






转载请注明出处哈:http://carlosfu.iteye.com/blog/2269678
一、什么是缓存雪崩
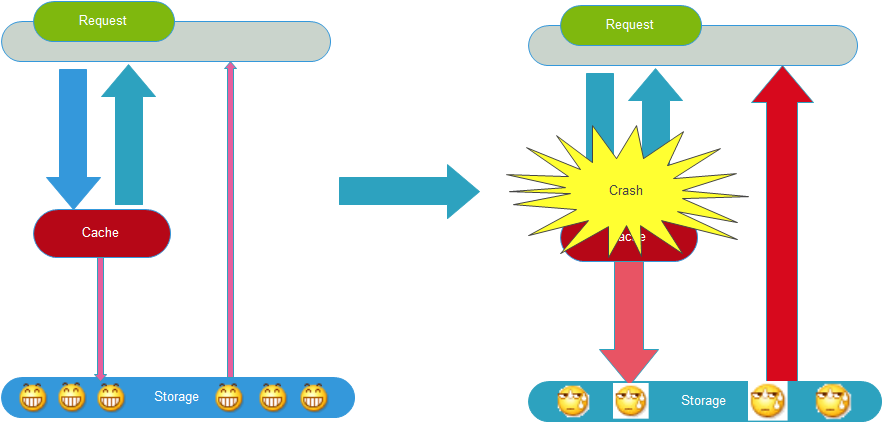
从下图可以很清晰出什么是缓存雪崩:
1. 由于Cache层承载着大量请求,有效的保护了Storage层(通常认为此层抗压能力稍弱),所以Storage的调用量实际很低,所以它很爽。
2. 但是,如果Cache层由于某些原因(宕机、cache服务挂了或者不响应了)整体crash掉了,也就意味着所有的请求都会达到Storage层,所有Storage的调用量会暴增,所以它有点扛不住了,甚至也会挂掉 
二、 缓存雪崩的危害
雪崩的危害显而易见,通常来讲可能很久以前storage已经扛不住大量请求了,于是加了cache层,所以雪崩会使得storage压力山大,甚至是挂掉。
三、如何预防缓存雪崩
1. 保证Cache服务高可用性:
和飞机都有多个引擎一样,如果我们的cache也是高可用的,即使个别实例挂掉了,影响不会很大(主从切换或者可能会有部分流量到了后端),实现自动化运维。例如:
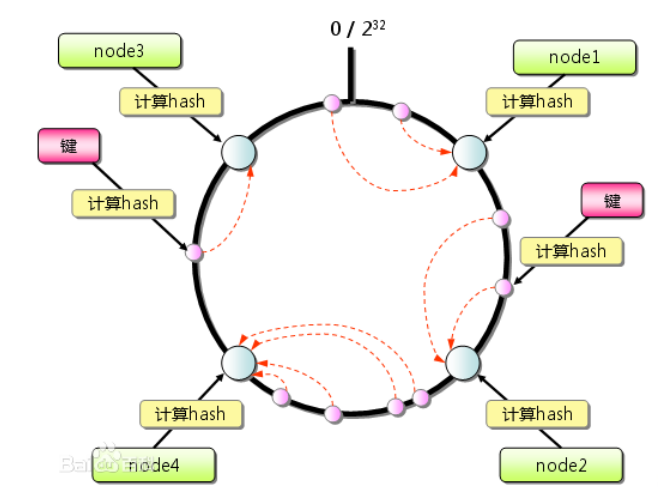
memcache的一致性hash:
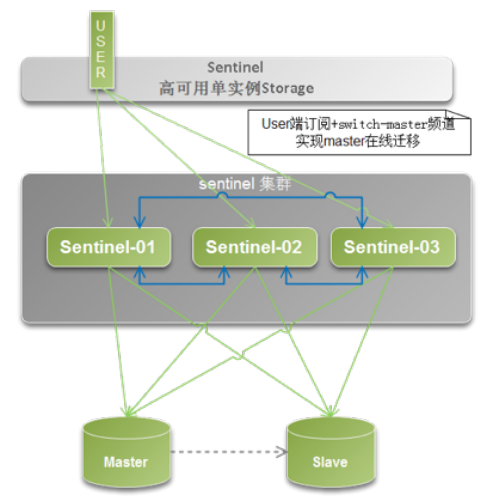
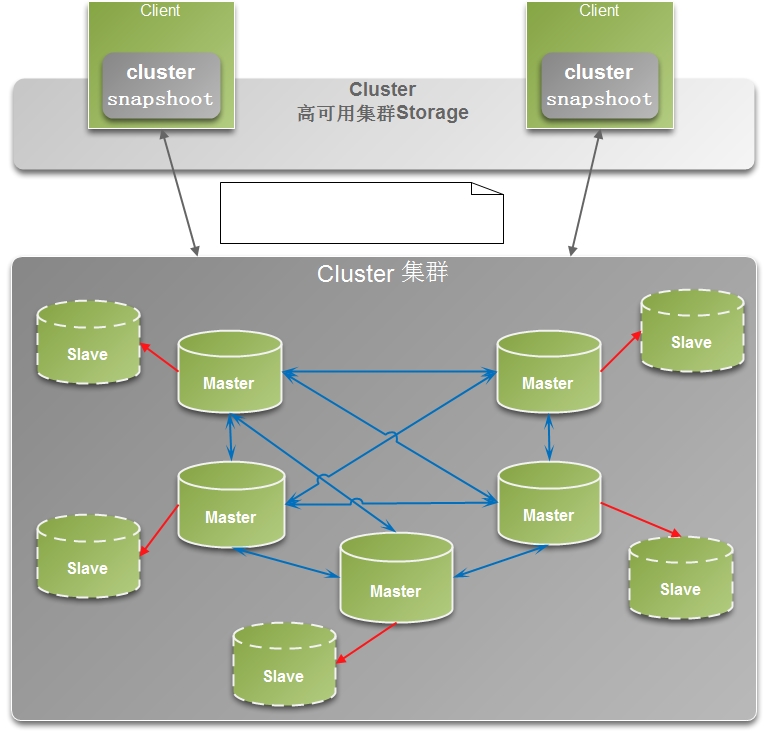
redis的sentinel和cluster机制:
有关memcache和redis的高可用方案,之后会有文章进行介绍。
2. 依赖隔离组件为后端限流:
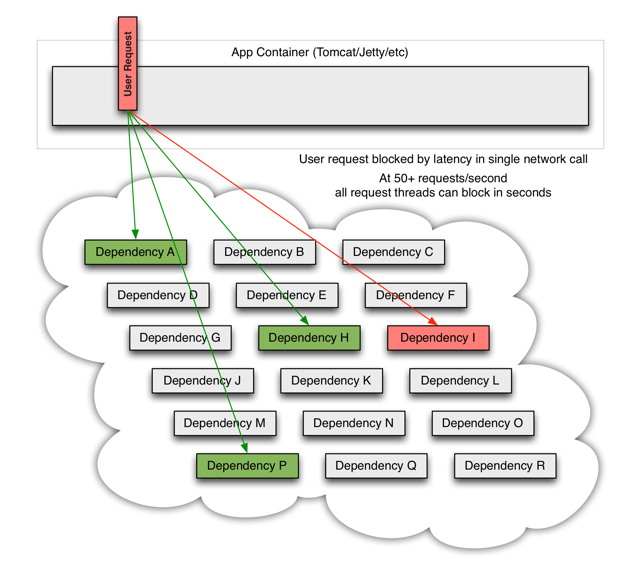
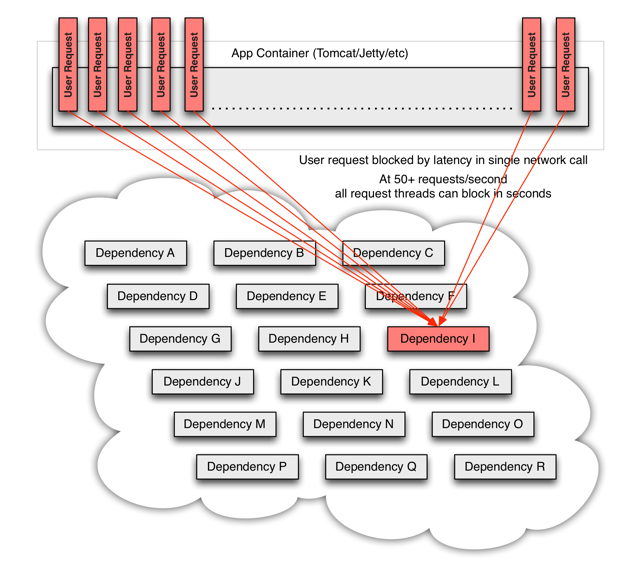
其实无论是cache或者是mysql, hbase, 甚至别人的API,都会出现问题,我们可以将这些视同为资源,作为并发量较大的系统,假如有一个资源不可访问了,即使设置了超时时间,依然会hang住所有线程,造成其他资源和接口也不可以访问。
相信大家一定遇到过这样的页面:这些应该就是淘宝的降级策略。
降级在高并发系统中是非常正常的:比如推荐服务中,很多都是个性化的需求,假如个性化需求不能提供服务了,可以降级补充热点数据,不至于造成前端页面是个大空白(开了天窗了)
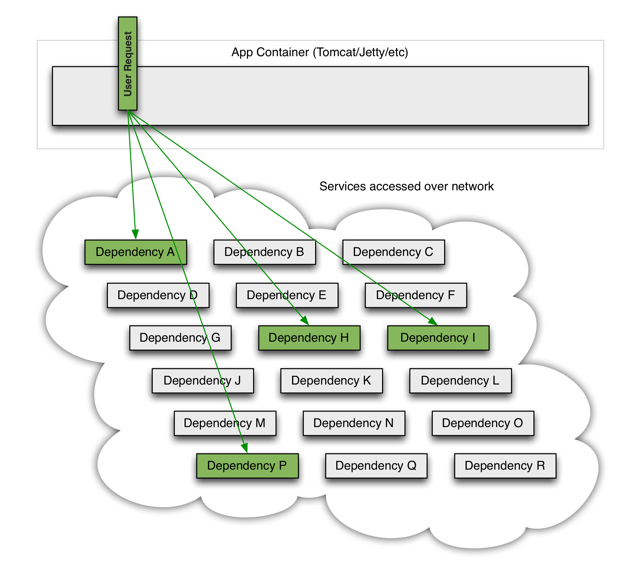
在实际项目中,我们对重要的资源都进行隔离,比如hbase, elasticsearch, zookeeper, redis,别人的api(可能是http, rpc),让每种资源都单独运行在自己的线程池中,即使资源出现了问题,对其他服务没有影响。
但是线程池如何管理,比如如何关闭资源池,开启资源池,资源池阀值管理,这些做起来还是相当麻烦的,幸好netfilx公司提供了一个很牛逼的工具:hystrix,可以做各种资源的线程池隔离。
有关hystrix的详细介绍可以参考:http://hot66hot.iteye.com/blog/2155036
hystrix附图:
3. 提前演练:
在项目上线前,通过演练,观察cache crash后,整体系统和storage的负载, 提前做好预案。















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









