






回归正题,今天要跟大家分享的是一些 Convolutional Neural Networks(CNN)的工作。
大家都知道,CNN 最早提出时,是以一定的人眼生理结构为基础,然后逐渐定下来了一些经典的架构——convolutional 和 pooling 的交替,最后再加上几个 fully-connected layers 用作最后做 prediction 等的输出。然而,假设我们能“反思”经典,深入剖析这些经典架构中的不同 component 的作用。甚至去改进它们,有时候可能有许多其它的发现。
所以,今天分享的内容,便是改进 CNN 的一些工作。
Striving For Simplicity:The All Convolutional Net
先说一篇探究 CNN 中不同 component 的重要性和作用的工作。这篇工作发表于 ICLR 2015。已经有一年多的时间了。
个人觉得它应该受到更大的关注。这篇工作最大的贡献是,把经典架构的 CNN 中的 pooling 层。用 stride convolutional 层给替换掉了,也就是去掉了 deterministic 层。而且,通过数学公式和实验结果证明。这种替换是全然不会损伤性能的。而增加 pooling 层,假设不慎,甚至是有伤性能的。
详细来看。CNN 中的每次 feature map 表达,都能够看做一个 W*H*N 的三维结构。在这个三维结构下,pooling 这种 subsampling 的操作,能够看成是一个用 p-norm(当 p 趋向于正无穷时,就是我们最常见的 max-pooling)当做 activation function 的 convolutional 操作。
有了这种解释。自然而然地,就会提出一个问题:那么引入这种 pooling 操作,有什么意义呢?真的有必要么?在过去的工作中,大家普遍觉得。pooling 层有三种可能的功效:(1)提取更 invariant 的 feature;(2)抽取更广范围的(global)的 feature——即 spatially dimension reduction;(3)更方便优化。这篇作者觉得,当中(2)是对 CNN 最重要的。基于此,它们就提出,那么我仅仅要在去掉 pooling 层的同一时候,保证这种 spatially dimension reduction——是否就能够构造出一个 all convolutional net。同一时候这个 net 的效果还不比 convolutional + pooling 交替的差?

最后,果然。如他们所料。它们的 all convolutional net 达到了甚至有时候超过了 state-of-art。同一时候他们还发现有时候增加 pooling 反而不如不加。这篇工作的另外一个贡献是他们提出了一种新的 visualizing CNN 的方法,效果更直观更有分辨性。总结来说,这篇工作提出的 all convolutional net 能够实现自主 downsampling,而且效果不差。其二。它不是在说 pooling 不好,我们一定要抛弃。而是对于 minimum necessary ingredients for CNN 进行了探究。
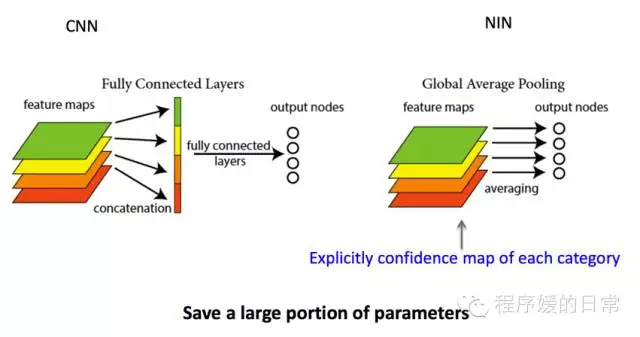
Network in Network
第一个要分享的是怎样去 replace pooling layer after convolutional layer,接下来要分享的是 replace fully-connected layer on the top of CNN。这个也是经典的 CNN 架构中的一个组成部分。
或许这个东西大家还不熟悉。可是提到还有一个词,大家就会很熟悉了。
那就是,dropout。已经有许多的工作。在 CNN 的 fully-connected layer 中。增加 dropout。来避免 overfitting。受此启示,后来又有了一个 sparse convolutional neural networks 的工作。然而。更具开创性的工作是。《Network in Network》这篇,提出了用 global averaging pooling layer 替代 fully-connected layer.
这种 global averaging pooling layer 显然,能够把 input/feature map 和 output/category,也就能够达到降低 overfitting 的作用(和 dropout 一样)。
如今。global average pooling 已经被用得很广泛,比方在《Going Deeper with Convolutions》中,作者指出:
We found that a move from fully connected
layers to average pooling improved the top-1 accuracy by
about 0.6%, however the use of dropout remained essential
even after removing the fully connected layers.
当然它也有它自己的一定弊端。比方 convergence 会变慢。可是关于 fully-connected layer 是否一定是必须的这个问题。却在被各种工作和各种场景探究。

比方 Google 去年很火的 inceptionism 的工作中。也放弃了 fully-connected layer。并达到了很好的效果。
所以,关于这点,小S 是觉得。我们不要光看表面的 dropout or global averaging pooling 这些技术,而是要去思考它们的共同之处和它们的原理。从它们带给网络结构的变化入手。或许如今来看,最初的结论还是对的,deeper is better。我们临时要解决的是怎样 deeper。
Spatial Transformer Networks
这篇是 NIPS 2015 中,来自 Google DeepMind 的工作。
这篇也被前几天 huho larochelle 评选出的 Top 10 arXiv 2015 Deep Learning Papers 收录(另外提一下。昨天看到这个评选,发现大部分我都写过笔记了。大家假设感兴趣,我能够单独整理一份,以供大家查阅)。
回到这篇工作上来。它主要是说,虽然 CNN 一直号称能够做 spatial invariant feature extraction,可是这种 invariant 是很有局限性的。
由于 CNN 的 max-pooling 首先仅仅是在一个很小的、rigid 的范围内(2×2 pixels)进行。其次即使是 stacked 以后,也须要很 deep 才干够得到大一点范围的 invariant feature,三者来说,相比 attention 那种仅仅能抽取 relevant 的 feature,我们须要的是更广范围的、更 canonical 的 features。
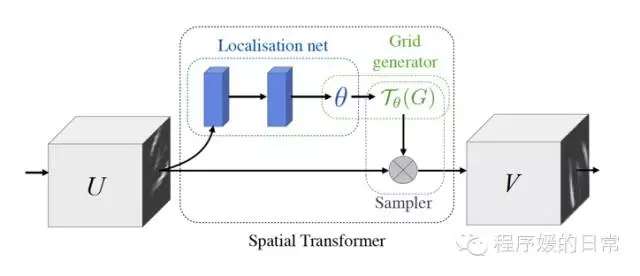
为此它们提出了一种新的全然 self-contained transformation module,能够增加在网络中的不论什么地方,灵活高效地提取 invariant image features.
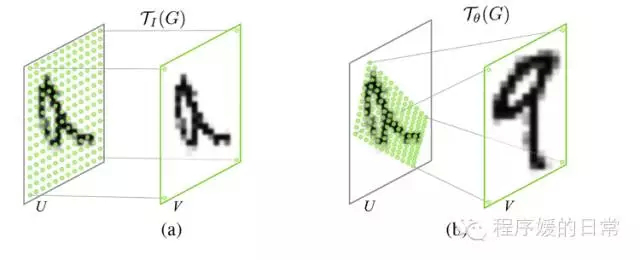
详细上。这个 module 就叫做 Spatial Transformers,由三个部分组成: Localization Network, Grid generator 和 Sampler。Localization Network 很灵活,能够觉得是一个很 general 的进一步生成 feature map 和 map 相应的 parameter 的网络。因此,它不局限于用某一种特定的 network。可是它要求在 network 最后有一层 regression。由于须要将 feature map 的 parameter 输出到下一个部分:Grid generator。Grid generator 能够说是 Spatial Transformers 的核心,它主要就是生成一种“蒙版”,用于“抠图”(Photoshop 附体……)。Grid generator 定义了 Transformer function。这个 function 的决定了能不能提取好 invariant features。
假设是 regular grid。就好像一张四四方方没有倾斜的蒙版。是 affined grid。就能够把蒙版“扭曲”变换,从而提取出和这个蒙版“变换”一致的特征。
在这个工作中,仅仅须要六个參数就能够把 cropping, translation, rotation, scale and skew 这几种 transformation 都涵盖进去。还是很强大的;而最后的 Sampler 就很好理解了,就是用于把“图”抠出来。
这个工作有许多的长处:(1)它是 self-contained module,能够加在网络中的不论什么地方,加不论什么数量,不须要改变原网络;(2)它是 differentiable 的,所以能够直接进行各种 end-to-end 的训练。(3)它这个 differentiable simple and fast,所以不会使得原有网络变慢。(4)相比于 pooling 和 attention 机制,它抽取出的 invariant features 更 general。
Stacked What-Where Auto-encoders
这篇文章来自 NYU,Yann LeCun 组,已投稿到 ICLR 2016。
与之前整理过的 improving information flow in Seq2Seq between encoder-decoder 相似的是。这篇文章主要是改进了基于 CNN 的 encoder-decoder,并很 intuitive 的讨论了不同 regularizer 的差别。架构图能够直接看 Figure 1 的右側。会比較清晰。详细来讲,Stacked What-Where Auto-encoders(SWWAE) 基于前向 Convnet 和前向 Deconvnet,并将 max-pooling 的输出称为 “what”,事实上就是将 max function 的 content 和 position 传给下一层。同一时候,max-pooling 中的 position/location 信息,也就是 argmax function,作为 “where” 要“横向”传给 decoder。这样。在进行 decoder reconstruct 的过程时。则更能基于 where + what 的组合。进行 unpooling。
为了能让网络利用好 what 和 where,文章考虑了三种 loss,见公式(1),即传统的 discriminate loss,和新增的 input-level reconstruction loss for “what” 还有 intermediate-level reconstruction loss for “where”。
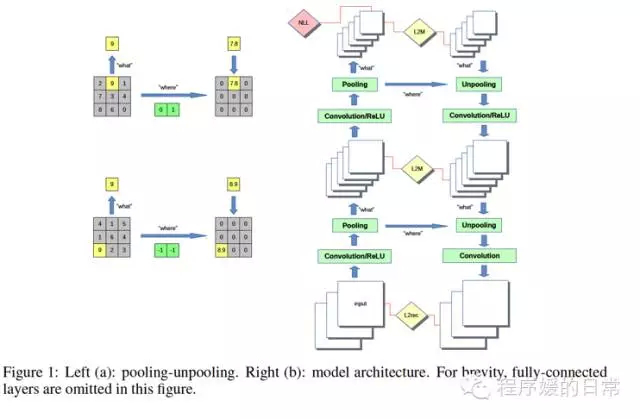
如上文所说。文章的 Section 3 很 intuitive,首先说明并解了为什么使用的是 soft version 的 max/argmax 去进行 ”what“ 和 ”where“;第二,讨论了为何增加 reconstruction loss 和这样一个 hybird loss function 更好(generalization 和 robustness);第三,说明了 intermediate loss 对于“what”“where”一起学习的重要性。
实验结果上来看,这种 SWWAE 模型 generate 出来的图片更清晰,更“干净”(clearer and cleaner)。
















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









