







第三章 通道
“辉煌!绝对的辉煌!”
—— Wile E. Coyote (超级天才)
通道(Channel)是 java.nio 的第二个主要创新。它们既不是一个扩展也不是一项增强,而是全新、极好的 Java I/O 示例,提供与 I/O 服务的直接连接。Channel 用于在字节缓冲区和位于通道另一侧的实体(通常是一个文件或套接字)之间有效地传输数据
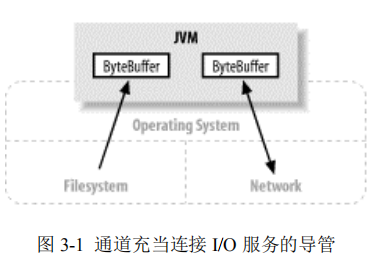
通道可以形象地比喻为银行出纳窗口使用的气动导管。您的薪水支票就是您要传送的信息,载体(Carrier)就好比一个缓冲区。您先填充缓冲区(将您的支票放到载体上),接着将缓冲“写”到通道中(将载体丢进导管中),然后信息负载就被传递到通道另一侧的 I/O 服务(银行出纳员)。
该过程的回应是:出纳员填充缓冲区(将您的收据放到载体上),接着开始一个反方向的通道传输(将载体丢回到导管中)。载体就到了通道的您这一侧(一个填满了的缓冲区正等待您的查验),然后您就会 flip 缓冲区(打开盖子)并将它清空(移除您的收据)。现在您可以开车走了,下一个对象(银行客户)将使用同样的载体(Buffer)和导管(Channel)对象来重复上述过程。
多数情况下,通道与操作系统的文件描述符(File Descriptor)和文件句柄(File Handle)有着一对一的关系。虽然通道比文件描述符更广义,但您将经常使用到的多数通道都是连接到开放的文件描述符的。Channel 类提供维持平台独立性所需的抽象过程,不过仍然会模拟现代操作系统本身的 I/O 性能
通道是一种途径,借助该途径,可以用最小的总开销来访问操作系统本身的 I/O 服务。缓冲区则是通道内部用来发送和接收数据的端点。 (见图 3-1)
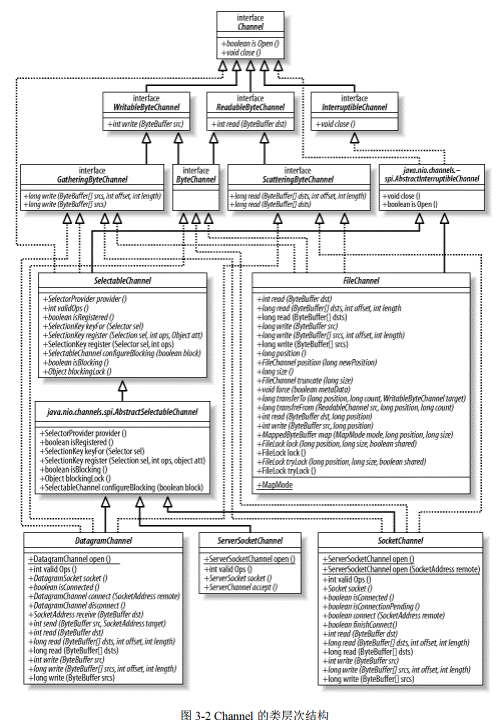
观察图 3-2 所示的 UML 类图会发现,channel 类的继承关系要比 buffer 类复杂一些。Channel类相互之间的关系更复杂,并且部分 channel 类依赖于在 java.nio.channels.spi 子包中定义的类。本章我们将对该困惑进行澄清。通道 SPI 归纳参见附录 B。
不多讲了,让我们马上开始探索激动人心的通道世界吧!
3.1 通道基础
首先,我们来更近距离地看一下基本的 Channel 接口。下面是 Channel 接口的完整源码:
package java.nio.channels;
public interface Channel
{
public boolean isOpen( );
public void close( ) throws IOException;
}与缓冲区不同,通道 API 主要由接口指定。不同的操作系统上通道实现(Channel Implementation)会有根本性的差异,所以通道 API 仅仅描述了可以做什么。因此很自然地,通道实现经常使用操作系统的本地代码。通道接口允许您以一种受控且可移植的方式来访问底层的 I/O服务
您可以从顶层的 Channel 接口看到,对所有通道来说只有两种共同的操作:检查一个通道是否打开(IsOpen())和关闭一个打开的通道(close())。图 3-2 显示,所有有趣的东西都是那些实现Channel 接口以及它的子接口的类.
InterruptibleChannel 是一个标记接口,当被通道使用时可以标示该通道是可以中断的(Interruptible)。如果连接可中断通道的线程被中断,那么该通道会以特别的方式工作,关于这一点我们会在 3.1.3 节中进行讨论。大多数但非全部的通道都是可以中断的
从 Channel 接口引申出的其他接口都是面向字节的子接口,包括 Writable ByteChannel 和ReadableByteChannel。这也正好支持了我们之前所学的:通道只能在字节缓冲区上操作。层次结构表明其他数据类型的通道也可以从 Channel 接口引申而来。这是一种很好的类设计,不过非字节实现是不可能的,因为操作系统都是以字节的形式实现底层 I/O 接口的。
观察图 3-2,您还会发现类层次结构中有两个类位于一个不同的包:java.nio.channels.spi。这两个类是 AbstractInterruptibleChannel 和AbstractSelectableChannel,它们分别为可中断的(interruptible)和可选择的(selectable)的通道实现提供所需的常用方法。尽管描述通道行为的接口都是在 java.nio.channels 包中定义的,不过具体的通道实现却都是从 java.nio.channels.spi 中的类引申来的。这使得他们可以访问受保护的方法,而这些方法普通的通道用户永远都不会调用。
作为通道的一个使用者,您可以放心地忽视 SPI 包中包含的中间类。这种有点费解的继承层次只会让那些使用新通道的用户感兴趣。SPI 包允许新通道实现以一种受控且模块化的方式被植入到Java 虚拟机上。这意味着可以使用专为某种操作系统、文件系统或应用程序而优化的通道来使性能最大化。
3.1.1 打开通道
通道是访问 I/O 服务的导管。正如我们在第一章中所讨论的,I/O 可以分为广义的两大类别:File I/O 和 Stream I/O。那么相应地有两种类型的通道也就不足为怪了,它们是文件(file)通道和套接字(socket)通道。如果您参考一下图 3-2,您就会发现有一个 FileChannel 类和三个 socket 通道类:SocketChannel、ServerSocketChannel 和 DatagramChannel。
通道可以以多种方式创建。Socket 通道有可以直接创建新 socket 通道的工厂方法。但是一个FileChannel 对象却只能通过在一个打开的 RandomAccessFile、FileInputStream 或 FileOutputStream对象上调用 getChannel( )方法来获取。您不能直接创建一个 FileChannel 对象。File 和 socket 通道会在后面的章节中予以详细讨论。
SocketChannel sc = SocketChannel.open( );
sc.connect (new InetSocketAddress ("somehost", someport));
ServerSocketChannel ssc = ServerSocketChannel.open( );
ssc.socket( ).bind (new InetSocketAddress (somelocalport));
DatagramChannel dc = DatagramChannel.open( );
RandomAccessFile raf = new RandomAccessFile ("somefile", "r");
FileChannel fc = raf.getChannel( );在 3.5 节中您会发现,java.net 的 socket 类也有新的 getChannel( )方法。这些方法虽然能返回一个相应的 socket 通道对象,但它们却并非新通道的来源,RandomAccessFile.getChannel( )方法才是。只有在已经有通道存在的时候,它们才返回与一个 socket 关联的通道;它们永远不会创建新通道。
3.1.2 使用通道
我们在第二章的学习中已经知道了,通道将数据传输给 ByteBuffer 对象或者从 ByteBuffer 对象获取数据进行传输。
将图 3-2 中大部分零乱内容移除可以得到图 3-3 所示的 UML 类图。子接口 API 代码如下:
public interface ReadableByteChannelextends Channel
{
public int read (ByteBuffer dst) throws IOException;
}
public interface WritableByteChannelextends Channel
{
public int write (ByteBuffer src) throws IOException;
}
public interface ByteChannel
extends ReadableByteChannel, WritableByteChannel
{
}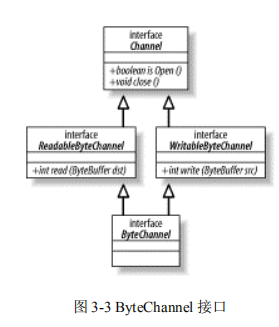
通道可以是单向(unidirectional)或者双向的(bidirectional)。一个 channel 类可能实现定义read( )方法的 ReadableByteChannel 接口,而另一个 channel 类也许实现 WritableByteChannel 接口以提供 write( )方法。实现这两种接口其中之一的类都是单向的,只能在一个方向上传输数据。如果一个类同时实现这两个接口,那么它是双向的,可以双向传输数据。
图 3-3 显示了一个 ByteChannel 接口,该接口引申出了 ReadableByteChannel 和WritableByteChannel 两个接口。ByteChannel 接口本身并不定义新的 API 方法,它是一种用来聚集它自己以一个新名称继承的多个接口的便捷接口。根据定义,实现 ByteChannel 接口的通道会同时实现 ReadableByteChannel 和 WritableByteChannel 两个接口,所以此类通道是双向的。这是简化类定义的语法糖(syntactic sugar),它使得用操作器(operator)实例来测试通道对象变得更加简单。
这是一种好的类设计技巧,如果您在写您自己的 Channel 实现的话,您可以适当地实现这些接口。不过对于使用 java.nio.channels 包中标准通道类的程序员来说,这些接口并没有太大的吸引力。假如您快速回顾一下图 3-2 或者向前跳跃到关于 file 和 socket 通道的章节,您将发现每一个 file 或 socket 通道都实现全部三个接口。从类定义的角度而言,这意味着全部 file 和 socket 通道对象都是双向的。这对于 sockets 不是问题,因为它们一直都是双向的,不过对于 files 却是个问题了。
我们知道,一个文件可以在不同的时候以不同的权限打开。从 FileInputStream 对象的getChannel( )方法获取的 FileChannel 对象是只读的,不过从接口声明的角度来看却是双向的,因为FileChannel 实现 ByteChannel 接口。在这样一个通道上调用 write( )方法将抛出未经检查的NonWritableChannelException 异常,因为 FileInputStream 对象总是以 read-only 的权限打开文件。
通道会连接一个特定 I/O 服务且通道实例(channel instance)的性能受它所连接的 I/O 服务的特征限制,记住这很重要。一个连接到只读文件的 Channel 实例不能进行写操作,即使该实例所属的类可能有 write( )方法。基于此,程序员需要知道通道是如何打开的,避免试图尝试一个底层 I/O服务不允许的操作。
// A ByteBuffer named buffer contains data to be written
FileInputStream input = new FileInputStream (fileName);
FileChannel channel = input.getChannel( );
// This will compile but will throw an IOException
// because the underlying file is read-only
channel.write (buffer);
ByteChannel 的 read( ) 和 write( )方法使用 ByteBuffer 对象作为参数。两种方法均返回已传输的字节数,可能比缓冲区的字节数少甚至可能为零。缓冲区的位置也会发生与已传输字节相同数量的前移。如果只进行了部分传输,缓冲区可以被重新提交给通道并从上次中断的地方继续传输。该过程重复进行直到缓冲区的 hasRemaining( )方法返回 false 值。例 3-1 表示了如何从一个通道复制数据到另一个通道。
package com.ronsoft.books.nio.channels;
import java.nio.ByteBuffer;
import java.nio.channels.ReadableByteChannel;
import java.nio.channels.WritableByteChannel;
import java.nio.channels.Channels;
import java.io.IOException;
/**
* Test copying between channels.
*
* @author Ron Hitchens (ron@ronsoft.com)
*/
public class ChannelCopy
{
/**
* This code copies data from stdin to stdout. Like the 'cat'
* command, but without any useful options.
*/
public static void main (String [] argv)
throws IOException
{
ReadableByteChannel source = Channels.newChannel (System.in);
WritableByteChannel dest = Channels.newChannel (System.out);
channelCopy1 (source, dest);
// alternatively, call channelCopy2 (source, dest);
source.close( );
dest.close( );
}
/**
* Channel copy method 1. This method copies data from the src
* channel and writes it to the dest channel until EOF on src.
* This implementation makes use of compact( ) on the temp buffer
* to pack down the data if the buffer wasn't fully drained. This
* may result in data copying, but minimizes system calls. It also
* requires a cleanup loop to make sure all the data gets sent.
*/
private static void channelCopy1 (ReadableByteChannel src,
WritableByteChannel dest)
throws IOException
{
ByteBuffer buffer = ByteBuffer.allocateDirect (16 * 1024);
while (src.read (buffer) != -1) {
// Prepare the buffer to be drained
buffer.flip( );
// Write to the channel; may block
dest.write (buffer);
// If partial transfer, shift remainder down
// If buffer is empty, same as doing clear( )
buffer.compact( );
}
// EOF will leave buffer in fill state
buffer.flip( );
// Make sure that the buffer is fully drained
while (buffer.hasRemaining( )) {
dest.write (buffer);
}
}
/**
* Channel copy method 2. This method performs the same copy, but
* assures the temp buffer is empty before reading more data. This
* never requires data copying but may result in more systems calls.
* No post-loop cleanup is needed because the buffer will be empty
* when the loop is exited.
*/
private static void channelCopy2 (ReadableByteChannel src,
WritableByteChannel dest)
throws IOException
{
ByteBuffer buffer = ByteBuffer.allocateDirect (16 * 1024);
while (src.read (buffer) != -1) {
// Prepare the buffer to be drained
buffer.flip( );
// Make sure that the buffer was fully drained
while (buffer.hasRemaining( )) {
dest.write (buffer);
}
// Make the buffer empty, ready for filling
buffer.clear( );
}
}
}例 3-1 在通道之间复制数据
通道可以以阻塞(blocking)或非阻塞(nonblocking)模式运行。非阻塞模式的通道永远不会让调用的线程休眠。请求的操作要么立即完成,要么返回一个结果表明未进行任何操作。只有面向流的(stream-oriented)的通道,如 sockets 和 pipes 才能使用非阻塞模式。
从图 3-2 可以看出,socket 通道类从 SelectableChannel 引申而来。从 SelectableChannel 引申而来的类可以和支持有条件的选择(readiness selectio)的选择器(Selectors)一起使用。将非阻塞I/O 和选择器组合起来可以使您的程序利用多路复用 I/O(multiplexed I/O)。选择和多路复用将在第四章中予以讨论。关于怎样将 sockets 置于非阻塞模式的细节会在 3.5 节中涉及。
3.1.3 关闭通道
与缓冲区不同,通道不能被重复使用。一个打开的通道即代表与一个特定 I/O 服务的特定连接并封装该连接的状态。当通道关闭时,那个连接会丢失,然后通道将不再连接任何东西。
package java.nio.channels;
public interface Channel
{
public boolean isOpen( );
public void close( ) throws IOException;
}调用通道的close( )方法时,可能会导致在通道关闭底层I/O服务的过程中线程暂时阻塞 (Socket 通道关闭会花费较长时间,具体时耗取决于操作系统的网络实现。在输出内容被提取时,一些网络协议堆栈可能会阻塞通道的关闭),哪怕该通道处于非阻塞模式。通道关闭时的阻塞行为(如果有的话)是高度取决于操作系统或者文件系统的。在一个通道上多次调用close( )方法是没有坏处的,但是如果第一个线程在close( )方法中阻塞,那么在它完成关闭通道之前,任何其他调用close( )方法都会阻塞。后续在该已关闭的通道上调用close( )不会产生任何操作,只会立即返回。
可以通过 isOpen( )方法来测试通道的开放状态。如果返回 true 值,那么该通道可以使用。如果返回 false 值,那么该通道已关闭,不能再被使用。尝试进行任何需要通道处于开放状态作为前提的操作,如读、写等都会导致 ClosedChannelException 异常。
通道引入了一些与关闭和中断有关的新行为。如果一个通道实现 InterruptibleChannel 接口(参见图 3-2),它的行为以下述语义为准:如果一个线程在一个通道上被阻塞并且同时被中断(由调用该被阻塞线程的 interrupt( )方法的另一个线程中断),那么该通道将被关闭,该被阻塞线程也会产生一个 ClosedByInterruptException 异常。
此外,假如一个线程的 interrupt status 被设置并且该线程试图访问一个通道,那么这个通道将立即被关闭,同时将抛出相同的 ClosedByInterruptException 异常。线程的 interrupt status 在线程的interrupt( )方法被调用时会被设置。我们可以使用 isInterrupted( )来测试某个线程当前的 interrupt status。当前线程的 interrupt status 可以通过调用静态的 Thread.interrupted( )方法清除。

仅仅因为休眠在其上的线程被中断就关闭通道,这看起来似乎过于苛刻了。不过这却是 NIO架构师们所做出的明确的设计决定。经验表明,想要在所有的操作系统上一致而可靠地处理被中断的 I/O 操作是不可能的。 “在全部平台上提供确定的通道行为”这一需求导致了“当 I/O 操作被中断时总是关闭通道”这一设计选择。这个选择被认为是可接受的,因为大部分时候一个线程被中断就是希望以此来关闭通道。 java.nio 包中强制使用此行为来避免因操作系统独特性而导致的困境,因为该困境对 I/O 区域而言是极其危险的。这也是为增强健壮性( robustness)而采用的一种经典的权衡。
可中断的通道也是可以异步关闭的。实现 InterruptibleChannel 接口的通道可以在任何时候被关闭,即使有另一个被阻塞的线程在等待该通道上的一个 I/O 操作完成。当一个通道被关闭时,休眠在该通道上的所有线程都将被唤醒并接收到一个 AsynchronousCloseException 异常。接着通道就被关闭并将不再可用。
不实现 InterruptibleChannel 接口的通道一般都是不进行底层本地代码实现的有特殊用途的通道。这些也许是永远不会阻塞的特殊用途通道,如旧系统数据流的封装包或不能实现可中断语义的writer 类等。(参见 3.7 节)
3.2 Scatter/Gather
通道提供了一种被称为 Scatter/Gather 的重要新功能(有时也被称为矢量 I/O)。 Scatter/Gather是一个简单却强大的概念(参见 1.4.1.1 节),它是指在多个缓冲区上实现一个简单的 I/O 操作。对于一个 write 操作而言,数据是从几个缓冲区按顺序抽取(称为 gather)并沿着通道发送的。缓冲区本身并不需要具备这种 gather 的能力(通常它们也没有此能力)。该 gather 过程的效果就好比全部缓冲区的内容被连结起来,并在发送数据前存放到一个大的缓冲区中。对于 read 操作而言,从通道读取的数据会按顺序被散布(称为 scatter)到多个缓冲区,将每个缓冲区填满直至通道中的数据或者缓冲区的最大空间被消耗完。
大多数现代操作系统都支持本地矢量 I/O( native vectored I/O)。当您在一个通道上请求一个Scatter/Gather 操作时,该请求会被翻译为适当的本地调用来直接填充或抽取缓冲区。这是一个很大的进步,因为减少或避免了缓冲区拷贝和系统调用。 Scatter/Gather 应该使用直接的 ByteBuffers 以从本地 I/O 获取最大性能优势。
将 scatter/gather 接口添加到图 3-3 的 UML 类图中可以得到图 3-4。下面的代码描述了 scatter 是如何扩展读操作的,以及 gather 是如何基于写操作构建的:
public interface ScatteringByteChannel
extends ReadableByteChannel
{
public long read (ByteBuffer [] dsts)
throws IOException;
public long read (ByteBuffer [] dsts, int offset, int length)
throws IOException;
}
public interface GatheringByteChannel
extends WritableByteChannel
{
public long write(ByteBuffer[] srcs)
throws IOException;
public long write(ByteBuffer[] srcs, int offset, int length)
throws IOException;
}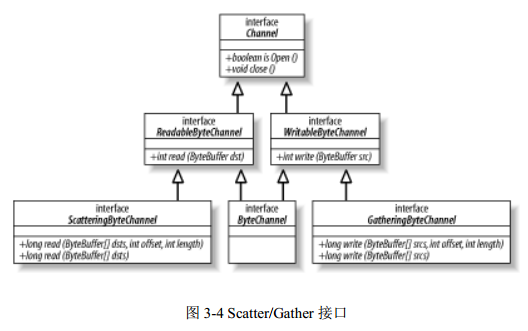
从上图您可以看到,这两个接口都添加了两种以缓冲区阵列作为参数的新方法。另外,每种方法都提供了一种带 offset 和 length 参数的形式。让我们先来理解一下怎样使用方法的简单形式。在下面的代码中,我们假定 channel 连接到一个有 48 字节数据等待读取的 socket 上:
ByteBuffer header = ByteBuffer.allocateDirect (10);
ByteBuffer body = ByteBuffer.allocateDirect (80);
ByteBuffer [] buffers = { header, body };
int bytesRead = channel.read (buffers);一旦 read( )方法返回, bytesRead 就被赋予值 48, header 缓冲区将包含前 10 个从通道读取的字节而 body 缓冲区则包含接下来的 38 个字节。通道会自动地将数据 scatter 到这两个缓冲区中。缓冲区已经被填充了(尽管此例中 body 缓冲区还有空间填充更多数据),那么将需要被 flip 以便其中数据可以被抽取。在类似这样的例子中,我们可能并不会费劲去 flip 这个 header 缓冲区而是以绝对 get 的方式随机访问它以检查各种 header 字段;不过 body 缓冲区会被 flip 并传递到另一个通道的 write( )方法上,然后在通道上发送出去。例如:
switch (header.getShort(0)) {
case TYPE_PING:
break;
case TYPE_FILE:
body.flip( );
fileChannel.write (body);
break;
default:
logUnknownPacket (header.getShort(0), header.getLong(2), body);
break;
}同样,很简单地,我们可以用一个 gather 操作将多个缓冲区的数据组合并发送出去。使用相同的缓冲区,我们可以像下面这样汇总数据并在一个 socket 通道上发送包:
body.clear( );
body.put("FOO".getBytes()).flip( ); // "FOO" as bytes
header.clear( );
header.putShort (TYPE_FILE).putLong (body.limit()).flip( );
long bytesWritten = channel.write (buffers);以上代码从传递给 write( )方法的 buffers 阵列所引用的缓冲区中 gather 数据,然后沿着通道发送了总共 13 个字节。
图 3-5 描述了一个 gather 写操作。数据从缓冲区阵列引用的每个缓冲区中 gather 并被组合成沿着通道发送的字节流。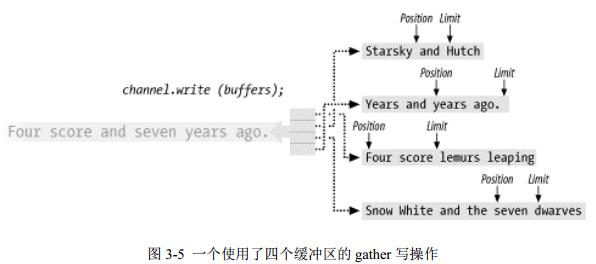
图 3-6 描述了一个 scatter 读操作。从通道传输来的数据被 scatter 到所列缓冲区,依次填充每个缓冲区(从缓冲区的 position 处开始到 limit 处结束)。这里显示的 position 和 limit 值是读操作开始之前的。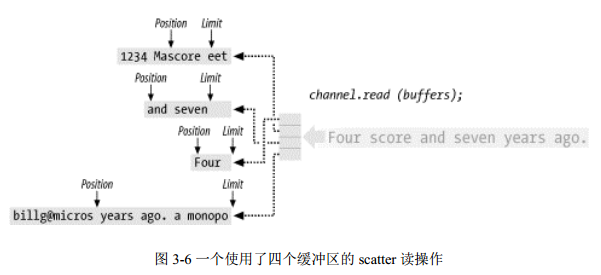
带 offset 和 length 参数版本的 read( ) 和 write( )方法使得我们可以使用缓冲区阵列的子集缓冲区。这里的 offset 值指哪个缓冲区将开始被使用,而不是指数据的 offset。这里的 length 参数指示要使用的缓冲区数量。举个例子,假设我们有一个五元素的 fiveBuffers 阵列,它已经被初始化并引用了五个缓冲区,下面的代码将会写第二个、第三个和第四个缓冲区的内容:
int bytesRead = channel.write (fiveBuffers, 1, 3);使用得当的话, Scatter/Gather 会是一个极其强大的工具。它允许您委托操作系统来完成辛苦活:将读取到的数据分开存放到多个存储桶( bucket)或者将不同的数据区块合并成一个整体。这是一个巨大的成就,因为操作系统已经被高度优化来完成此类工作了。它节省了您来回移动数据的工作,也就避免了缓冲区拷贝和减少了您需要编写、调试的代码数量。既然您基本上通过提供数据容器引用来组合数据,那么按照不同的组合构建多个缓冲区阵列引用,各种数据区块就可以以不同的方式来组合了。例 3-2 很好地诠释了这一点:
package com.ronsoft.books.nio.channels;
import java.nio.ByteBuffer;
import java.nio.channels.GatheringByteChannel;
import java.io.FileOutputStream;
import java.util.Random;
import java.util.List;
import java.util.LinkedList;
/**
* Demonstrate gathering write using many buffers.
*
* @author Ron Hitchens (ron@ronsoft.com)
*/
public class Marketing
{
private static final String DEMOGRAPHIC = "blahblah.txt";
// "Leverage frictionless methodologies"
public static void main (String [] argv)
throws Exception
{
int reps = 10;
if (argv.length > 0) {
reps = Integer.parseInt (argv [0]);
}
FileOutputStream fos = new FileOutputStream (DEMOGRAPHIC);
GatheringByteChannel gatherChannel = fos.getChannel( );
// Generate some brilliant marcom, er, repurposed content
ByteBuffer [] bs = utterBS (reps);
// Deliver the message to the waiting market
while (gatherChannel.write (bs) > 0) {
// Empty body
// Loop until write( ) returns zero
}
System.out.println ("Mindshare paradigms synergized to "
+ DEMOGRAPHIC);
67
fos.close( );
}
// ------------------------------------------------
// These are just representative; add your own
private static String [] col1 = {
"Aggregate", "Enable", "Leverage",
"Facilitate", "Synergize", "Repurpose",
"Strategize", "Reinvent", "Harness"
};
private static String [] col2 = {
"cross-platform", "best-of-breed", "frictionless",
"ubiquitous", "extensible", "compelling",
"mission-critical", "collaborative", "integrated"
};
private static String [] col3 = {
"methodologies", "infomediaries", "platforms",
"schemas", "mindshare", "paradigms",
"functionalities", "web services", "infrastructures"
};
private static String newline = System.getProperty ("line.separator");
// The Marcom-atic 9000
private static ByteBuffer [] utterBS (int howMany)
throws Exception
{
List list = new LinkedList( );
for (int i = 0; i < howMany; i++) {
list.add (pickRandom (col1, " "));
list.add (pickRandom (col2, " "));
list.add (pickRandom (col3, newline));
}
ByteBuffer [] bufs = new ByteBuffer [list.size( )];
list.toArray (bufs);
return (bufs);
}
// The communications director
private static Random rand = new Random( );
// Pick one, make a buffer to hold it and the suffix, load it with
// the byte equivalent of the strings (will not work properly for
68
// non-Latin characters), then flip the loaded buffer so it's ready
// to be drained
private static ByteBuffer pickRandom (String [] strings, String suffix)
throws Exception
{
String string = strings [rand.nextInt (strings.length)];
int total = string.length() + suffix.length( );
ByteBuffer buf = ByteBuffer.allocate (total);
buf.put (string.getBytes ("US-ASCII"));
buf.put (suffix.getBytes ("US-ASCII"));
buf.flip( );
return (buf);
}
}例 3-2 以 gather 写操作来集合多个缓冲区的数据
下面是实现 Marketing 类的输出。虽然这种输出没什么意义,但是 gather 写操作却能让我们
非常高效地把它生成出来。
Aggregate compelling methodologies
Harness collaborative platforms
Aggregate integrated schemas
Aggregate frictionless platforms
Enable integrated platforms
Leverage cross-platform functionalities
Harness extensible paradigms
Synergize compelling infomediaries
Repurpose cross-platform mindshare
Facilitate cross-platform infomediaries3.3 文件通道
直到现在,我们都还只是在泛泛地讨论通道,比如讨论那些对所有通道都适用的内容。是时候具体点了,本节我们来讨论文件通道( socket 通道将在下一节讨论)。从图 3-7 可以发现,FileChannel 类可以实现常用的 read, write 以及 scatter/gather 操作,同时它也提供了很多专用于文件的新方法。这些方法中的许多都是我们所熟悉的文件操作,不过其他的您可能之前并未接触过。现在我们将在此对它们全部予以讨论。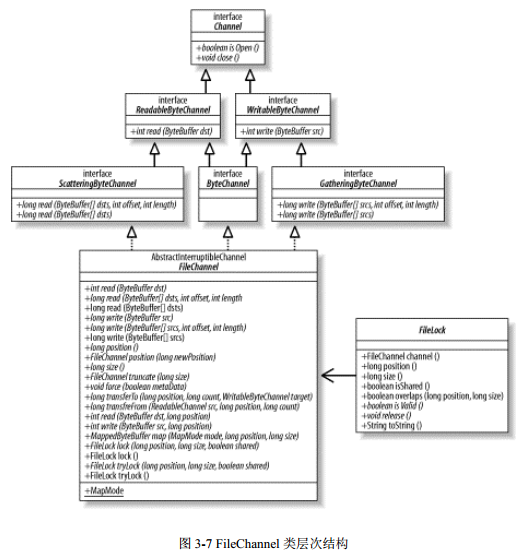
文件通道总是阻塞式的,因此不能被置于非阻塞模式。现代操作系统都有复杂的缓存和预取机制,使得本地磁盘 I/O 操作延迟很少。网络文件系统一般而言延迟会多些,不过却也因该优化而受益。 面向流的 I/O 的非阻塞范例对于面向文件的操作并无多大意义,这是由文件 I/O 本质上的不同性质造成的。对于文件 I/O,最强大之处在于异步 I/O( asynchronous I/O),它允许一个进程可以从操作系统请求一个或多个 I/O 操作而不必等待这些操作的完成。发起请求的进程之后会收到它请求的 I/O 操作已完成的通知。异步 I/O 是一种高级性能,当前的很多操作系统都还不具备。以后的NIO 增强也会把异步 I/O 纳入考虑范围。
我们在 3.1.1 节中提到, FileChannel对象不能直接创建。一个FileChannel实例只能通过在一个打开的file对象( RandomAccessFile、 FileInputStream或 FileOutputStream)上调用getChannel( )方法获取 。调用getChannel( )方法会返回一个连接到相同文件的FileChannel对象且该FileChannel对象具有与file对象相同的访问权限,然后您就可以使用该通道对象来利用强大的FileChannel API了:
package java.nio.channels;
public abstract class FileChannel
extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
// All methods listed here can throw java.io.IOException
public abstract int read (ByteBuffer dst, long position)
public abstract int write (ByteBuffer src, long position)
public abstract long size( )
public abstract long position( )
public abstract void position (long newPosition)
public abstract void truncate (long size)
public abstract void force (boolean metaData)
public final FileLock lock( )
public abstract FileLock lock (long position, long size,
boolean shared)
public final FileLock tryLock( )
public abstract FileLock tryLock (long position, long size,
boolean shared)
public abstract MappedByteBuffer map (MapMode mode, long position,
long size)
public static class MapMode
{
public static final MapMode READ_ONLY
public static final MapMode READ_WRITE
public static final MapMode PRIVATE
}
public abstract long transferTo (long position, long count,
WritableByteChannel target)
public abstract long transferFrom (ReadableByteChannel src,
long position, long count)
}上面的代码中给出了 FileChannel 类引入的新 API 方法。所有这些方法都可以抛出java.io.IOException 异常,不过抛出语句并未在此列出。
同大多数通道一样,只要有可能, FileChannel 都会尝试使用本地 I/O 服务。 FileChannel 类本身是抽象的,您从 getChannel( )方法获取的实际对象是一个具体子类( subclass)的一个实例( instance),该子类可能使用本地代码来实现以上 API 方法中的一些或全部。
FileChannel 对象是线程安全( thread-safe)的。多个进程可以在同一个实例上并发调用方法而不会引起任何问题,不过并非所有的操作都是多线程的( multithreaded)。影响通道位置或者影响文件大小的操作都是单线程的( single-threaded)。如果有一个线程已经在执行会影响通道位置或文件大小的操作,那么其他尝试进行此类操作之一的线程必须等待。并发行为也会受到底层的操作系统或文件系统影响。
同大多数 I/O 相关的类一样, FileChannel 是一个反映 Java 虚拟机外部一个具体对象的抽象。FileChannel 类保证同一个 Java 虚拟机上的所有实例看到的某个文件的视图均是一致的,但是 Java虚拟机却不能对超出它控制范围的因素提供担保。通过一个 FileChannel 实例看到的某个文件的视图同通过一个外部的非 Java 进程看到的该文件的视图可能一致,也可能不一致。多个进程发起的并发文件访问的语义高度取决于底层的操作系统和(或)文件系统。一般而言,由运行在不同 Java虚拟机上的 FileChannel 对象发起的对某个文件的并发访问和由非 Java 进程发起的对该文件的并发访问是一致的。
3.3.1 访问文件
每个 FileChannel 对象都同一个文件描述符( file descriptor)有一对一的关系,所以上面列出的API 方法与在您最喜欢的 POSIX( 可移植操作系统接口) 兼容的操作系统上的常用文件 I/O 系统调用紧密对应也就不足为怪了。名称也许不尽相同,不过常见的 suspect(“ 可疑分子”) 都被集中起来了。您可能也注意到了上面列出的 API 方法同 java.io 包中 RandomAccessFile 类的方法的相似之处了。本质上讲, RandomAccessFile 类提供的是同样的抽象内容。在通道出现之前,底层的文件操作都是通过 RandomAccessFile 类的方法来实现的。 FileChannel 模拟同样的 I/O 服务,因此它的 API 自然也是很相似的。
为了便于比较,表 3-1 列出了 FileChannel、 RandomAccessFile 和 POSIX I/O system calls 三者在方法上的对应关系。
![]()
让我们来进一步看下基本的文件访问方法(请记住这些方法都可以抛出 java.io.IOException 异常):
public abstract class FileChannel
extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
public abstract long position( )
public abstract void position (long newPosition)
public abstract int read (ByteBuffer dst)
public abstract int read (ByteBuffer dst, long position)
public abstract int write (ByteBuffer src)
public abstract int write (ByteBuffer src, long position)
public abstract long size( )
public abstract void truncate (long size)
public abstract void force (boolean metaData)
}同底层的文件描述符一样,每个 FileChannel 都有一个叫“file position”的概念。这个 position 值决定文件中哪一处的数据接下来将被读或者写。从这个方面看, FileChannel 类同缓冲区很类似,并且 MappedByteBuffer 类使得我们可以通过 ByteBuffer API 来访问文件数据(我们会在后面的章节中了解到这一点)。
您可以从前面的API清单中看到,有两种形式的position( )方法。第一种,不带参数的,返回当前文件的position值。返回值是一个长整型( long),表示文件中的当前字节位置 。
第二种形式的 position( )方法带一个 long(长整型) 参数并将通道的 position 设置为指定值。如果尝试将通道 position 设置为一个负值会导致 java.lang.IllegalArgumentException 异常,不过可以把 position 设置到超出文件尾,这样做会把 position 设置为指定值而不改变文件大小。假如在将position 设置为超出当前文件大小时实现了一个 read( )方法,那么会返回一个文件尾( end-of-file)条件;倘若此时实现的是一个 write( )方法则会引起文件增长以容纳写入的字节,具体行为类似于实现一个绝对 write( )并可能导致出现一个文件空洞(file hole,参见“文件空洞究竟是什么? ”)。

FileChannel 位置( position)是从底层的文件描述符获得的,该 position 同时被作为通道引用获取来源的文件对象共享。这也就意味着一个对象对该 position 的更新可以被另一个对象看到:
RandomAccessFile randomAccessFile = new RandomAccessFile ("filename", "r");
// Set the file position
randomAccessFile.seek (1000);
// Create a channel from the file
FileChannel fileChannel = randomAccessFile.getChannel( );
// This will print "1000"
System.out.println ("file pos: " + fileChannel.position( ));
// Change the position using the RandomAccessFile object
randomAccessFile.seek (500);
// This will print "500"
System.out.println ("file pos: " + fileChannel.position( ));
// Change the position using the FileChannel object
fileChannel.position (200);
// This will print "200"
System.out.println ("file pos: " + randomAccessFile.getFilePointer( ));类似于缓冲区的 get( ) 和 put( )方法,当字节被 read( )或 write( )方法传输时,文件 position 会自动更新。如果 position 值达到了文件大小的值(文件大小的值可以通过 size( )方法返回), read( )方法会返回一个文件尾条件值( -1)。可是,不同于缓冲区的是,如果实现 write( )方法时 position前进到超过文件大小的值,该文件会扩展以容纳新写入的字节。
同样类似于缓冲区,也有带 position 参数的绝对形式的 read( )和 write( )方法。这种绝对形式的方法在返回值时不会改变当前的文件 position。由于通道的状态无需更新,因此绝对的读和写可能会更加有效率,操作请求可以直接传到本地代码。更妙的是,多个线程可以并发访问同一个文件而不会相互产生干扰。这是因为每次调用都是原子性的( atomic),并不依靠调用之间系统所记住的状态。
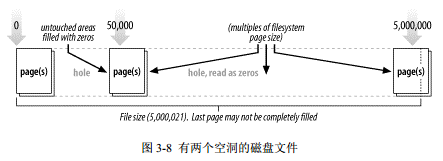
尝试在文件末尾之外的 position 进行一个绝对读操作, size( )方法会返回一个 end-of-file。在超出文件大小的 position 上做一个绝对 write( )会导致文件增加以容纳正在被写入的新字节。文件中位于之前 end-of-file 位置和新添加的字节起始位置之间区域的字节的值不是由 FileChannel 类指定,而是在大多数情况下反映底层文件系统的语义。取决于操作系统和(或)文件系统类型,这可能会导致在文件中出现一个空洞。
当需要减少一个文件的 size 时, truncate( )方法会砍掉您所指定的新 size 值之外的所有数据。如果当前 size 大于新 size,超出新 size 的所有字节都会被悄悄地丢弃。如果提供的新 size 值大于或等于当前的文件 size 值,该文件不会被修改。这两种情况下, truncate( )都会产生副作用:文件的position 会被设置为所提供的新 size 值。
public abstract class FileChannel extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
public abstract void truncate (long size)
public abstract void force (boolean metaData)
}上面列出的最后一个 API 是 force( )。该方法告诉通道强制将全部待定的修改都应用到磁盘的文件上。所有的现代文件系统都会缓存数据和延迟磁盘文件更新以提高性能。调用 force( )方法要求文件的所有待定修改立即同步到磁盘。
如果文件位于一个本地文件系统,那么一旦 force( )方法返回,即可保证从通道被创建(或上次调用 force( ))时起的对文件所做的全部修改已经被写入到磁盘。对于关键操作如事务( transaction)处理来说,这一点是非常重要的,可以保证数据完整性和可靠的恢复。然而,如果文件位于一个远程的文件系统,如 NFS 上,那么不能保证待定修改一定能同步到永久存储器( permanent storage)上,因 Java 虚拟机不能做操作系统或文件系统不能实现的承诺。如果您的程序在面临系统崩溃时必须维持数据完整性,先去验证一下您在使用的操作系统和(或)文件系统在同步修改方面是可以依赖的。
force( )方法的布尔型参数表示在方法返回值前文件的元数据( metadata)是否也要被同步更新到磁盘。元数据指文件所有者、访问权限、最后一次修改时间等信息。大多数情形下,该信息对数据恢复而言是不重要的。给 force( )方法传递 false 值表示在方法返回前只需要同步文件数据的更改。大多数情形下,同步元数据要求操作系统进行至少一次额外的底层 I/O 操作。一些大数量事务处理程序可能通过在每次调用 force( )方法时不要求元数据更新来获取较高的性能提升,同时也不会牺牲数据完整性。
3.3.2 文件锁定
在 JDK 1.4 版本之前, Java I/O 模型都未能提供文件锁定( file locking),缺少这一特性让人们很头疼。绝大多数现代操作系统早就有了文件锁定功能,而直到 JDK 1.4 版本发布时 Java 编程人员才可以使用文件锁( file lock)。在集成许多其他非 Java 程序时,文件锁定显得尤其重要。此外,它在判优( 判断多个访问请求的优先级别) 一个大系统的多个 Java 组件发起的访问时也很有价值。
我们在第一章中讨论到,锁( lock)可以是共享的( shared)或独占的( exclusive)。本节中描述的文件锁定特性在很大程度上依赖本地的操作系统实现。并非所有的操作系统和文件系统都支持共享文件锁。对于那些不支持的,对一个共享锁的请求会被自动提升为对独占锁的请求。这可以保证准确性却可能严重影响性能。举个例子,仅使用独占锁将会串行化图 1-7 中所列的全部 reader 进程。如果您计划部署程序,请确保您了解所用操作系统和文件系统的文件锁定行为,因为这将严重影响您的设计选择。
另外,并非所有平台都以同一个方式来实现基本的文件锁定。在不同的操作系统上,甚至在同一个操作系统的不同文件系统上,文件锁定的语义都会有所差异。一些操作系统仅提供劝告锁定( advisory locking) ,一些仅提供独占锁( exclusive locks),而有些操作系统可能两种锁都提供。您应该总是按照劝告锁的假定来管理文件锁,因为这是最安全的。但是如能了解底层操作系统如何执行锁定也是非常好的。例如,如果所有的锁都是强制性的( mandatory)而您不及时释放您获得的锁的话,运行在同一操作系统上的其他程序可能会受到影响。
有关 FileChannel 实现的文件锁定模型的一个重要注意项是:锁的对象是文件而不是通道或线程,这意味着文件锁不适用于判优同一台 Java 虚拟机上的多个线程发起的访问。
如果一个线程在某个文件上获得了一个独占锁,然后第二个线程利用一个单独打开的通道来请求该文件的独占锁,那么第二个线程的请求会被批准。但如果这两个线程运行在不同的 Java 虚拟机上,那么第二个线程会阻塞,因为锁最终是由操作系统或文件系统来判优的并且几乎总是在进程级而非线程级上判优。锁都是与一个文件关联的,而不是与单个的文件句柄或通道关联。

文件锁旨在在进程级别上判优文件访问,比如在主要的程序组件之间或者在集成其他供应商的组件时。如果您需要控制多个 Java 线程的并发访问,您可能需要实施您自己的、轻量级的锁定方案。那种情形下,内存映射文件(本章后面会进行详述)可能是一个合适的选择。
现在让我们来看下与文件锁定有关的 FileChannel API 方法:
public abstract class FileChannel
extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
public final FileLock lock( )
public abstract FileLock lock (long position, long size,
boolean shared)
public final FileLock tryLock( )
public abstract FileLock tryLock (long position, long size,
boolean shared)
}这次我们先看带参数形式的 lock( )方法。 锁是在文件内部区域上获得的。调用带参数的 Lock( )方法会指定文件内部锁定区域的开始 position 以及锁定区域的 size。第三个参数 shared 表示您想获取的锁是共享的(参数值为 true)还是独占的(参数值为 false)。要获得一个共享锁,您必须先以只读权限打开文件,而请求独占锁时则需要写权限。另外,您提供的 position和 size 参数的值不能是负数。
锁定区域的范围不一定要限制在文件的 size 值以内,锁可以扩展从而超出文件尾。因此,我们
可以提前把待写入数据的区域锁定,我们也可以锁定一个不包含任何文件内容的区域,比如文件最
后一个字节以外的区域。如果之后文件增长到达那块区域,那么您的文件锁就可以保护该区域的文
件内容了。相反地,如果您锁定了文件的某一块区域,然后文件增长超出了那块区域,那么新增加
的文件内容将不会受到您的文件锁的保护。
不带参数的简单形式的 lock( )方法是一种在整个文件上请求独占锁的便捷方法,锁定区域等于
它能达到的最大范围。该方法等价于:
fileChannel.lock (0L, Long.MAX_VALUE, false);
如果您正请求的锁定范围是有效的,那么 lock( )方法会阻塞,它必须等待前面的锁被释放。假
如您的线程在此情形下被暂停,该线程的行为受中断语义(类似我们在 3.1.3 节中所讨论的)控
制。如果通道被另外一个线程关闭,该暂停线程将恢复并产生一个 AsynchronousCloseException 异
常。假如该暂停线程被直接中断(通过调用它的 interrupt( )方法),它将醒来并产生一个
FileLockInterruptionException 异常。如果在调用 lock( )方法时线程的 interrupt status 已经被设置,也
会产生 FileLockInterruptionException 异常。
在上面的 API 列表中有两个名为 tryLock( )的方法,它们是 lock( )方法的非阻塞变体。这两个
tryLock( )和 lock( )方法起相同的作用,不过如果请求的锁不能立即获取到则会返回一个 null。
您可以看到, lock( )和 tryLock( )方法均返回一个 FileLock 对象。以下是完整的 FileLock API:
public abstract class FileLock
{
public final FileChannel channel( )
public final long position( )
public final long size( )
public final boolean isShared( )
public final boolean overlaps (long position, long size)
public abstract boolean isValid( );
public abstract void release( ) throws IOException;
}FileLock 类封装一个锁定的文件区域。 FileLock 对象由 FileChannel 创建并且总是关联到那个特定的通道实例。您可以通过调用 channel( )方法来查询一个 lock 对象以判断它是由哪个通道创建的。
一个 FileLock 对象创建之后即有效,直到它的 release( )方法被调用或它所关联的通道被关闭或Java 虚拟机关闭时才会失效。我们可以通过调用 isValid( )布尔方法来测试一个锁的有效性。一个锁的有效性可能会随着时间而改变,不过它的其他属性——位置( position)、范围大小( size)和独占性( exclusivity) ——在创建时即被确定,不会随着时间而改变。
您可以通过调用 isShared( )方法来测试一个锁以判断它是共享的还是独占的。如果底层的操作系统或文件系统不支持共享锁,那么该方法将总是返回 false 值,即使您申请锁时传递的参数值是 true。假如您的程序依赖共享锁定行为,请测试返回的锁以确保您得到了您申请的锁类型。FileLock 对象是线程安全的,多个线程可以并发访问一个锁对象。
最后,您可以通过调用 overlaps( )方法来查询一个 FileLock 对象是否与一个指定的文件区域重叠。这将使您可以迅速判断您拥有的锁是否与一个感兴趣的区域( region of interest)有交叉。不过即使返回值是 false 也不能保证您就一定能在期望的区域上获得一个锁,因为 Java 虚拟机上的其他地方或者外部进程可能已经在该期望区域上有一个或多个锁了。您最好使用 tryLock( )方法确认一下。
尽管一个 FileLock 对象是与某个特定的 FileChannel 实例关联的,它所代表的锁却是与一个底层文件关联的,而不是与通道关联。因此,如果您在使用完一个锁后而不释放它的话,可能会导致冲突或者死锁。请小心管理文件锁以避免出现此问题。一旦您成功地获取了一个文件锁,如果随后在通道上出现错误的话,请务必释放这个锁。推荐使用类似下面的代码形式:
FileLock lock = fileChannel.lock( )
try {
<perform read/write/whatever on channel>
} catch (IOException) [
<handle unexpected exception>
} finally {
lock.release( )
}例 3-3 中的代码使用共享锁实现了 reader 进程,使用独占锁实现了 writer 进程,图 1-7 和图 1-8对此有诠释。由于锁是与进程而不是 Java 线程关联的,您将需要运行该程序的多个拷贝。先从一个 writer 和两个或更多的 readers 开始,我们来看下不同类型的锁是如何交互的。
package com.ronsoft.books.nio.channels;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileLock;
import java.io.RandomAccessFile;
import java.util.Random;
/**
* Test locking with FileChannel.
* Run one copy of this code with arguments "-w /tmp/locktest.dat"
* and one or more copies with "-r /tmp/locktest.dat" to see the
* interactions of exclusive and shared locks. Note how too many
* readers can starve out the writer.
* Note: The filename you provide will be overwritten. Substitute
* an appropriate temp filename for your favorite OS.
*
* Created April, 2002
* @author Ron Hitchens (ron@ronsoft.com)
*/
public class LockTest
{
private static final int SIZEOF_INT = 4;
private static final int INDEX_START = 0;
private static final int INDEX_COUNT = 10;
private static final int INDEX_SIZE = INDEX_COUNT * SIZEOF_INT;
private ByteBuffer buffer = ByteBuffer.allocate (INDEX_SIZE);
private IntBuffer indexBuffer = buffer.asIntBuffer( );
private Random rand = new Random( );
public static void main (String [] argv)
throws Exception
{
boolean writer = false;
String filename;
if (argv.length != 2) {
System.out.println ("Usage: [ -r | -w ] filename");
return;
}
writer = argv [0].equals ("-w");
filename = argv [1];
RandomAccessFile raf = new RandomAccessFile (filename,
(writer) ? "rw" : "r");
FileChannel fc = raf.getChannel( );
LockTest lockTest = new LockTest( );
if (writer) {
lockTest.doUpdates (fc);
} else {
lockTest.doQueries (fc);
}
}
// ----------------------------------------------------------------
// Simulate a series of read-only queries while
// holding a shared lock on the index area
void doQueries (FileChannel fc)
throws Exception
{
while (true) {
println ("trying for shared lock...");
FileLock lock = fc.lock (INDEX_START, INDEX_SIZE, true);
int reps = rand.nextInt (60) + 20;
for (int i = 0; i < reps; i++) {
int n = rand.nextInt (INDEX_COUNT);
int position = INDEX_START + (n * SIZEOF_INT);
buffer.clear( );
fc.read (buffer, position);
int value = indexBuffer.get (n);
println ("Index entry " + n + "=" + value);
// Pretend to be doing some work
Thread.sleep (100);
}
lock.release( );
println ("<sleeping>");
Thread.sleep (rand.nextInt (3000) + 500);
}
}
// Simulate a series of updates to the index area
// while holding an exclusive lock
void doUpdates (FileChannel fc)
throws Exception
{
while (true) {
println ("trying for exclusive lock...");
FileLock lock = fc.lock (INDEX_START,
INDEX_SIZE, false);
updateIndex (fc);
lock.release( );
println ("<sleeping>");
Thread.sleep (rand.nextInt (2000) + 500);
}
}
// Write new values to the index slots
private int idxval = 1;
private void updateIndex (FileChannel fc)
throws Exception
{
// "indexBuffer" is an int view of "buffer"
indexBuffer.clear( );
for (int i = 0; i < INDEX_COUNT; i++) {
idxval++;
println ("Updating index " + i + "=" + idxval);
indexBuffer.put (idxval);
// Pretend that this is really hard work
Thread.sleep (500);
}
// leaves position and limit correct for whole buffer
buffer.clear( );
fc.write (buffer, INDEX_START);
}
// ----------------------------------------------------------------
private int lastLineLen = 0;
// Specialized println that repaints the current line
private void println (String msg)
{
System.out.print ("\r ");
System.out.print (msg);
for (int i = msg.length( ); i < lastLineLen; i++) {
System.out.print (" ");
}
System.out.print ("\r");
System.out.flush( );
lastLineLen = msg.length( );
}
}例 3-3 共享锁同独占锁交互
以上代码直接忽略了我之前说给的用 try/catch/finally 来释放锁的建议,在您自己所写的实际代码中请不要这么懒。
3.4 内存映射文件 TODO
3.5 Socket通道
现在让我们来学习模拟网络套接字的通道类。 Socket 通道有与文件通道不同的特征。
新的 socket 通道类可以运行非阻塞模式并且是可选择的。这两个性能可以激活大程序(如网络服务器和中间件组件)巨大的可伸缩性和灵活性。本节中我们会看到,再也没有为每个 socket 连接使用一个线程的必要了,也避免了管理大量线程所需的上下文交换总开销。借助新的 NIO 类,一个或几个线程就可以管理成百上千的活动 socket 连接了并且只有很少甚至可能没有性能损失。
从图 3-9 可知,全部 socket 通道类( DatagramChannel、 SocketChannel 和ServerSocketChannel)都是由位于 java.nio.channels.spi 包中的 AbstractSelectableChannel 引申而来。这意味着我们可以用一个 Selector 对象来执行 socket 通道的有条件的选择( readiness selection)。选择和多路复用 I/O 会在第四章中讨论。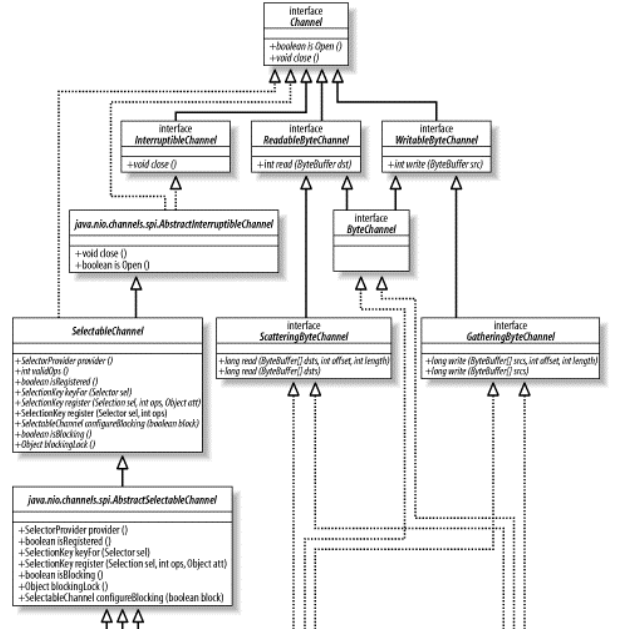
请注意 DatagramChannel 和 SocketChannel 实现定义读和写功能的接口而 ServerSocketChannel不实现。 ServerSocketChannel 负责监听传入的连接和创建新的 SocketChannel 对象,它本身从不传输数据。
在我们具体讨论每一种 socket 通道前,您应该了解 socket 和 socket 通道之间的关系。之前的章节中有写道,通道是一个连接 I/O 服务导管并提供与该服务交互的方法。就某个 socket 而言,它不会再次实现与之对应的 socket 通道类中的 socket 协议 API,而 java.net 中已经存在的 socket 通道都可以被大多数协议操作重复使用。
全部 socket 通道类( DatagramChannel、 SocketChannel 和 ServerSocketChannel)在被实例化时都会创建一个对等 socket 对象。这些是我们所熟悉的来自 java.net 的类( Socket、 ServerSocket和 DatagramSocket),它们已经被更新以识别通道。对等 socket 可以通过调用 socket( )方法从一个通道上获取。此外,这三个 java.net 类现在都有 getChannel( )方法。
虽然每个 socket 通道(在 java.nio.channels 包中)都有一个关联的 java.net socket 对象,却并非所有的 socket 都有一个关联的通道。如果您用传统方式(直接实例化)创建了一个Socket 对象,它就不会有关联的 SocketChannel 并且它的 getChannel( )方法将总是返回 null。
Socket 通道委派协议操作给对等 socket 对象。如果在通道类中存在似乎重复的 socket 方法,那么将有某个新的或者不同的行为同通道类上的这个方法相关联。
3.5.1 非阻塞模式
Socket 通道可以在非阻塞模式下运行。这个陈述虽然简单却有着深远的含义。传统 Java socket的阻塞性质曾经是 Java 程序可伸缩性的最重要制约之一。非阻塞 I/O 是许多复杂的、高性能的程序构建的基础。
要把一个 socket 通道置于非阻塞模式,我们要依靠所有 socket 通道类的公有超级类:SelectableChannel。下面的方法就是关于通道的阻塞模式的:
public abstract class SelectableChannel extends AbstractChannel implements Channel
{
// This is a partial API listing
public abstract void configureBlocking (boolean block)
throws IOException;
public abstract boolean isBlocking( );
public abstract Object blockingLock( );
}有条件的选择( readiness selection)是一种可以用来查询通道的机制,该查询可以判断通道是否准备好执行一个目标操作,如读或写。非阻塞 I/O 和可选择性是紧密相连的,那也正是管理阻塞模式的 API 代码要在 SelectableChannel 超级类中定义的原因。 SelectableChannel 的剩余 API 将在第四章中讨论。
设置或重新设置一个通道的阻塞模式是很简单的,只要调用 configureBlocking( )方法即可,传递参数值为 true 则设为阻塞模式,参数值为 false 值设为非阻塞模式。真的,就这么简单!您可以通过调用 isBlocking( )方法来判断某个 socket 通道当前处于哪种模式:
SocketChannel sc = SocketChannel.open( );
sc.configureBlocking (false); // nonblocking
...
if ( ! sc.isBlocking( )) {
doSomething (cs);
}服务器端的使用经常会考虑到非阻塞 socket 通道,因为它们使同时管理很多 socket 通道变得更容易。但是,在客户端使用一个或几个非阻塞模式的 socket 通道也是有益处的,例如,借助非阻塞socket 通道, GUI 程序可以专注于用户请求并且同时维护与一个或多个服务器的会话。在很多程序上,非阻塞模式都是有用的。
偶尔地,我们也会需要防止 socket 通道的阻塞模式被更改。 API 中有一个 blockingLock( )方法,该方法会返回一个非透明的对象引用。返回的对象是通道实现修改阻塞模式时内部使用的。只有拥有此对象的锁的线程才能更改通道的阻塞模式(对象的锁是用同步的 Java 密码获取的,它不同于我们在 3.3 节中介绍的 lock( )方法)。对于确保在执行代码的关键部分时 socket 通道的阻塞模式不会改变以及在不影响其他线程的前提下暂时改变阻塞模式来说,这个方法都是非常方便的。
Socket socket = null;
Object lockObj = serverChannel.blockingLock( );
// have a handle to the lock object, but haven't locked it yet
// may block here until lock is acquired
synchronize (lockObj)
{
// This thread now owns the lock; mode can't be changed
boolean prevState = serverChannel.isBlocking( );
serverChannel.configureBlocking (false);
socket = serverChannel.accept( );
serverChannel.configureBlocking (prevState);
}
// lock is now released, mode is allowed to change
if (socket != null) {
doSomethingWithTheSocket (socket);
}3.5.2 ServerSocketChannel
让我们从最简单的 ServerSocketChannel 来开始对 socket 通道类的讨论。以下是ServerSocketChannel 的完整 API:
public abstract class ServerSocketChannel extends AbstractSelectableChannel
{
public static ServerSocketChannel open( ) throws IOException
public abstract ServerSocket socket( );
public abstract ServerSocket accept( ) throws IOException;
public final int validOps( )
}ServerSocketChannel 是一个基于通道的 socket 监听器。它同我们所熟悉的 java.net.ServerSocket执行相同的基本任务,不过它增加了通道语义,因此能够在非阻塞模式下运行。
用静态的 open( )工厂方法创建一个新的 ServerSocketChannel 对象,将会返回同一个未绑定的java.net.ServerSocket 关联的通道。该对等 ServerSocket 可以通过在返回的 ServerSocketChannel 上调
用 socket( )方法来获取。作为 ServerSocketChannel 的对等体被创建的 ServerSocket 对象依赖通道实现。这些 socket 关联的 SocketImpl 能识别通道。通道不能被封装在随意的 socket 对象外面。
由于 ServerSocketChannel 没有 bind( )方法(Java7之后API提供bind方法),因此有必要取出对等的 socket 并使用它来绑定到一个端口以开始监听连接。我们也是使用对等 ServerSocket 的 API 来根据需要设置其他的 socket 选项。
ServerSocketChannel ssc = ServerSocketChannel.open( );
ServerSocket serverSocket = ssc.socket( );
// Listen on port 1234
serverSocket.bind (new InetSocketAddress (1234));同它的对等体 java.net.ServerSocket 一样, ServerSocketChannel 也有 accept( )方法。一旦您创建了一个 ServerSocketChannel 并用对等 socket 绑定了它,然后您就可以在其中一个上(socket或者channel上)调用 accept( )。如果您选择在 ServerSocket 上调用 accept( )方法,那么它会同任何其他的 ServerSocket 表现一样的行为:总是阻塞并返回一个 java.net.Socket 对象。如果您选择在 ServerSocketChannel 上调用 accept( )方法则会返回 SocketChannel 类型的对象,返回的对象能够在非阻塞模式下运行。假设系统已经有一个安全管理器( security manager),两种形式的方法调用都执行相同的安全检查。
如果以非阻塞模式被调用,当没有传入连接在等待时, ServerSocketChannel.accept( )会立即返回 null。正是这种检查连接而不阻塞的能力实现了可伸缩性并降低了复杂性。可选择性也因此得到实现。我们可以使用一个选择器实例来注册一个 ServerSocketChannel 对象以实现新连接到达时自动通知的功能。例 3-7 演示了如何使用一个非阻塞的 accept( )方法:
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
/**
* Created with IntelliJ IDEA.
* Description:
* User: zhubo
* Date: 2018-01-15
* Time: 14:00
*/
public class ChannelAccept {
private static final String GREETING="Hello I must be going.\r\n";
public static void main(String[] args) throws Exception{
int port = 1234;
if(args.length > 0){
port = Integer.parseInt(args[0]);
}
ByteBuffer buffer = ByteBuffer.wrap(GREETING.getBytes());
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(port));
ssc.socket().bind(new InetSocketAddress(port));
ssc.configureBlocking(false);
while(true){
System.out.println("Waiting for connections");
SocketChannel sc = ssc.accept();//循环调用,如果没有连接则会返回null,不进行阻塞
if(sc == null){
System.out.println("==========Sleeping==========");
Thread.sleep(2000);
}else{
System.out.println("Incoming connection from : " +
sc.socket().getRemoteSocketAddress());
buffer.rewind();
sc.write(buffer);
sc.close();
}
}
}
}例 3-7 使用 ServerSocketChannel 的非阻塞 accept( )方法
前面列出的最后一个方法 validOps( )是同选择器一起使用的。关于选择器,我们将在第四章中予以详细讨论并且会介绍到 validOps( )方法。
3.5.3 SocketChannel
下面开始学习 SocketChannel,它是使用最多的 socket 通道类:
public abstract class SocketChannel extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel
{
// This is a partial API listing
public static SocketChannel open( ) throws IOException
public static SocketChannel open (InetSocketAddress remote) throws IOException
public abstract Socket socket( );
public abstract boolean connect (SocketAddress remote) throws IOException;
public abstract boolean isConnectionPending( );
public abstract boolean finishConnect( ) throws IOException;
public abstract boolean isConnected( );
public final int validOps( )
}Socket 和 SocketChannel 类封装点对点、有序的网络连接,类似于我们所熟知并喜爱的 TCP/IP网络连接。 SocketChannel 扮演客户端发起同一个监听服务器的连接。直到连接成功,它才能收到数据并且只会从连接到的地址接收。(对于 ServerSocketChannel,由于涉及到 validOps( )方法,我们将在第四章检查选择器时进行讨论。通用的 read/write 方法也未在此列出,详情请参考 3.1.2节。)
每个 SocketChannel 对象创建时都是同一个对等的 java.net.Socket 对象串联的。静态的 open( )方法可以创建一个新的 SocketChannel 对象,而在新创建的 SocketChannel 上调用 socket( )方法能返回它对等的 Socket 对象;在该 Socket 上调用 getChannel( )方法则能返回最初的那个 SocketChannel。
新创建的 SocketChannel 虽已打开却是未连接的。在一个未连接的 SocketChannel 对象上尝试一个 I/O 操作会导致 NotYetConnectedException 异常。我们可以通过在通道上直接调用 connect( )方法或在通道关联的 Socket 对象上调用 connect( )来将该 socket 通道连接。一旦一个 socket 通道被连接,它将保持连接状态直到被关闭。您可以通过调用布尔型的 isConnected( )方法来测试某个SocketChannel 当前是否已连接。
第二种带 InetSocketAddress 参数形式的 open( )是在返回之前进行连接的便捷方法。这段代码:
SocketChannel socketChannel =
SocketChannel.open (new InetSocketAddress ("somehost", somePort));等价于下面这段代码:
SocketChannel socketChannel = SocketChannel.open( );
socketChannel.connect (new InetSocketAddress ("somehost", somePort));如果您选择使用传统方式进行连接——通过在对等 Socket 对象上调用 connect( )方法,那么传统的连接语义将适用于此。线程在连接建立好或超时过期之前都将保持阻塞。如果您选择通过在通道上直接调用 connect( )方法来建立连接并且通道处于阻塞模式(默认模式),那么连接过程实际上是一样的。
在 SocketChannel 上并没有一种 connect( )方法可以让您指定超时( timeout)值,当 connect( )方
法在非阻塞模式下被调用时 SocketChannel 提供并发连接:它发起对请求地址的连接并且立即返回
值。如果返回值是 true,说明连接立即建立了(这可能是本地环回连接);如果连接不能立即建立, connect( )方法会返回 false 且并发地继续连接建立过程。
面向流的的 socket 建立连接状态需要一定的时间,因为两个待连接系统之间必须进行包对话以建立维护流 socket 所需的状态信息。跨越开放互联网连接到远程系统会特别耗时。假如某个(非阻塞)SocketChannel 上当前正由一个并发连接, isConnectPending( )方法就会返回 true 值(非阻塞模式下未连接完成状态下返回true,完结完成会返回false)。
调用 finishConnect( )方法来完成连接过程,该方法任何时候都可以安全地进行调用。假如在一个非阻塞模式的 SocketChannel 对象上调用 finishConnect( )方法,将可能出现下列情形之一:
- connect( )方法尚未被调用。那么将产生 NoConnectionPendingException 异常。
- 连接建立过程正在进行,尚未完成。那么什么都不会发生, finishConnect( )方法会立即返回false 值。
- 在非阻塞模式下调用 connect( )方法之后, SocketChannel 又被切换回了阻塞模式。那么如果有必要的话,调用线程会阻塞直到连接建立完成, finishConnect( )方法接着就会返回 true值。
- 在初次调用 connect( )或最后一次调用 finishConnect( )之后,连接建立过程已经完成。那么SocketChannel 对象的内部状态将被更新到已连接状态, finishConnect( )方法会返回 true值,然后 SocketChannel 对象就可以被用来传输数据了。
- 连接已经建立。那么什么都不会发生, finishConnect( )方法会返回 true 值。
当通道处于中间的连接等待( connection-pending)状态时,您只可以调用 finishConnect( )、isConnectPending( )或 isConnected( )方法。一旦连接建立过程成功完成, isConnected( )将返回 true值。
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
/**
* Created with IntelliJ IDEA.
* Description:
* User: zhubo
* Date: 2018-01-15
* Time: 15:00
*/
public class SocketChannelApp {
public static void main(String[] args) throws Exception{
InetSocketAddress addr = new InetSocketAddress("127.0.0.1",9990);
SocketChannel sc = SocketChannel.open();
sc.configureBlocking(false);
sc.connect(addr);
while (!sc.finishConnect()){
doSomethings();
}
if(sc.isConnectionPending()){//如果是并发连接异步,并且还正在连接时(连接还没完成时) , 返回true
System.out.println("isConnectionPending");
}
if(sc.isConnected()){
System.out.println("isConnected");
}
ByteBuffer buffer = ByteBuffer.wrap(new String("Hello server !").getBytes());
sc.write(buffer);
sc.close();
}
private static void doSomethings(){
System.out.println("do someing useless ! ");
}
}import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
/**
* Created with IntelliJ IDEA.
* Description:
* User: zhubo
* Date: 2018-01-15
* Time: 15:04
*/
public class ServerSocketChannelApp {
private static final String MSG = "hello , I must be going \n";
public static void main(String[] args) throws Exception {
int port = 9990;
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.bind(new InetSocketAddress(port));
ByteBuffer buffer = ByteBuffer.wrap(MSG.getBytes());
while (true){
SocketChannel sc = ssc.accept();
if(sc == null){
Thread.sleep(1000);
}else{
System.out.println("Incoming connection from " + sc.socket().getRemoteSocketAddress());
ByteBuffer readerBuffer = ByteBuffer.allocate(1024);
sc.read(readerBuffer);
readerBuffer.flip();
out(readerBuffer);
buffer.rewind();
sc.write(buffer);
sc.close();
}
}
}
private static void out(ByteBuffer readBuffer){
StringBuffer sb = new StringBuffer();
for(int i = 0 ; i < readBuffer.limit() ; i++){
char c = (char) readBuffer.get();
sb.append(c);
}
System.out.println(sb.toString());
}
}例 3-8 建立并发连接
如果尝试异步连接失败,那么下次调用 finishConnect( )方法会产生一个适当的经检查的异常以指出问题的性质。通道然后就会被关闭并将不能被连接或再次使用。
与连接相关的方法使得我们可以对一个通道进行轮询并在连接进行过程中判断通道所处的状态。 第四章中,我们将了解到如何使用选择器来避免进行轮询并在异步连接建立之后收到通知。
Socket 通道是线程安全的。并发访问时无需特别措施来保护发起访问的多个线程,不过任何时候都只有一个读操作和一个写操作在进行中。请记住, sockets 是面向流的而非包导向的。它们可以保证发送的字节会按照顺序到达但无法承诺维持字节分组。某个发送器可能给一个 socket 写入了20 个字节,而接收器调用 read( )方法时却只收到了其中的 3 个字节。剩下的 17 个字节还是传输中。
由于这个原因,让多个不配合的线程共享某个流 socket 的同一侧绝非一个好的设计选择。connect( )和 finishConnect( )方法是互相同步的,并且只要其中一个操作正在进行,任何读或写的方法调用都会阻塞,即使是在非阻塞模式下。如果此情形下您有疑问或不能承受一个读或写操作在某个通道上阻塞,请用 isConnected( )方法测试一下连接状态。
3.5.4 DatagramChannel
最后一个 socket 通道是 DatagramChannel。正如 SocketChannel 对应 Socket,ServerSocketChannel 对应 ServerSocket,每一个 DatagramChannel 对象也有一个关联的DatagramSocket 对象。不过原命名模式在此并未适用:“ DatagramSocketChannel”显得有点笨拙,因此采用了简洁的“ DatagramChannel”名称。
正如 SocketChannel 模拟连接导向的流协议(如 TCP/IP), DatagramChannel 则模拟包导向的无连接协议(如 UDP/IP):
public abstract class DatagramChannel extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel
{
// This is a partial API listing
public static DatagramChannel open() throws IOException
public abstract DatagramSocket socket();
public abstract DatagramChannel connect (SocketAddress remote) throws IOException;
public abstract boolean isConnected();
public abstract DatagramChannel disconnect() throws IOException;
public abstract SocketAddress receive (ByteBuffer dst) throws IOException;
public abstract int send (ByteBuffer src, SocketAddress target)
public abstract int read (ByteBuffer dst) throws IOException;
public abstract long read (ByteBuffer [] dsts) throws IOException;
public abstract long read (ByteBuffer [] dsts, int offset, int length) throws IOException;
public abstract int write (ByteBuffer src) throws IOException;
public abstract long write(ByteBuffer[] srcs) throws IOException;
public abstract long write(ByteBuffer[] srcs, int offset, int length) throws IOException;
}创建 DatagramChannel 的模式和创建其他 socket 通道是一样的:调用静态的 open( )方法来创建一个新实例。新 DatagramChannel 会有一个可以通过调用 socket( )方法获取的对等 DatagramSocket对象。 DatagramChannel 对象既可以充当服务器(监听者)也可以充当客户端(发送者)。如果您希望新创建的通道负责监听,那么通道必须首先被绑定到一个端口或地址/端口组合上。绑定DatagramChannel 同绑定一个常规的 DatagramSocket 没什么区别,都是委托对等 socket 对象上的API 实现的:
DatagramChannel channel = DatagramChannel.open( );
DatagramSocket socket = channel.socket( );
socket.bind (new InetSocketAddress (portNumber));DatagramChannel 是无连接的。每个数据报( datagram)都是一个自包含的实体,拥有它自己的目的地址及不依赖其他数据报的数据净荷。与面向流的的 socket 不同, DatagramChannel 可以发送单独的数据报给不同的目的地址。同样, DatagramChannel 对象也可以接收来自任意地址的数据包。每个到达的数据报都含有关于它来自何处的信息(源地址)。
一个未绑定的 DatagramChannel 仍能接收数据包。当一个底层 socket 被创建时,一个动态生成的端口号就会分配给它。绑定行为要求通道关联的端口被设置为一个特定的值(此过程可能涉及安全检查或其他验证)。不论通道是否绑定,所有发送的包都含有 DatagramChannel 的源地址(带端口号)。未绑定的 DatagramChannel 可以接收发送给它的端口的包,通常是来回应该通道之前发出的一个包。已绑定的通道接收发送给它们所绑定的熟知端口( wellknown port)的包。数据的实际发送或接收是通过 send()和 receive()方法来实现的:
public abstract class DatagramChannel extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel
{
// This is a partial API listing
public abstract SocketAddress receive (ByteBuffer dst) throws IOException;
public abstract int send (ByteBuffer src, SocketAddress target)
}receive()方法将下次将传入的数据报的数据净荷复制到预备好的 ByteBuffer 中并返回一个SocketAddress 对象以指出数据来源。如果通道处于阻塞模式, receive( )可能无限期地休眠直到有包到达。如果是非阻塞模式,当没有可接收的包时则会返回 null。如果包内的数据超出缓冲区能承受的范围,多出的数据都会被悄悄地丢弃。
 _|_|_|_|_|_|_|_|_|_|_
_|_|_|_|_|_|_|_|_|_|_
调用 send( )会发送给定 ByteBuffer 对象的内容到给定 SocketAddress 对象所描述的目的地址和端口,内容范围为从当前 position 开始到末尾处结束。如果 DatagramChannel 对象处于阻塞模式,调用线程可能会休眠直到数据报被加入传输队列。如果通道是非阻塞的,返回值要么是字节缓冲区的字节数,要么是“ 0”。发送数据报是一个全有或全无( all-or-nothing)的行为。如果传输队列没有足够空间来承载整个数据报,那么什么内容都不会被发送。
如果安装了安全管理器,那么每次调用 send( )或 receive( )时安全管理器的 checkConnect( )方法都会被调用以验证目的地址,除非通道处于已连接的状态(本节后面会讨论到)。
请注意,数据报协议的不可靠性是固有的,它们不对数据传输做保证。 send( )方法返回的非零值并不表示数据报到达了目的地,仅代表数据报被成功加到本地网络层的传输队列。此外,传输过程中的协议可能将数据报分解成碎片。例如,以太网不能传输超过 1,500 个字节左右的包。如果您的数据报比较大,那么就会存在被分解成碎片的风险,成倍地增加了传输过程中包丢失的几率。被分解的数据报在目的地会被重新组合起来,接收者将看不到碎片。但是,如果有一个碎片不能按时到达,那么整个数据报将被丢弃。
DatagramChannel 有一个 connect( )方法:
public abstract class DatagramChannel extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel
{
// This is a partial API listing
public abstract DatagramChannel connect (SocketAddress remote) throws IOException;
public abstract boolean isConnected( );
public abstract DatagramChannel disconnect( ) throws IOException;
}DatagramChannel 对数据报 socket 的连接语义不同于对流 socket 的连接语义。有时候,将数据报对话限制为两方是很可取的。将 DatagramChannel 置于已连接的状态可以使除了它所“连接”到的地址之外的任何其他源地址的数据报被忽略。这是很有帮助的,因为不想要的包都已经被网络层丢弃了,从而避免了使用代码来接收、检查然后丢弃包的麻烦。
当 DatagramChannel 已连接时,使用同样的令牌,您不可以发送包到除了指定给 connect( )方法的目的地址以外的任何其他地址。试图一定要这样做的话会导致一个 SecurityException 异常。
我们可以通过调用带 SocketAddress 对象的 connect( )方法来连接一个 DatagramChannel,该SocketAddress 对象描述了 DatagramChannel 远程对等体的地址。如果已经安装了一个安全管理器,那么它会进行权限检查。之后,每次 send/receive 时就不会再有安全检查了,因为来自或去到任何其他地址的包都是不允许的。
已连接通道会发挥作用的使用场景之一是一个客户端/服务器模式、使用 UDP 通讯协议的实时游戏。每个客户端都只和同一台服务器进行会话而希望忽视任何其他来源地数据包。将客户端的DatagramChannel 实例置于已连接状态可以减少按包计算的总开销(因为不需要对每个包进行安全检查)和剔除来自欺骗玩家的假包。服务器可能也想要这样做,不过需要每个客户端都有一个DatagramChannel 对象。
不同于流 socket,数据报 socket 的无状态性质不需要同远程系统进行对话来建立连接状态。没有实际的连接,只有用来指定允许的远程地址的本地状态信息。由于此原因, DatagramChannel 上也就没有单独的 finishConnect( )方法。我们可以使用 isConnected( )方法来测试一个数据报通道的连接状态。
不同于 SocketChannel(必须连接了才有用并且只能连接一次), DatagramChannel 对象可以任意次数地进行连接或断开连接。每次连接都可以到一个不同的远程地址。调用 disconnect( )方法可以配置通道,以便它能再次接收来自安全管理器(如果已安装)所允许的任意远程地址的数据或发送数据到这些地址上。
当一个 DatagramChannel 处于已连接状态时,发送数据将不用提供目的地址而且接收时的源地址也是已知的。这意味着 DatagramChannel 已连接时可以使用常规的 read( )和 write( )方法,包括scatter/gather 形式的读写来组合或分拆包的数据:
public abstract class DatagramChannel extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel
{
// This is a partial API listing
public abstract int read (ByteBuffer dst) throws IOException;
public abstract long read (ByteBuffer [] dsts) throws IOException;
public abstract long read (ByteBuffer [] dsts, int offset, int length) throws IOException;
public abstract int write (ByteBuffer src) throws IOException;
public abstract long write(ByteBuffer[] srcs) throws IOException;
public abstract long write(ByteBuffer[] srcs, int offset, int length) throws IOException;
}read( )方法返回读取字节的数量,如果通道处于非阻塞模式的话这个返回值可能是“ 0”。write( )方法的返回值同 send( )方法一致:要么返回您的缓冲区中的字节数量,要么返回“ 0”(如果由于通道处于非阻塞模式而导致数据报不能被发送)。当通道不是已连接状态时调用 read( )或write( )方法,都将产生 NotYetConnectedException 异常。
数据报通道不同于流 socket。由于它们的有序而可靠的数据传输特性,流 socket 非常得有用。大多数网络连接都是流 socket( TCP/IP 就是一个显著的例子)。但是, 像 TCP/IP 这样面向流的的协议为了在包导向的互联网基础设施上维护流语义必然会产生巨大的开销,并且流隐喻不能适用所有的情形。数据报的吞吐量要比流协议高很多, 并且数据报可以做很多流无法完成的事情。
下面列出了一些选择数据报 socket 而非流 socket 的理由:
- 您的程序可以承受数据丢失或无序的数据。
- 您希望“发射后不管”( fire and forget)而不需要知道您发送的包是否已接收。
- 数据吞吐量比可靠性更重要。
- 您需要同时发送数据给多个接受者(多播或者广播)。
- 包隐喻比流隐喻更适合手边的任务。
如果以上特征中的一个或多个适用于您的程序,那么数据报设计对您来说就是合适的。
例 3-9 显示了如何使用 DatagramChannel 发送请求到多个地址上的时间服务器。DatagramChannel 接着会等待回复( reply)的到达。对于每个返回的回复,远程时间会同本地时间进行比较。由于数据报传输不保证一定成功,有些回复可能永远不会到达。大多数 Linux 和 Unix系统都默认提供时间服务。互联网上也有一个公共时间服务器,如 time.nist.gov。防火墙或者您的ISP 可能会干扰数据报传输,这是因人而异的。
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.channels.DatagramChannel;
import java.util.Date;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
/**
* Created with IntelliJ IDEA.
* Description:
* User: zhubo
* Date: 2018-01-15
* Time: 18:11
*/
public class TimeClient {
private static final int DEFAULT_TIME_PORT = 37;
private static final long DIFF_1900 = 2208988800L;
protected int port = DEFAULT_TIME_PORT;
protected List remoteHosts;
protected DatagramChannel channel;
public TimeClient(String[] argv) throws Exception {
if(argv.length == 0){
throw new Exception("Usage: [ -p port ] host ...");
}
parseArgs(argv);
this.channel = DatagramChannel.open();
}
protected InetSocketAddress receivePacket(DatagramChannel channel , ByteBuffer buffer) throws Exception{
buffer.clear();
return (InetSocketAddress) channel.receive(buffer);
}
protected void sendRequests() throws Exception{
ByteBuffer buffer = ByteBuffer.allocate(1);
Iterator it = remoteHosts.iterator();
while(it.hasNext()){
InetSocketAddress sa = (InetSocketAddress) it.next();
System.out.println("Requesting time from "
+ sa.getHostName() + " : " + sa.getPort());
// Make it empty (see RFC868)
buffer.clear().flip();
//Fire and forget
channel.send(buffer,sa);
}
}
public void getReplies() throws Exception{
//Allocate a buffer to hold a long value
ByteBuffer longBuffer = ByteBuffer.allocate(8);
//Assure big-endian (network) byte order
longBuffer.order(ByteOrder.BIG_ENDIAN);
//Zero the while buffer to be sure
longBuffer.putLong (0,0);
// Position to first byte of the low-order 32 bits
longBuffer.position(4);
// Slice the buffer; gives view of the low-order 32 bits
ByteBuffer buffer = longBuffer.slice();
int expect = remoteHosts.size();
int replies = 0;
System.out.println ("Waiting for replies...");
while (true) {
InetSocketAddress sa;
sa = receivePacket (channel, buffer);
buffer.flip();
replies++;
printTime (longBuffer.getLong(0), sa);
if (replies == expect) {
System.out.println ("All packets answered");
break;
}
// Some replies haven't shown up yet
System.out.println ("Received " + replies
+ " of " + expect + " replies");
}
}
// Print info about a received time reply
protected void printTime (long remote1900, InetSocketAddress sa)
{
// local time as seconds since Jan 1, 1970
long local = System.currentTimeMillis( ) / 1000;
// remote time as seconds since Jan 1, 1970
long remote = remote1900 - DIFF_1900;
Date remoteDate = new Date (remote * 1000);
Date localDate = new Date (local * 1000);
long skew = remote - local;
System.out.println ("Reply from "
+ sa.getHostName() + ":" + sa.getPort( ));
System.out.println (" there: " + remoteDate);
System.out.println (" here: " + localDate);
System.out.print (" skew: ");
if (skew == 0) {
System.out.println ("none");
} else if (skew > 0) {
System.out.println (skew + " seconds ahead");
} else {
System.out.println ((-skew) + " seconds behind");
}
}
protected void parseArgs (String [] argv) {
remoteHosts = new LinkedList();
for (int i = 0; i < argv.length; i++) {
String arg = argv[i];
// Send client requests to the given port
if (arg.equals("-p")) {
i++;
this.port = Integer.parseInt(argv[i]);
continue;
}
// Create an address object for the hostname
InetSocketAddress sa = new InetSocketAddress(arg, port);
// Validate that it has an address
if (sa.getAddress() == null) {
System.out.println("Cannot resolve address: "
+ arg);
continue;
}
remoteHosts.add(sa);
}
}
public static void main(String[] args) throws Exception{
TimeClient client = new TimeClient(args);
client.sendRequests();
client.getReplies();
}
}例 3-9 使用 DatagramChannel 的时间服务客户端
例 3-10 中的程序是一个 RFC 868 时间服务器。这段代码回答来自例 3-9 中的客户端的请求并
显示出 DatagramChannel 是怎样绑定到一个熟知端口然后开始监听来自客户端的请求的。该时间服
务器仅监听数据报( UDP)请求。大多数 Unix 和 Linux 系统提供的 rdate 命令使用 TCP 协议连接
到一个 RFC 868 时间服务。
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.net.SocketException;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.channels.DatagramChannel;
/**
* Created with IntelliJ IDEA.
* Description:
* User: zhubo
* Date: 2018-01-15
* Time: 18:33
*/
public class TimeServer {
private static final int DEFAULT_TIME_PORT = 37;
private static final long DIFF_1900 = 2208988800L;
protected DatagramChannel channel;
public TimeServer (int port)
throws Exception
{
this.channel = DatagramChannel.open( );
this.channel.socket( ).bind (new InetSocketAddress(port));
System.out.println ("Listening on port " + port
+ " for time requests");
}
public void listen( ) throws Exception
{
// Allocate a buffer to hold a long value
ByteBuffer longBuffer = ByteBuffer.allocate (8);
// Assure big-endian (network) byte order
longBuffer.order (ByteOrder.BIG_ENDIAN);
// Zero the whole buffer to be sure
longBuffer.putLong (0, 0);
// Position to first byte of the low-order 32 bits
longBuffer.position (4);
// Slice the buffer; gives view of the low-order 32 bits
ByteBuffer buffer = longBuffer.slice( );
while (true) {
buffer.clear( );
SocketAddress sa = this.channel.receive (buffer);
if (sa == null) {
continue; // defensive programming
}
// Ignore content of received datagram per RFC 868
System.out.println ("Time request from " + sa);
buffer.clear( ); // sets pos/limit correctly
// Set 64-bit value; slice buffer sees low 32 bits
longBuffer.putLong (0,
(System.currentTimeMillis( ) / 1000) + DIFF_1900);
this.channel.send (buffer, sa);
}
}
// --------------------------------------------------------------
public static void main (String [] argv)
throws Exception
{
int port = DEFAULT_TIME_PORT;
if (argv.length > 0) {
port = Integer.parseInt (argv [0]);
}
try {
TimeServer server = new TimeServer (port);
server.listen();
} catch (SocketException e) {
System.out.println ("Can't bind to port " + port
+ ", try a different one");
}
}
}
例 3-10 DatagramChannel 时间服务器
3.6 管道
java.nio.channels 包中含有一个名为 Pipe(管道)的类。广义上讲,管道就是一个用来在两个实体之间单向传输数据的导管。管道的概念对于 Unix(和类 Unix)操作系统的用户来说早就很熟悉了。 Unix 系统中,管道被用来连接一个进程的输出和另一个进程的输入。 Pipe 类实现一个管道范例,不过它所创建的管道是进程内(在 Java 虚拟机进程内部)而非进程间使用的。参见图 3-10。
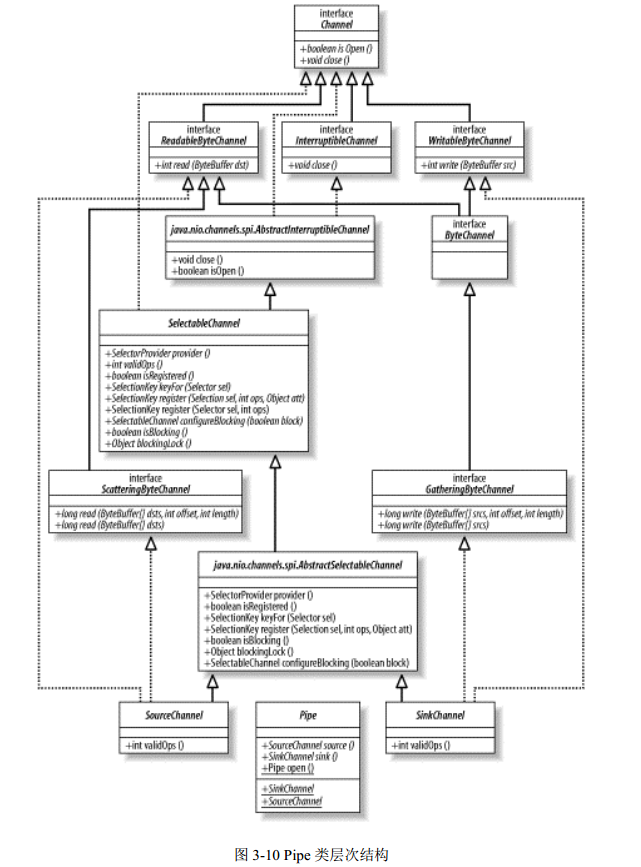
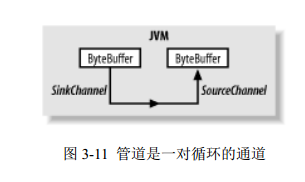
Pipe 类创建一对提供环回机制的 Channel 对象。这两个通道的远端是连接起来的,以便任何写在 SinkChannel 对象上的数据都能出现在 SourceChannel 对象上。图 3-11 显示了 Pipe 的类层级。
package java.nio.channels;
public abstract class Pipe
{
public static Pipe open( ) throws IOException
public abstract SourceChannel source( );
public abstract SinkChannel sink( );
public static abstract class SourceChannel extends AbstractSelectableChannel
implements ReadableByteChannel, ScatteringByteChannel
public static abstract class SinkChannel extends AbstractSelectableChannel
implements WritableByteChannel, GatheringByteChannel
}
Pipe 实例是通过调用不带参数的 Pipe.open( )工厂方法来创建的。 Pipe 类定义了两个嵌套的通道类来实现管路。这两个类是 Pipe.SourceChannel(管道负责读的一端)和 Pipe.SinkChannel(管道负责写的一端)。这两个通道实例是在 Pipe 对象创建的同时被创建的,可以通过在 Pipe 对象上分别调用 source( )和 sink( )方法来取回。
此时,您可能在想管道到底有什么作用。您不能使用 Pipe 在操作系统级的进程间建立一个类Unix 管道(您可以使用 SocketChannel 来建立)。 Pipe 的 source 通道和 sink 通道提供类似java.io.PipedInputStream 和 java.io.PipedOutputStream 所提供的功能,不过它们可以执行全部的通道语义。请注意, SinkChannel 和 SourceChannel 都由 AbstractSelectableChannel 引申而来(所以也是从 SelectableChannel 引申而来),这意味着 pipe 通道可以同选择器一起使用(参见第四章)。
管道可以被用来仅在同一个 Java 虚拟机内部传输数据。虽然有更加有效率的方式来在线程之间传输数据,但是使用管道的好处在于封装性。生产者线程和用户线程都能被写道通用的 Channel API 中。根据给定的通道类型,相同的代码可以被用来写数据到一个文件、 socket 或管道。选择器可以被用来检查管道上的数据可用性,如同在 socket 通道上使用那样地简单。这样就可以允许单个用户线程使用一个 Selector 来从多个通道有效地收集数据,并可任意结合网络连接或本地工作线程使用。因此,这些对于可伸缩性、冗余度以及可复用性来说无疑都是意义重大的。
Pipes 的另一个有用之处是可以用来辅助测试。一个单元测试框架可以将某个待测试的类连接到管道的“写”端并检查管道的“读”端出来的数据。它也可以将被测试的类置于通道的“读”端并将受控的测试数据写进其中。两种场景对于回归测试都是很有帮助的。
管路所能承载的数据量是依赖实现的( implementation-dependent)。唯一可保证的是写到SinkChannel 中的字节都能按照同样的顺序在 SourceChannel 上重现。例 3-11 诠释了如何使用管道。
package com.ronsoft.books.nio.channels;
import java.nio.ByteBuffer;
import java.nio.channels.ReadableByteChannel;
import java.nio.channels.WritableByteChannel;
import java.nio.channels.Pipe;
import java.nio.channels.Channels;
import java.util.Random;
/**
* Test Pipe objects using a worker thread.
*
* Created April, 2002
* @author Ron Hitchens (ron@ronsoft.com)
*/
public class PipeTest
{
public static void main (String [] argv) throws Exception
{
// Wrap a channel around stdout
WritableByteChannel out = Channels.newChannel (System.out);
// Start worker and get read end of channel
ReadableByteChannel workerChannel = startWorker (10);
ByteBuffer buffer = ByteBuffer.allocate (100);
while (workerChannel.read (buffer) >= 0) {
buffer.flip( );
out.write (buffer);
buffer.clear( );
}
}
// This method could return a SocketChannel or
// FileChannel instance just as easily
private static ReadableByteChannel startWorker (int reps) throws Exception
{
Pipe pipe = Pipe.open( );
Worker worker = new Worker (pipe.sink( ), reps);
worker.start( );
return (pipe.source( ));
}
// -----------------------------------------------------------------
/**
* A worker thread object which writes data down a channel.
* Note: this object knows nothing about Pipe, uses only a
* generic WritableByteChannel.
*/
private static class Worker extends Thread
{
WritableByteChannel channel;
private int reps;
Worker (WritableByteChannel channel, int reps)
{
this.channel = channel;
this.reps = reps;
}
// Thread execution begins here
public void run( )
{
ByteBuffer buffer = ByteBuffer.allocate (100);
try {
for (int i = 0; i < this.reps; i++) {
doSomeWork (buffer);
// channel may not take it all at once
while (channel.write (buffer) > 0) {
// empty
}
}
this.channel.close( );
} catch (Exception e) {
// easy way out; this is demo code
e.printStackTrace( );
}
}
private String [] products = {
"No good deed goes unpunished",
"To be, or what?",
"No matter where you go, there you are",
"Just say \"Yo\"",
"My karma ran over my dogma"
};
private Random rand = new Random( );
private void doSomeWork (ByteBuffer buffer)
{
int product = rand.nextInt (products.length);
buffer.clear( );
buffer.put (products [product].getBytes( ));
buffer.put ("\r\n".getBytes( ));
buffer.flip( );
}
}
}例 3-11 工作线程对一个管道进行写操作
3.7 通道工具类
NIO 通道提供了一个全新的类似流的 I/O 隐喻,但是我们所熟悉的字节流以及字符读写器仍然存在并被广泛使用。通道可能最终会改进加入到 java.io 类中(这是一个实现细节),但是java.io 流所代表的 API 和读写器却不会很快消失(它们也不应该消失)。
一个工具类( java.nio.channels.Channels 的一个稍微重复的名称)定义了几种静态的工厂方法以使通道可以更加容易地同流和读写器互联。表 3-2 对这些方法做了一个汇总。
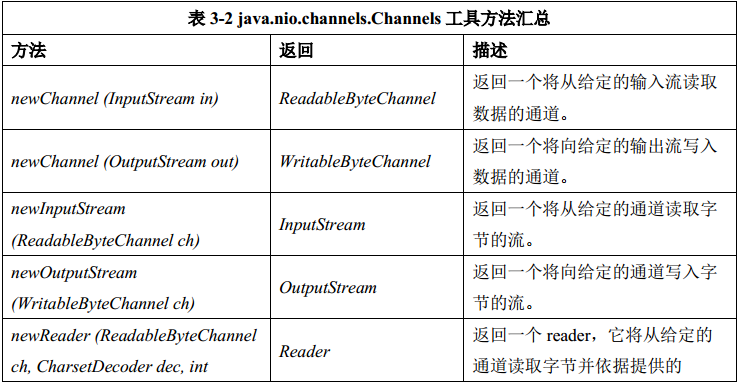
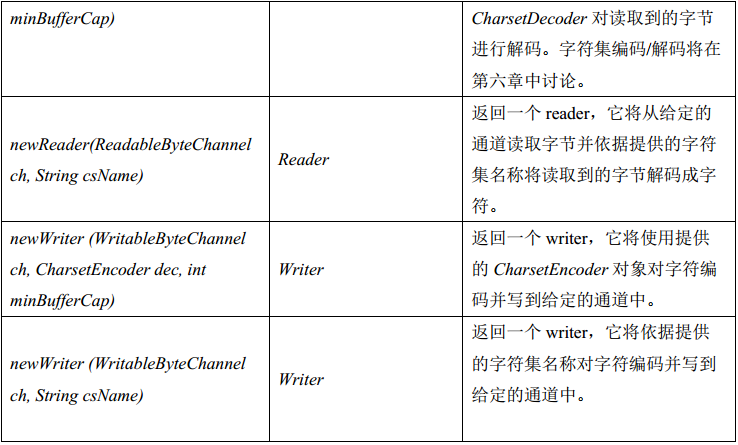
回忆一下,常规的流仅传输字节, readers 和 writers 则作用于字符数据。表 3-2 的前四行描述了用于连接流、通道的方法。因为流和通道都是运行在字节流基础上的,所以这四个方法直接将流封装在通道上,反之亦然。
Readers 和 Writers 运行在字符的基础上,在 Java 的世界里字符同字节是完全不同的。将一个通道(仅了解字节)连接到一个 reader 或 writer 需要一个中间对话来处理字节/字符( byte/char) 阻抗失配。为此,表 3-2 的后半部分描述的工厂方法使用了字符集编码器和解码器。字符集以及字符集转码将在第六章中详细讨论。
这些方法返回的包封 Channel 对象可能会也可能不会实现 InterruptibleChannel 接口,它们也可能不是从 SelectableChannel 引申而来。因此,可能无法将这些包封通道同 java.nio.channels包中定义的其他通道类型交换使用。细节是依赖实现的。如果您的程序依赖这些语义,那么请使用操作器实例测试一下返回的通道对象。
3.8 总结
本章中我们讨论了通道的很多方面的内容。通道组成了基础设施或者说管道设施,该设施在操作系统(或通道连接到的任意东西)的 ByteBuffers 和 I/O 服务之间传输数据。本章中讨论到的关键概念有:
基本的通道操作
在 3.1 节中我们学习了通道的基本操作,具体包括:怎样使用所有通道都通用的 API 方法调用来打开一个通道以及完成操作时如何关闭通道。
Scatter/Gather 通道
在 3.2 节中我们介绍了如何使用通道来 scatter/gather I/O。矢量化的 I/O 使您可以在多个缓冲区上自动执行一个 I/O 操作。
文件通道
在 3.3 节中我们讨论了多层面的 FileChannel 类。这个强大的新通道提供了对高级文件操作的访问,以前这是不对 Java 编程开放的。新的功能特性包括:文件锁定、内存映射文件以及channel-to-channel 传输。
Socket 通道
在 3.5 节中我们覆盖了几种类型的 socket 通道。同时,我们也讨论了 socket 通道所支持的一个重要新特性——非阻塞模式。
管道
在 3.6 节中我们看了一下 Pipe 类,这是一个使用专门的通道实现的新循环机制,非常有用。
通道工具类
通道类中包含了工具方法,这些方法用于交叉连接通道和常规的字节流以及字符读写器对象。参见 3.7 节。
您的 NIO 拨号中有许多通道,现在我们都已经全部学习了。本章中需要吸收的内容很多。通道是 NIO 的一个关键抽象。既然我们了解了通道是什么以及怎样有效地使用它们来访问本地操作系统的 I/O 服务,那么现在是时候前进到 NIO 的下一个主要创新了。下一章中,我们将学习如何简单有效地管理许多这些强大的新通道。
下去冲个澡休息下,再逛下礼品店,然后请重新登上本巴士。我们的下一站是:选择器( Selectors)。















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









