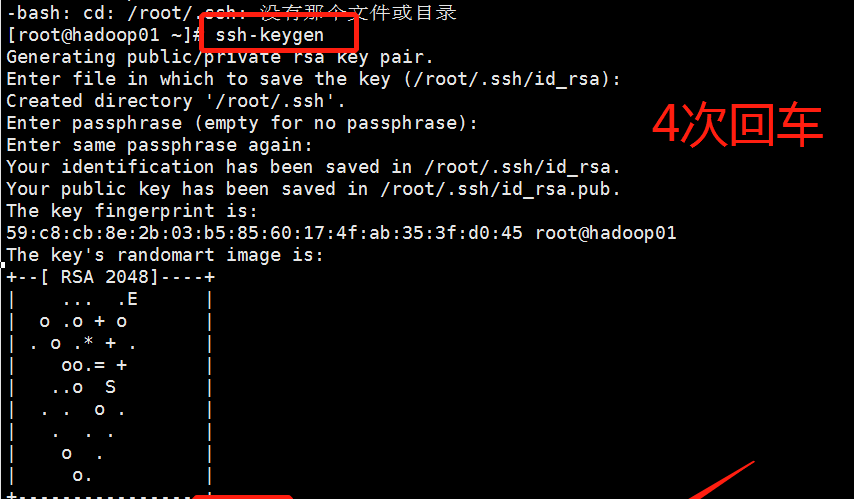
第二步:检查是否生成了对应的文件
命令: ls -a
第三步:检查生成的文件中是否有对应的公钥和私钥文件;由于本人之前配置过所以出现的文件多了;只要出现那两个以id开头的文件就是正确的
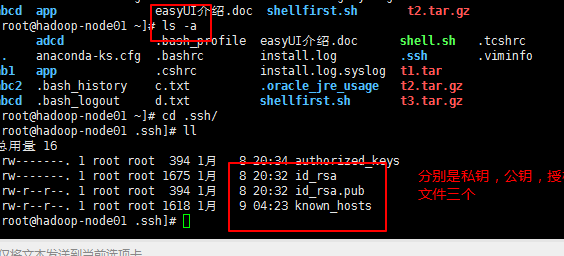
第四步:发送公钥
将公钥添加到要免登陆机器的.ssh文件夹下的authorized_keys中,确保该文件权限为600.
cat id_rsa.pub >> authorized_keys
ls -a 查看目录文件带隐藏文件
这一步完成之后会出现上面的截图中的第一个文件
第五步:实现对其他节点的免密登录:
命令:ssh-copy-id hadoop-node02 对于各个节点都要操作一次
ssh-copy-id hadoop-node3 ;这是在hadoop-node01节点的.ssh文件下操作的
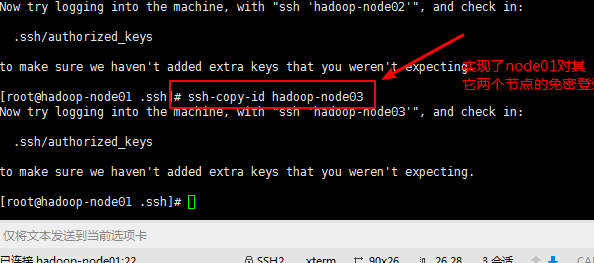
第六步:可以测试一下免密发送是否配置成功;
发送文件到其他的节点,不需要输入对应的密码就是设置成功了。
四 :此时才正式进入集群安装的步骤:前面的都是准备阶段
第一步:上传文件;这个已经在前面的教程中讲过了
第二步:解压压缩包;这个也已经在前面的教程中讲过了;tar -zxvf 压缩包名
第三步:将解压的文件移到/usr/local文件下;mv 解压文件名 新文件名 先改名(也可以不操作) ;mv 新文件名 /usr/local
第四步:修改配置文件:
文件一:hadoop-env.sh;
命令:vim hadoop-env.sh
进入该文件:这里演示一下从最初的根目录进入,修改的全过程;

文件二:core-site.xml
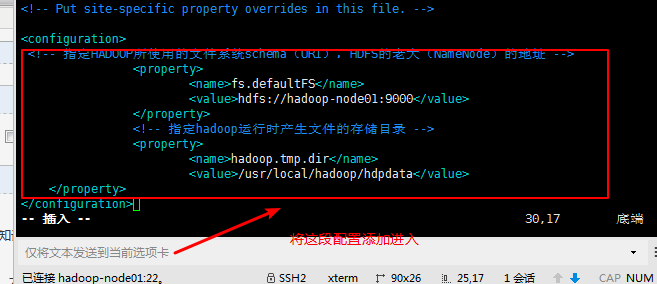
要添加的字段:
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-node-01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
由于xshell在开始的时候不支持粘贴;可以在这里面添加该快捷键;
这里要修改两个地方:<value>hdfs://hadoop-node-01:9000</value>;这里的要修改成namenode节点的名字
<value>/home/hadoop/hdpdata</value>;这里是存储的临时文件;放在指定的目录下
步骤图:
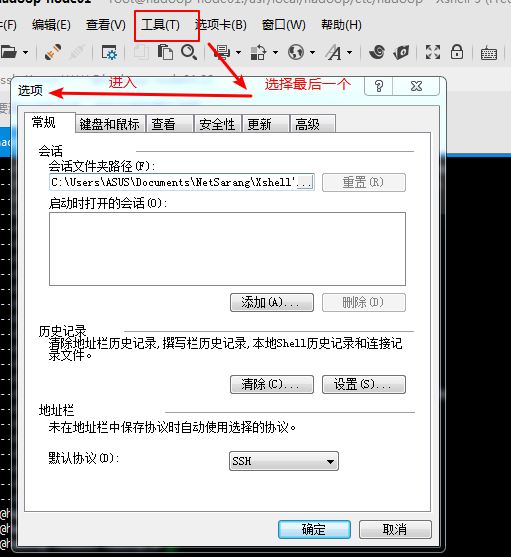
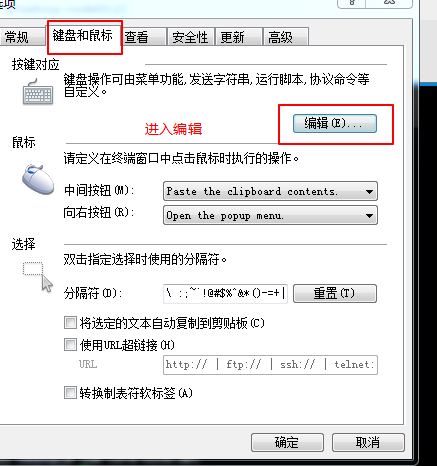
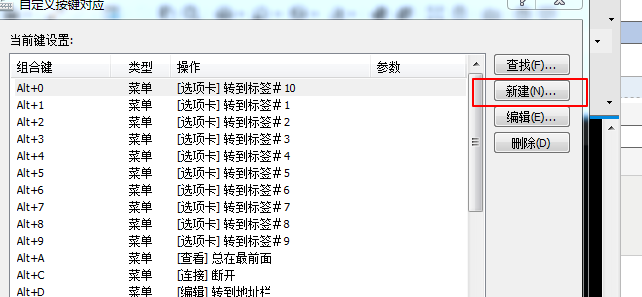
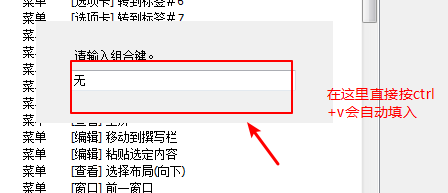
然后选择一下就可以了
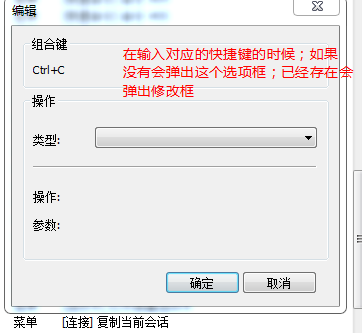
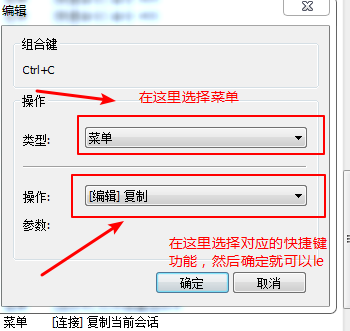
然后就可以看到设置的对应的功能了。
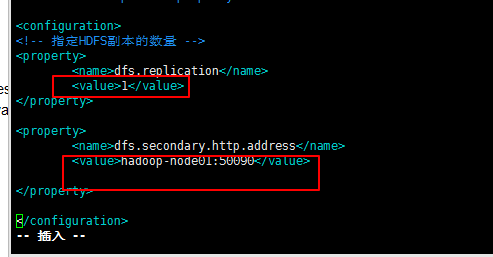
文件三:hdfs-site.xml
要加入的字段:
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.1.152:50090</value>
</property>
要修改的地方如下:
文件四:mapred-site.xml
在已经安装的hadoop中是没有该文件的,但是有一个mapred-site.xml.template
将这个文件改成mapred-site.xml
命令:mv mapred-site.xml.template mapred-site.xml
进入该文件进行修改:vim mapred-site.xml;将这个添加配置里面
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
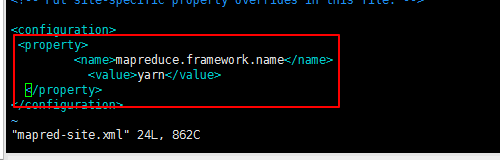
文件五:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-node-02</value>这里要修改
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
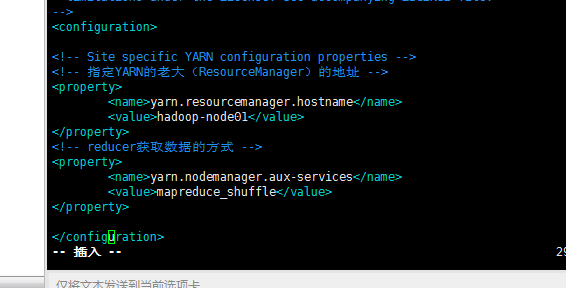
注意要修改的地方
文件六:slaves
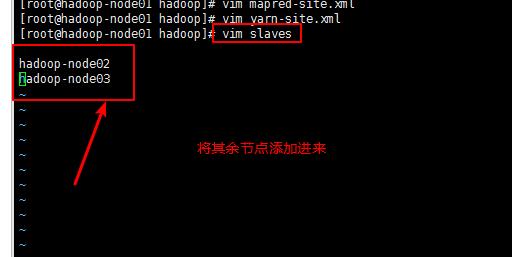
五内容分发:
第一步:先分发hadoop文件到其他节点
命令:scp -r /usr/local/hadoop hadoop-node02:/usr/local/
给每一个节点都要分发
第二步:分发完hadoop之后要检查分发的文件是否正确
将在hadoop-node01中安装hadoop的步骤再走一遍;
也就是集群安装的第四步进入该文件,看看是否能找到跟在hadoop-node01中一样的文件;如果能,则分发成功;否则分发失败’。在每一个节点都检查一遍
第三步修改配置文件
命令:vim /etc/profile
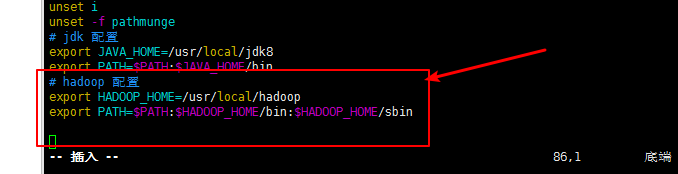
第四步:分发配置文件
scp /etc/profile hadoop-node02:/etc/
也是每个文件都要分发
第五步:只要修改了这个文件都要重启一下source
命令:source /etc/profile

六:HDFS格式化
这里的格式化只需要在namenode的节点上个格式化一次就可以了。
命令:hadoop namenode -format
只要这里的格式化没有问题就会在hadoop文件夹下出现一个之前配置的存储的临时文件
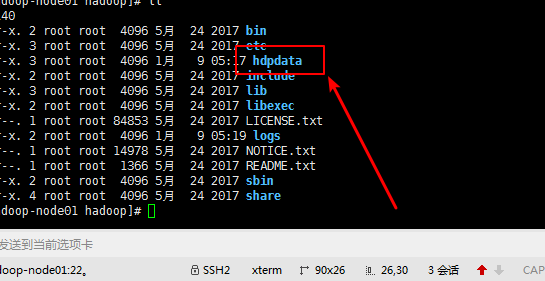
七:启动hadoop
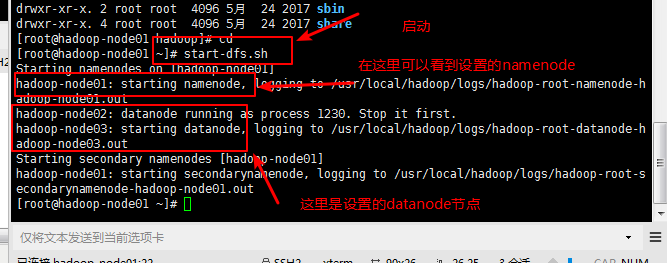
八:在浏览器中访问
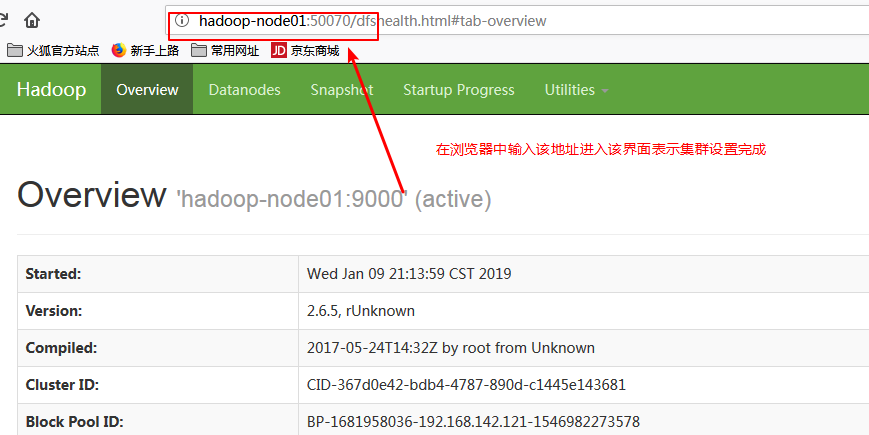
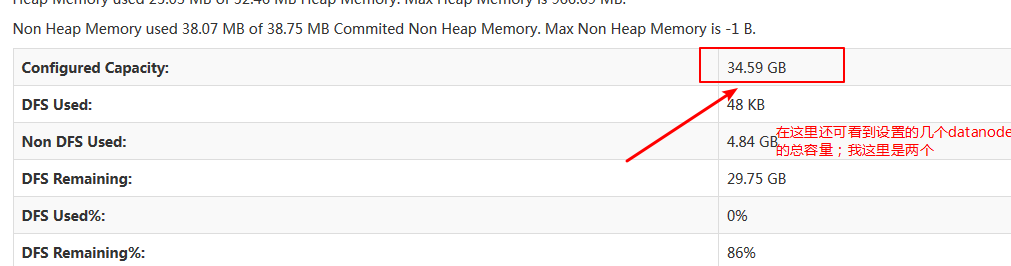
这个时候表示集群环境已经成功搭建!!!!集群会搭建了那么hadoop分布式也就会了














 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









