






常用的负载均衡技术比较
DNS 轮询
DNS本身的机制不再赘述,这里主要看一看基于DNS的负载均衡,其大致原理很清楚,DNS系统本身支持同一个域名映射到多个ip (A记录),例如

这样每次向DNS系统询问该域名的ip地址时(Tell Me The IP Address of niubility.com.),DNS会轮询(Round Robin)这个ip列表,每次给一个不同的ip,从而达到负载均衡的效果。
来看看这种负载均衡解决方案的优缺点
优点
易于实现
对于应用系统本身几乎没有任何侵入,配置也很简单,在某个文本里多加几行A记录就可以。尤其对于一个基于Web的系统来说更是如此,用户在浏览器里输入的URL host部分天然就是域名,所以在某个环节你必然有起码一台DNS服务器记录着这个域名对应的ip,所以可以说是基于已有域名系统(资产)就做到了负载均衡。
缺点
会话粘连 (Session Sticky)
客户端与目标系统之间一般存在会话的概念(不止是web系统的http session), 其本质在于server端会或多或少的存一些客户端整个会话期间交互的身份识别以及数据信息,为了防止server端每次都对同一个客户端问一下,你是谁?系统会希望客户端在一个会话期间粘连在某个特定的serer上,除非这个server失败才failover到其它的server上,这种粘连特性对于server处理客户端请求处理的性能和客户端看到的数据一致性是有很大好处的。但是DNS负载均衡不能保证下一次请求会再次落在同一个server上。
DNS解析缓存和TTL带来的麻烦
dns记录的缓存以及缓存失效时间都是个问题,在无线时代,通常来自手机的访问会经过称为行业网关的代理服务器,由于代理服务器会将域名解析的结果缓存一段时间,所以所有经由这个代理服务器的访问请求就全被解析到同一台服务器上去了,因此就可能无法实现均等分配需要处理的请求了。另外在后端集群的拓扑结构(副本数、部署位置、健康状态等)发生变化之后,dns配置的变化要等到网络上所有节点的缓存失效才能反馈出来,这带来的问题起码有2个,1是在等待失效过程中,完全不可控,没有办法加快这个进程,中美切换要花10分钟,因为要等网络所有几点对某些域名的TTL失效,2是滞后,有时候这种滞后是致命的,比如仍然有部分流量打到已经挂掉的那部分服务器上。
容错
一个大型数据中心,每天都有机器坏了是很正常的事情,尤其是在虚拟化大行其道的今天,更是如此,相信你对虚拟主机又崩溃了一个,或者总是被同宿主机的猪一样的队友“挤”死这种情况一定不陌生。dns负载均衡的一大问题就在于这种情况下的容灾很麻烦,一是需要人工干预或者其他软件配合做健康监测,从dns配置中将无响应的机器或者崩溃的机器的相应的A记录删掉。一是删掉之后也要等到所有网络节点上的dns解析缓存失效,在这端时间内,很多访问系统的客户会受到影响。
数据热点
dns是在域名层面做负载均衡,如果从web系统的请求URL角度讲,不同的URL对后端server的压力强度不一样,dns负载很可能会出现所有高强度的请求全都被打到小部分服务器甚至同一台上去了的情况,这个问题的可怕性不在于风险,而在于风险完全不可控。
引入负载均衡器
如图: 客户端 -> LB -> replica1,replica2,replica3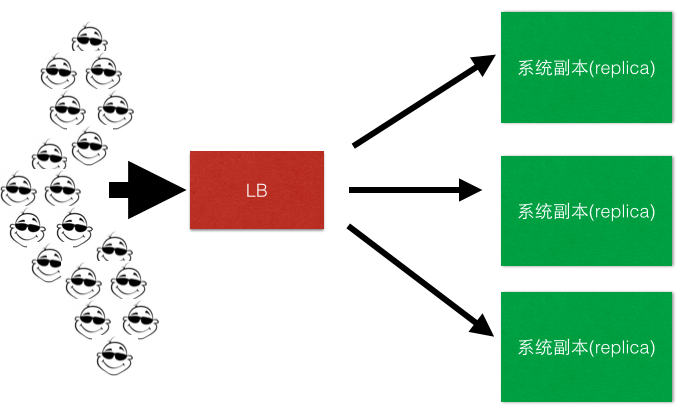
LB负责客户端流量到后端服务集群的分发,一般LB也会负责后端所有server的健康监测,关于健康监测这一块我们在稍后一点再做具体分析。
优点
可以在LB里面做集中的分发逻辑,可以有多种分发方式,例如最常见的Round Robin, Random Robin, Weight-Based Round Robin等。
缺点
LB是单点, 这里其实是有2个问题,下面具体分解一下。
问题1: 所有流量(请求流、响应流)都要经过LB,量太大,LB这小身板扛不住啊,尤其是响应流,一般远大于请求流,为什么? 我们想想一般一个http请求报文大小和响应的报文大小的对比就明白了。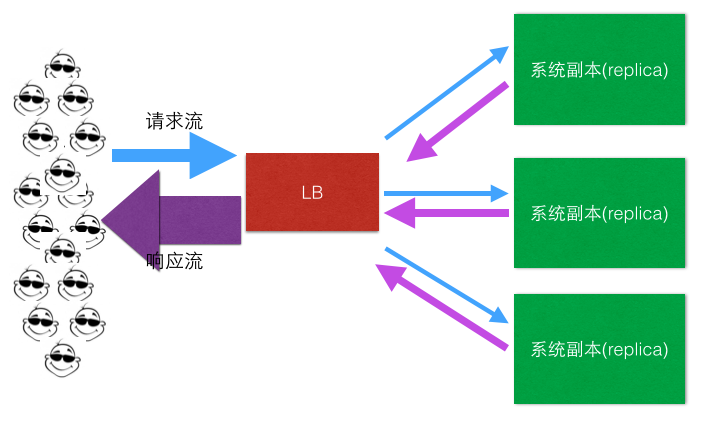
解决方案:
响应流不走LB了!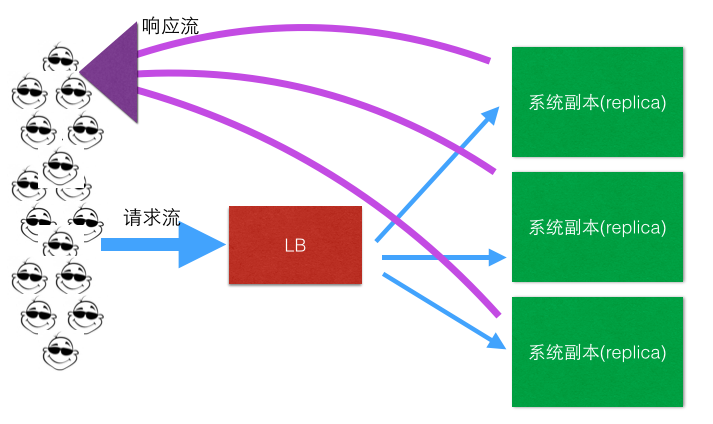
问题2: LB是单点啊,挂了,所有流量都损失了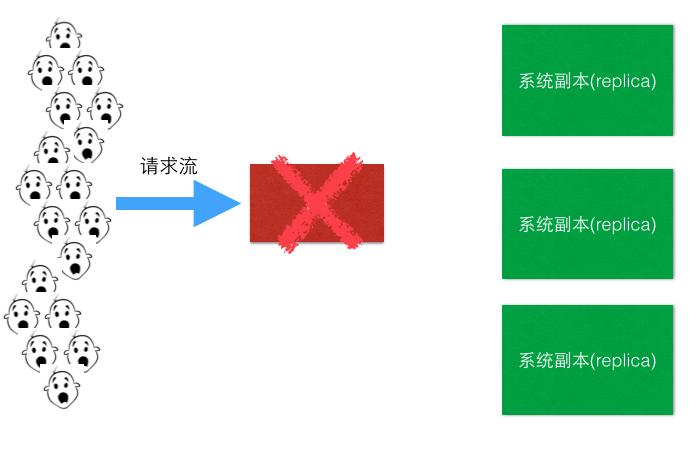
解决方案之一(LB Active-Standby模式):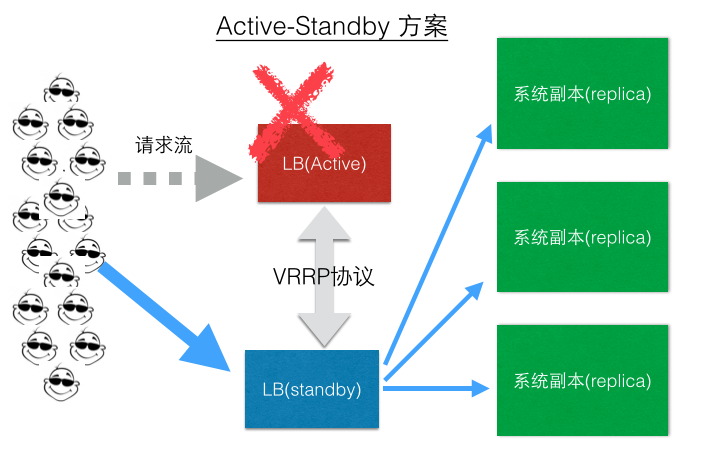
现在一些LB也会支持Active-Active模式,这里不再介绍。
四层LB vs 七层LB
四层LB的特点一般是在网络和网络传输层(TCP/IP)做负载均衡,而七层则是指在应用层做负载均衡。2者的区别还是比较大的,各有优缺点,四层LB对于应用侵入比较小,这一层的LB对应用的感知较少,同时应用接入基本不需要针对LB做任何的代码改造。七层负载均衡一般对应用本身的感知比较多,可以结合一些通用的业务流量负载逻辑和容灾逻辑做成很细致的负载均衡和流量导向方案,但是一般接入时,应用需要配合做相应的改造。
互联网时代流量就是钱啊,对于流量的调度的细致程度往往是四层LB难以满足的,可以说七层负载均衡的解决方案现在是百花齐放,百家争鸣,中间层负载均衡(mid-tier load balancing)正当其时。
三、健康检测,负载均衡的伴侣
对于LB或者一个LB解决方案来说,健康检测是LB固有需要一起实现的需求之一,LB要能帮助业务实现业务、服务器、容器的优雅上、下线,帮助业务实现透明的扩容、缩容等一系列很现实的功能,如下简图:
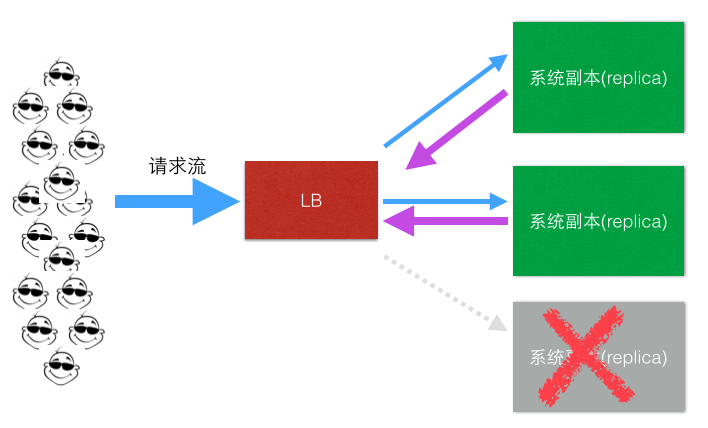
在云计算时代弹性计算(Elastic Compute Service),按需伸缩(On-Demand Allocation)大行其道的今天,对于LB健康检测方案的灵敏度,准确性,多层次等等都提出了非常高的要求,别看健康检测这个功能貌似很简单,但是实现过程中如果有很多地方没有想到,很容易就造成系统的重大的故障,我们的一些系统在心跳检测上栽的跟头并不少,踩过很多的坑。
四、为什么我们要做VIPServer?
在有@正明(章文嵩博士的花名)这样的技术大牛,LVS的原作者本尊坐镇的阿里,为什么阿里会再做一个负载均衡产品?其实很简单,为了解决实际的业务问题。在集团,阿里技术团队常常面临的都是世界级难题,中间件团队更是如此,我们不敢说对这些问题我们解得多好,但我们真的在踏实的认真的解这些问题,而且用我们自己特有的方式,而不是COPY国外技术栈的方式在解这些难题,其实我们很多时候也很想COPY啊,但是放眼全球相关领域确实是没得抄。言归正传,上面我们过了一遍常见的负载均衡方案之后,我们可以发现传统LB,如LVS的解决方案中并不是把所有的问题都已经解决了,我们检视一下,起码还遗留了6个问题:
1、如果过LB的请求量就大到把LB给打挂了怎么办?互联网的流量,尤其是中国互联网的流量,我们要有足够的自信啊,而且参与过春节买票的,春晚修一修抢红包的都能想象得到。
2、LB虽然可以有standby的方案或者有小规模集群能力,但如果active/standby同时挂了怎么办? 1个蛋蛋很危险,但2个蛋蛋也未必就多安全。比如在active-standby方案中,既然active撑不住请求流量,那么作为其clone的standby身上当然也不会出现任何奇迹,那么是不是LB前面还应该再架一层LB呢?能不能LB集群全挂了的情况下,不影响正常的业务?
3、请求方和目标机器之间总是要过一次LB,这在网络链路上是多了1跳,我们都知道多一跳可不光是rt的损耗那么简单,链路上从1跳到2跳,链路和连接出故障的概率也翻了一倍,这要怎么解?
4、多机房,多区域的异地多活与容灾,国际化战略的跨国流量的容灾对于负载均衡提出的挑战怎么解,在阿里集团内部,现在断网、断电、断机房的演习如日常喝水、像办公大楼消防演习一样随意,据说要达到,马老师半夜起来上个厕所,顺便断个电的能力,这些容灾场景下业务流量的负载均衡怎么解?
5、每次在一些如“秒杀”,“大促”等营销热点场景下,业务为了应对可以预期的流量洪峰,评估LB这一块的容量够不够、要扩多少的痛点又如何解决?LB的弹性在哪里?
6、成本。虽然LVS比一些传统硬件LB的成本已经有很大的优势,但是在一个大型互联网系统级别的流量和业务发展面前,LVS的使用成本还是太高了一点。
VIPServer就是为了解决这些实际问题而生,所以上面介绍的这些我们耳熟能详的机制全都不是VIPServer解决问题的思路
五、VIPServer简介
VIPServer是阿里中间件团队开发的一个中间层负载均衡(mid-tier load balancing)产品,VIPServer是基于P2P模式,是一个七层负载均衡产品。VIPServer提供动态域名解析和负载均衡服务,支持很多诸如多业务单元同单元优先、同机房优先、同区域优先等一系列流量智能调度和容灾策略,支持多种健康监测协议,支持精细的权重控制,提供多级容灾体系、具有对称调用、健康阈值保护等保护功能的解决方案。是阿里负载均衡体系、域名服务体系的一个非常重要的组成部分。目前包括阿里妈妈、钉钉、搜索、AE、1688、阿里云、高德等几乎所有的业务线均在使用VIPServer,在一些重大的项目例如历年双11,支付宝春晚红包项目都发挥了重大的作用。
https://yq.aliyun.com/articles/53735
openresty负载均衡
https://moonbingbing.gitbooks.io/openresty-best-practices/ngx/balancer.html
简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
例如:
如果一个任务由10个子任务组成,每个子任务单独执行需1小时,则在一台服务器上执行改任务需10小时。
采用分布式方案,提供10台服务器,每台服务器只负责处理一个子任务,不考虑子任务间的依赖关系,执行完这个任务只需一个小时。(这种工作模式的一个典型代表就是Hadoop的Map/Reduce分布式计算模型)
而采用集群方案,同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,10小后,10个任务同时完成,这样,整身来看,还是1小时内完成一个任务!
以下是摘抄自网络文章:
一、集群概念
1. 两大关键特性
集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台。在客户端看来,一个集群就象是一个服务实体,但事实上集群由一组服务实体组成。与单一服务实体相比较,集群提供了以下两个关键特性:
可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。
高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。在集群中,同样的服务可以由多个服务实体提供。如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。集群提供的从一个出 错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。
2. 两大能力
为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力:
负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。
3. 两大技术
实现集群务必要有以下两大技术:
集群地址--集群由多个服务实体组成,集群客户端通过访问集群的集群地址获取集群内部各服务实体的功能。具有单一集群地址(也叫单一影像)是集群的一个基本特征。维护集群地址的设置被称为负载均衡器。负载均衡器内部负责管理各个服务实体的加入和退出,外部负责集群地址向内部服务实体地址的转换。有的负载均衡器实现真正的负载均衡算法,有的只支持任务的转换。只实现任务转换的负载均衡器适用于支持ACTIVE-STANDBY的集群环境,在那里,集群中只有一个服务实体工作,当正在工作的服务实体发生故障时,负载均衡器把后来的任务转向另外一个服务实体。
内部通信--为了能协同工作、实现负载均衡和错误恢复,集群各实体间必须时常通信,比如负载均衡器对服务实体心跳测试信息、服务实体间任务执行上下文信息的通信。
具有同一个集群地址使得客户端能访问集群提供的计算服务,一个集群地址下隐藏了各个服务实体的内部地址,使得客户要求的计算服务能在各个服务实体之间分布。内部通信是集群能正常运转的基础,它使得集群具有均衡负载和错误恢复的能力。
二、集群分类
Linux集群主要分成三大类(高可用集群, 负载均衡集群,科学计算集群)
- 高可用集群(High Availability Cluster)
- 负载均衡集群(Load Balance Cluster)
- 科学计算集群(High Performance Computing Cluster)
具体包括:
Linux High Availability 高可用集群
(普通两节点双机热备,多节点HA集群,RAC, shared, share-nothing集群等)
Linux Load Balance 负载均衡集群
(LVS等....)
Linux High Performance Computing 高性能科学计算集群
(Beowulf 类集群....)
三、详细介绍
1. 高可用集群(High Availability Cluster)
常见的就是2个节点做成的HA集群,有很多通俗的不科学的名称,比如"双机热备","双机互备","双机"。
高可用集群解决的是保障用户的应用程序持续对外提供服务的能力。 (请注意高可用集群既不是用来保护业务数据的,保护的是用户的业务程序对外不间断提供服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度)。
2. 负载均衡集群(Load Balance Cluster)
负载均衡系统:集群中所有的节点都处于活动状态,它们分摊系统的工作负载。一般Web服务器集群、数据库集群和应用服务器集群都属于这种类型。
负载均衡集群一般用于相应网络请求的网页服务器,数据库服务器。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器上。从检查其他服务器状态这一点上看,负载均衡和容错集群很接近,不同之处是数量上更多。
3. 科学计算集群(High Performance Computing Cluster)
高性能计算(High Perfermance Computing)集群,简称HPC集群。这类集群致力于提供单个计算机所不能提供的强大的计算能力。
3.1 高性能计算分类
3.1.1 高吞吐计算(High-throughput Computing)
有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。象在家搜寻外星人( SETI@HOME -- Search for Extraterrestrial Intelligence at Home )就是这一类型应用。这一项目是利用Internet上的闲置的计算资源来搜寻外星人。SETI项目的服务器将一组数据和数据模式发给Internet上参加SETI的计算节点,计算节点在给定的数据上用给定的模式进行搜索,然后将搜索的结果发给服务器。服务器负责将从各个计算节点返回的数据汇集成完整的 数据。因为这种类型应用的一个共同特征是在海量数据上搜索某些模式,所以把这类计算称为高吞吐计算。所谓的Internet计算都属于这一类。按照 Flynn的分类,高吞吐计算属于SIMD(Single Instruction/Multiple Data)的范畴。
3.1.2 分布计算(Distributed Computing)
另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。按照Flynn的分类,分布式的高性能计算属于MIMD(Multiple Instruction/Multiple Data)的范畴。
四、分布式(集群)与集群的联系与区别
分布式是指将不同的业务分布在不同的地方;而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。
举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。
而分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。
分布式的每一个节点,都完成不同的业务,一个节点垮了,那这个业务就不可访问了。














 1571
1571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









