






插入排序及其解决思路
算法的作用自然不用多说,无论是在校学生,还是已经工作多年,只要想在计算机这条道路走得更远,算法都是必不可少的。
就像编程语言中的“Hello World!”程序一般,学习算法一开始学的便是排序算法。排序问题在日常生活中也是很常见的,说得专业点:
输入是:n个数的一个序列<a1,a2,...,an−1,an>
输出是:这n个数的一个全新的序列<a,1,a,2,...,a,n−1,a,n>,其特征是a,1≤a,2≤...≤a,n−1≤a,n
举个例子,在本科阶段学校往往要求做的实验中大多是“学生管理系统”、“信息管理系统”、“图书管理系统”这些。就比如“学生管理系统”中的分数,每当往里面添加一个新的分数时,便会和其他的进行比较从而得到由高到低或由低到高的排序。
我本人是不太喜欢做这种管理系统的…… 再举个比较有意思的例子。
大家肯定都玩过扑克牌,撇开部分人不说,相信大部分童鞋都热衷于将牌按序号排好。那么这其中就蕴含着算法的思想:
1)手中的扑克牌有2种可能:没有扑克牌(为空)或者有扑克牌且已排好序。
2)从桌上抓起一张牌后,从左往右(从右往左)依次进行比较,最终选择一个合适的位置插入。简单的说,插入排序的精髓在于“逐个比较”。
在列出代码之前,先来看看下面的第一张图,我画的不是太好,就是有没有经过排序的 “8,7,4,2,3,9”几个数字,根据上面的描述,将排序过程描述为:
1)将第二个数字“7”和“8”比较,发现7更小,
于是将“8”赋值到“7”所在的位置,
然后将7赋值给“8”所在的位置。
2)将”4“移到”7“所在的位置,”7“和”8“后移一位。
3)同样的步骤,将”2“和”3“移到”4“的前面。
4)”9“比前面的数字都大,故不移动。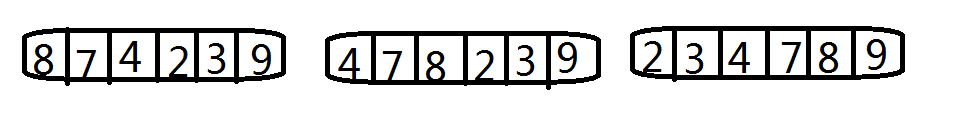
仅仅是这样的描述还是不够的,我们需要更加专业一点。
1)设置一个循环,从第二个数字开始(索引为1)不断与前面的数字相比。
2)每次循环开始时作为比较的数的索引为j,设置temp为其值。(因为在前面也看到了,将”8“赋值到”7“的位置时,如果不将”7“保存起来,那么便丢失了这个数字。)
3)取得j的前一位i。
4)只要i仍在数组中,并且索引为i处的值大于temp,就将i后一位的值设为i处的值,同时将i减1。
5)在i不在数组中或i处的值不必temp大时结束第四部的循环,然后将i后一位的值设置为temp。将上面这部分描述翻译为insertion_sort函数,下面是完整的测试程序。
#include <iostream>
#include <cstdio>
using namespace std;
#define MAX_N 1000
int A[MAX_N];
int n;
void insertion_sort();
int main()
{
printf("数组长度:\n");
scanf("%d",&n);
printf("数组内容:\n");
for(int i=0;i<n;i++)
{
scanf("%d",&A[i]);
}
insertion_sort();
for(int i=0;i<n;i++)
{
printf("%d ",A[i]);
}
return 0;
}
void insertion_sort()
{
for(int j=1;j<n;j++)
{
int temp=A[j];
int i=j-1;
while(i>=0&&A[i]>temp)
{
A[i+1]=A[i];
i=i-1;
}
A[i+1]=temp;
}
}下面是能够帮助我们理解算法的正确性的循环不变式的三条性质:
初始化:循环第一次迭代之前,它为真。
保持:如果循环的某次迭代之前它为真,那么下次迭代之前它仍为真。
终止:在循环终止时,不变式能够提供一个有助于证明算法正确性的性质。就比如上面排序的例子,终止意味着在最后一次迭代时,由传入数组元素构成的子数组元素都已排好序,因此此时子数组就等同与原数组,于是循环终止。
学习如何分析算法
继续分析排序算法,我们知道排序10000个数肯定要比排序10个数所花费的时间更长,但除了输入的项数外就没有其他的影响因素吗?当然有,比如说输入的序列的已被排序的程度,如果是“23456781”这个序列,我们仅仅需要将1放到首位就好,而输入是”87654321“,我们就需要将7到1依次与其前面的数字进行比较。
关于算法的分析也有两个定义:
1)输入规模,当考虑的是排序算法时,那么规模就指的是项数;如果考虑的是图算法,那么规模就是顶点数和边数。
2)运行时间,名义上来说就是算法执行的时间,但实际上我们在分析一个算法时考量的算法执行的操作数或步数。下面我们通过前面排序算法的伪代码来分析它的运行时间。
INSERTION-SORT(A)
1 for j = 2 to A.length // 代价c1,次数n
2 temp=A[j]; // 代价c2,次数n-1
3 // 将A[j]插入到已排序的A[1..j-1] // 代价0,次数n-1
4 i=j-1; // 代价c4,次数n-1
5 while i>0 and A[i]>temp // 代价c5
6 A[i+1]=A[i]; // 代价c6
7 i=i-1; // 代价c7
8 A[i+1]=temp; // 代价c8,次数n-1代价为c1处的次数为n应该比较好理解对吧,从j=1到j=n一共有n步,j=n也应该包括在内,因为这是算法终止的情况。而j=n时,程序直接终止了,所以在代价c2、c3、c7处次数都为n-1。
那么在while循环中呢,代价为c4的时候次数为多少呢,很显然应该是∑nj=2tj,而c5和c6在while循环里总有一次它不会去执行,因此次数为∑nj=2(tj−1)。
将代价和次数相乘,便得到了该算法所需的总时间:
T(n)=c1n+c2(n−1)+c4(n−1)+c5∑nj=2tj+c6∑nj=2(tj−1)+c7∑nj=2(tj−1)+c8(n−1)
除此之外我们还可以来对算法进行最好和最坏情况的分析:
1)在最好情况下,也就是整个输入数组其实都是排好序的,那么它根本没法进入while循环,也就是说当i取初值j-1时,有A[i]≤temp,从而对j=2,3,4...n都有tj=1。
那么算法的总时间也就可以算出来了:
T(n)=(c1+c2+c4+c5+c8)n−(c2+c4+c5+c8)
2)在最坏情况下,也就是数组是逆向排好序的,那么就需要将A[j]与已排好序的数组A[1...j1]中的每个元素进行比较,从而对j=2,3,4...n都有tj=j。
那么算法的总时间也就可以算出来了:
T(n)=(c52+c62+c72)n2+(c1+c2+c4+c52−c62−c72+c8)n−(c2+c4+c5+c8)
渐近记号
Θ
在上面我已经求出了该排序算法的运行总时间,但我们可以对其做进一步的简化以及抽象,我们只考虑最坏情况,因为在实际中它更有意义。将运行时间表示为an2+bn+c,其中的a、b、c都依赖于ci。
让我们来做进一步的抽象,通过只考虑运行时间的增长率和增长量级。因为当程序足够大时,低阶项便不再重要了,甚至连高阶项的系数也可以忽略不计。于是,我们记插入排序在最坏情况下所需要的运行时间为Θ(n2)。
现在是时候给出Θ的定义了:
Θ(g(n))={f(n):存在正数常量c1、c2和n0,使得对所有的n≥n0,有0≤c1g(n)≤f(n)≤c2g(n)}
也就是说在跨过n0之后,f(n)就一直处于c1g(n)和c2g(n)之间,其中c1g(n)是下界,c2g(n)是上界。
O和Ω
O和Θ相比,前者就只是后者的一半——只有渐近上界,而没有渐近下界。那么它的定义为:
O(g(n))={f(n):存在正数常量c和n0,使得对所有的n≥n0,有0≤f(n)≤cg(n)}
Ω和Θ相比,前者就只是后者的一半——只有渐近下界,而没有渐近下界。那么它的定义为:
Ω(g(n))={f(n):存在正数常量c和n0,使得对所有的n≥n0,有0≤f(n)cg(n)≤cg(n)}
设计分治算法
前面的排序问题使用的方法叫做增量法,即在排序子数组A[1...j−1]后,将单个元素A[j]插入到子数组的适当位置,然后参数排序好的数组A[1...j],它的精髓在于“逐个比较”。
现在我们再来介绍一种新的方法,叫做分治法,它同样也是鼎鼎大名。它的精髓在于“一分为二“,而驱动这个算法的这是递归。
分治算法在每层递归中都有三个步骤:
1)分解原问题为若干子问题,这些子问题是缩小版的原问题。(抽象的讲,将一个已经切成楔形的大块西瓜可以再切成多个小的楔形西瓜。)
2)解决这些子问题,递归地求解各个子问题。然后,若问题的规模足够小,则直接求解。(继续举例子,要吃完一大块西瓜,可以不断的吃小部分,当西瓜块足够小时,可以一口干掉。)
3)合并这些子问题的解成原问题的解。(吃完的那些小块西瓜加在一起就是刚才那一块很大的西瓜了。)虽然西瓜的例子能够体现分治算法的思想,但用前面的扑克牌来演示则更加合适,毕竟它有数字呀。来来来,想象一下,桌上正有两堆牌,且分别都已经排号顺序,可是呢我们需要这两堆牌合并起来并且排序好。
那么怎么操作呢?很简单,一句话就能说清楚:不断从两堆牌的顶上选取较小的一张,然后放到新的扑克牌堆中。
首先我们将扑克牌定义成数组A,p和q以及r都是数组的下标,且p≤q<r,两段已排序好的子数组是A[p..q]和A[q+1..r],我们需要做的是将其排序为A[p..r]。下面的伪代码便实现了这个思想:
MERGE(A,p,q,r)
1 n1 = (q - p) + 1 = q - p + 1
2 n2 = (r - (q + 1)) +1 = r - q
3 let L[1..n1+1] and R[1..n2+1] be new arrays
4 for i = 1 to n1
5 L[i] = A[p + i -1]
6 for j = 1 to n2
7 R[j] = A[q + j]
8 L[n1 + 1] = #
9 R[n2 + 1] = #
10 i = 1;
11 j = 1;
12 for k = p to r
13 if L[i] 小于等于 R[j]
14 A[k] = L[i];
15 i = i + 1;
16 else
17 A[k] = R[j]
18 j = j + 1;上面的”# “号就是传说中的哨兵牌,每当显露一张哨兵牌时,它不可能为较小的值,除非两个堆都已显露出哨兵牌。但是出现这种情况就意味着算法结束,所有非哨兵牌都已被放置到输出堆。
………………p q r………………
………………3 6 8 9 2 5 7 8………………
k
L 3 6 8 9 # R 2 5 7 8 #
i j比较”3“和”2“,发现2更小,于是将2放到A数组的首位,并且将j移后一位。
………………p q r………………
………………2 6 8 9 2 5 7 8………………
k
L 3 6 8 9 # R 2 5 7 8 #
i j比较”3“和”5“,发现3更小,于是将3放到数组A的首位,并且将i移后一位。
………………p q r………………
………………2 3 8 9 2 5 7 8………………
k
L 3 6 8 9 # R 2 5 7 8 #
i j以此类推,最终A数组就成排好了序……
………………p q r………………
………………2 3 5 6 7 8 8 9………………
k
L 3 6 8 9 # R 2 5 7 8 #
i j将上面的思想以及伪代码写成如下程序,大家可以参考参考:
#include <iostream>
#include <cstdio>
using namespace std;
#define MAX_N 1000
int A[MAX_N];
int L[MAX_N/2];
int R[MAX_N/2];
int n,p,q,r;
void merge();
int main()
{
printf("数组长度:\n");
scanf("%d",&n);
printf("数组内容:\n");
for(int i=0;i<n;i++)
{
scanf("%d",&A[i]);
}
printf("输入p q r\n");\
scanf("%d %d %d",&p,&q,&r);
merge();
for(int i=0;i<n;i++)
{
printf("%d ",A[i]);
}
return 0;
}
void merge()
{
int n1=q-p+1;
int n2=r-q;
for(int i=0;i<n1;i++)
L[i]=A[p+i];
for(int j=0;j<n2;j++)
R[j]=A[q+j+1];
L[n1]=100;
R[n2]=100;
for(int k=p,i=0,j=0;k<=r;k++)
{
if(L[i]<=R[j])
{
A[k]=L[i];
i=i+1;
}
else
{
A[k]=R[j];
j=j+1;
}
}
}下面没有用图示而是用了代码显示块来显示,应该也能看的吧?就是不断的归并,最终合成一个完整的排好序的数组。
…………………………2 2 5 6 7 8 8 9…………………………
……………………………………归并……………………………………
…………………2 5 6 8………………2 7 8 9…………………
……………………归并…………………………归并……………………
……………2 6…………5 8…………2 9…………7 8……………
……………归并…………归并………归并……………归并……………
…………6……2………8……5………2……9………8……7…………要完成上面这个程序,我们可以利用前面写好的merge函数呢,下面是伪代码实现。
MERGE-SORT(A,p,r)
1 if p < r
2 q = 小于或等于(p+r)/2的最大整数
3 MERGE-SORT(A,p,q)
4 MERGE-SORT(A,q+1,r)
5 MERGE(A,p,q,r)然后为了完成这其中q的参数传递,将它们设置为全局变量已经不合适了,具体的程序可以参考如下:
#include <iostream>
#include <cstdio>
using namespace std;
#define MAX_N 1000
int A[MAX_N];
int L[MAX_N/2];
int R[MAX_N/2];
void merge(int A[],int p,int q,int r);
void merge_sort(int A[],int p,int r);
int main()
{
int n, p, q, r;
printf("数组长度:\n");
cin >> n;
printf("数组内容:\n");
for (int i = 0;i < n;i++)
{
cin >> A[i];
}
printf("输入p r\n");\
cin >> p >> r;
merge_sort(A, p, r);
for (int i = 0;i < n;i++)
{
printf("%d ", A[i]);
}
return 0;
}
void merge_sort(int A[],int p,int r)
{
if(p<r)
{
int q=(p+r)/2;
merge_sort(A,p,q);
merge_sort(A,q+1,r);
merge(A,p,q,r);
}
}
void merge(int A[], int p, int q, int r)
{
int n1 = q - p + 1;
int n2 = r - q;
for (int i = 0;i<n1;i++)
L[i] = A[p + i];
for (int j = 0;j<n2;j++)
R[j] = A[q + j + 1];
L[n1] = 100;
R[n2] = 100;
for (int k = p, i = 0, j = 0;k<=r;k++)
{
if (L[i] <= R[j])
{
A[k] = L[i];
i = i + 1;
}
else
{
A[k] = R[j];
j = j + 1;
}
}
}分析分治算法
当我们的输入足够小时,比如对于某个常量c,n≤c,则直接求解需要常量时间,并写作Θ(1)。
对于复杂的问题,我们将其分解成a个子问题,每个子问题的规模是原问题的1/b.对于这规模为n/b的子问题,累计需要T(n/b)的时间,所以需要aT(n/b)的时间来求解这a个子问题。而这其中分解的过程也需要消耗一定的时间,记作D(n),合并这些子问题也需要一定的时间,记作C(n)。于是又得到了一个递归式:
当n≤c时,T(n)=Θ(1)
其他情况时,T(n)=aT(n/b)+D(n)+C(n)
下面来通过分治模式在每层递归时都有的三个步骤来分析归并排序算法,我们所考虑的是n个数的最坏情况下的运行时间。同样的,归并排序一个元素需要常量时间,当n>1时有如下3个步骤:
分解:分解步骤仅仅计算子数组的中间位置,需要常量时间,因此D(n)=Θ(1)
解决:我们递归地求解两个规模均为n/2的子问题,将贡献2T(n/2)的运行时间。
合并:一个具有n个元素的子数组上过程MERGE需要Θ(n)的时间,所以C(n)=Θ(n)。
因此D(n)+C(n)便等于Θ(n)和Θ(n)相加,可是结果依然为Θ(n)。接着可以得到归并排序的最坏情况运行时间的递归式了。
当n=1时,T(n)=Θ(1)
当n>1时,T(n)=2T(n/2)+Θ(n)
我们对上式稍作变换如下:
当n=1时,T(n)=c
当n>1时,T(n)=2T(n/2)+cn
这个式子可以不断的做递归,最后形成一个递归树的。树的第一层是cn,第二层是cn/2,第三层是cn/4,直到最后一层为c。第二层有2棵子树,第三层有4棵子树,直到最后一程有n棵子树,因此每层的代价总共为cn。而整个树共有lgn+1层,因此总代价为cnlgn+cn。
忽略低阶项和系数项,最终记为Θ(nlgn)。
总结分治算法
分治算法的英文名叫做“divide and conquer”,它的意思是将一块领土分解为若干块小部分,然后一块块的占领征服,让它们彼此异化。这就是英国人的军事策略,但我们今天要看的是算法。
如前所述,分治算法有3步,在上一篇中已有介绍,它们对应的英文名分别是:divide、conquer、combine。
接下来我们通过多个小算法来深化对分治算法的理解。
二分查找算法
问题描述:在已排序的数组A中查找是否存在数字n。
1)分:取得数组A中的中间数,并将其与n比较
2)治:假设数组为递增数组,若n比中间数小,则在数组左半部分继续递归查找执行“分”步骤
3)组合:由于在数组A中找到n后便直接返回了,因此这一步就无足轻重了
平方算法
问题描述:计算x的n次方
我们有原始算法:用x乘以x,再乘以x,再乘以x,一直有n个x相乘
这样一来算法的复杂度就是Θ(n)。
分治算法:我们可以将n一分为二,于是,
当n为奇数时,xn=x(n−1)/2∗x(n−1)/2∗x
当x为偶数时,xn=xn/2∗xn/2
此时的复杂度就变成了Θ(lgn)。
斐波那契数
斐波那契数的定义如下:
当然,可以直接用递归来求解,但是这样一来花费的时间就是指数级的Ω(Φn),Φ为黄金分割数。
然后我们可以更进一步让其为多项式时间。
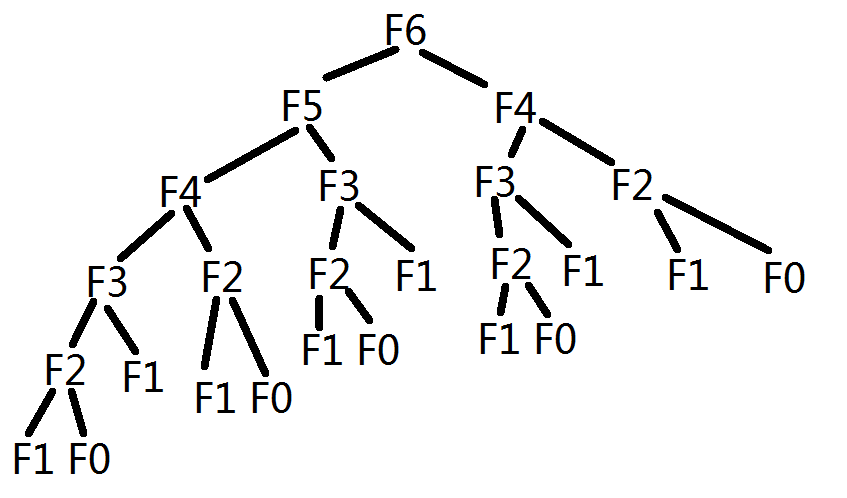
上面这幅图虽然比较简略,在求n为6时的斐波那契数,我们却求解了3次F3,F1和F0的求解次数则更多了,我们完全可以让其只求解一次。
对此,还有一个计算公式:
Fi=Φi−Φ¯i(√5)
其中Φ¯¯¯是黄金分割率Φ的共轭数。
然后这个公式只存在与理论中,在当今计算机中仍旧无法计算,因为我们只能使用浮点型,而浮点型都有一定的精度,最后计算的时候铁定了会丢失一些精度的。
下面再介绍一种平方递归算法:

一时忘了矩阵怎么计算成绩,感谢@fireworkpark 相助。
最大子数组问题
最近有一个比较火的话题,股票,那么这一篇就由此引入来进一步学习分治算法。在上一篇博客中已经对插入排序和归并排序做了初步的介绍,大家可以看看:【算法基础】由插入排序看如何分析和设计算法
当然了,这篇博客主要用来介绍算法而非讲解股票,所以这里已经有了股票的价格,如下所示。
| 天 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 股票价格 | 50 | 57 | 65 | 75 | 67 | 60 | 54 | 51 | 48 | 44 | 47 | 43 | 56 | 64 | 71 | 65 | 61 | 73 | 70 |
| 价格波动 | 0 | 7 | 8 | 18 | -8 | -7 | -6 | -3 | -3 | -4 | 3 | -4 | 13 | 10 | 7 | -6 | -4 | 12 | -3 |
价格表已经有了问题是从哪一天买进、哪一天卖出会使得收益最高呢?你可以认为在价格最低的时候买入,在价格最高的时候卖出,这是对的,但不一定任何时候都适用。在这里的价格表中,股票价格最高的时候是第3天、价格最低的时候是第11天,怎么办?让时间反向行驶?
就像我以前参加学校里的程序设计竞赛时一样,也可以用多个for循环不断的进行比较。这里就是将每对可能的买进和卖出日期进行组合,只要卖出日期在买进日期之前就好,这样在18天中就有C218种日期组合,也可以写成(182)。因此对于n天,就有(n2)种组合,而(n2)=Θ(n2),另外处理每对日期所花费的时间至少也是常量,因此这种方法的运行时间为Ω(n2)。
然后,我们在学习算法,自然要以算法的角度来看这个问题。比起股票价格,我们更应该关注价格波动。如果将这个波动定义为数组A,那么问题就转换为寻找A的和最大的非空连续子数组。这种连续子数组就是标题中的最大子数组(maximum subarray)。将原表简化如下:
| 数组 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 7 | 8 | 18 | -8 | -7 | -6 | -3 | -3 | -4 | 3 | -4 | 13 | 10 | 7 | -6 | -4 | 12 | -3 |
在这个算法中,常常被说成是“一个最大子数组”而不是“最大子数组”,因为可能有多个子数组达到最大和。
只有当数组中包含负数时,最大子数组问题才有意义。如果所有数组元素都是非负的,最大子数组问题没有任何难度,因为整个数组的和肯定是最大的。
使用分治思想解决问题
我们将实际问题转换为算法问题,在这里也就是要寻找子数组A[low...high]的最大子数组。分治思想意味着将问题一分为二,这里就需要找到数组的中间位置mid,然后考虑求解2个子数组A[low...mid]和A[mid+1...high]。而A[low...high]的任何连续子数组A[i...j]所处的位置必然是以下情况之一:
1)完全位于子数组A[low...mid]中,因此low≤i≤j≤mid;
2)完全位于子数组A[mid+1...high]中,因此mid<i≤j≤high;
3)跨越中点mid,因此low≤i≤mid≤j≤high。
A[low...high]的一个最大子数组所处的位置必然是这三种情况之一,而且还是这三种情况中所有子数组中和最大者。对于第1种和第2种情况我们可以通过递归来求解最大子数组,对于第三种情况我们可以通过下面伪代码所示来求解。
FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)
1 left-sum = -10000
2 sum = 0
3 for i = mid downto low
4 sum = sum + A[i]
5 if sum > left-sum
6 left-sum = sum
7 max-left = i
8 right-sum = -10000
9 sum = 0
10 for j = mid + 1 to high
11 sum = sum + A[i]
12 if sum > right-sum
13 right-sum = sum
14 max-right = j
15 return (max-left, max-right, left-sum + right-sum)下面是以上程序的一个简易程序。
#include <iostream>
#include <cstdio>
using namespace std;
int const n=18;
int A[n]={7,8,18,-8,-7,-6,-3,-3,-4,3,-4,13,10,7,-6,-4,12,-3};
int B[3];
int low,high,mid;
int max_left,max_right;
int sum;
void find_max_crossing_subarray(int A[],int low,int mid,int high);
int main()
{
find_max_crossing_subarray(A,0,7,15);
for(int i=0;i<3;i++)
{
printf("%d ",B[i]);
}
return 0;
}
void find_max_crossing_subarray(int A[],int low,int mid,int high)
{
int left_sum=-10000;
sum=0;
for(int i=mid;i>=low;i--)
{
sum=sum+A[i];
if(sum>left_sum)
{
left_sum=sum;
max_left=i;
}
}
int right_sum=-10000;
sum=0;
for(int j=mid+1;j<=high;j++)
{
sum=sum+A[j];
if(sum>right_sum)
{
right_sum=sum;
max_right=j;
}
}
B[0]=max_left;
B[1]=max_right;
B[2]=left_sum+right_sum;
}
如果子数组A[low...high]包含n个元素(即n=high−low+1),则调用FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)花费Θ(n)时间。而上面的两个for循环都次迭代都会花费Θ(1)时间,每个for循环都执行了mid−low+1(或high−mid)次迭代,因此总循环的迭代次数为:
(mid−low+1)+(high−mid)=high−low+1=n
可以看出上面的算法所花费的时间是线性的,这样我们就可以来求解最大子数组问题的分治算法的伪代码咯:
FIND-MAXIMUM-SUBARRAY(A,low,high)
1 if high==low
2 return (low,high,A[low])
4 (left-low,left-high,left-sum)=FIND-MAXIMUM-SUBARRAY(A,low,mid)
5 (right-low,right-high,right-sum)=FIND-MAXIMUM-SUBARRAY(A,mid+1,high)
6 (cross-low,cross-high,cross-sum)=FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)
7 if left-sum>=right-sum and left-sum>=cross-sum)
return (left-low,left-high,left-sum)
8 else if(right-sum>=left-sum and right-sum>=cross-sum)
return (right-low,right-high,right-sum)
9 else return (cross-low,cross-high,cross-sum)只要初始调用FIND-MAXIMUM-SUBARRAY(A,1,A.length)就可以求出A[1...n]的最大子数组了。
分治算法和渐近记号中的省略问题
下面我们又来使用递归式来求解前面的递归过程FIND-MAXIMUM-SUBARRAY的运行时间了,就像上一篇分析归并排序那样,对问题进行简化,假设原问题的规模为2的幂,这样所有子数组的规模均为整数。
第1行花费常量时间。当n=1时,直接在第二行return后跳出函数,因此
T(1)=Θ(1)
当n>1时,为递归情况。第1行和第3行都花费常量时间,第4行和第5行求解的子问题均为n/2个元素的子数组,因此每个子问题的求解总运行时间增加了2T(n/2)。第6行调用FIND-MAX-CROSSING-SUBARRAY花费Θ(n)时间,第7行花费Θ(1)时间,因此总时间为
T(n)=Θ(1)+2T(n/2)+Θ(n)+Θ(1)=2T(n/2)+Θ(n)
在上面的步骤中,将Θ(1)省略掉的作法大家应该都理解吧。
回顾前面n=1的情况,第一行花费了常量时间,第二行同样也花费了常量时间,但这两步花费的总时间却是Θ(1)而非2Θ(1),这是因为在Θ符号中已经包含了常数2在内了。
但是为什么第4行和第5行中却是2Θ(n/2)而非Θ(n/2)时间呢?因为这里是递归呀,这里的因子就决定了递归树种每个结点的孩子个数,因子为2就意味着这是一颗二叉树(也就是每个结点下有2个子节点)。
如果省略了这个因子2会发生什么呢?不要以为就是一个2这么小的数而已哦,后果可严重了,看下图……左侧是一棵4层的树,右侧就是因子为1的树(它已经是线性结构了)。
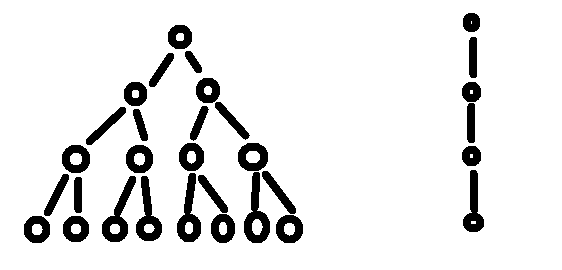
总结来说,渐近记号都包含了常量因子,但递归符号却不包含它们。
借助递归树求解递归式
前面我们已经看到了递归式,也看到了递归树,那么如何借助递归树来求解递归式呢?接下来就来看看吧。
在递归树中,每个结点都表示一个单一问题的代价,子问题对应某次递归函数调用。
通过对树中每层的代价进行求和,就可以得到每层的代价;然后将所有层的代价求和,就可以得要到所有层次的递归调用的总代价。
我们通常用递归树来得出一个较好的猜测结果,然后用代入法来证明猜测是否正确。但是通过递归树来得到结果时,不可避免的要忍受一些”不精确“,得在稍后才能验证猜测是否正确。
因为下面的示例图太难用键盘敲出来了,我就用了手写,希望大家不介意。
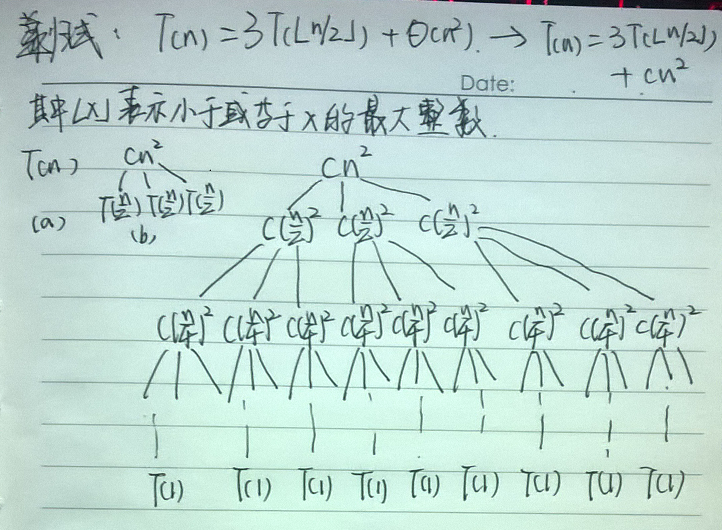
如下所示,有一个递归式,我们要借助它的递归树来求解最终的结果。前面所说的忍受“不精确”这里就有2点:
1)我们要关注的更应该是解的上界,因为我们知道舍入对求解递归式没有影响,因此可以将Θ(n2)写成cn2,且为该递归式创建了如下递归树。
2)我们还将n假定为2的幂,这样所有子问题的规模均为正数。
图a所示的是T(n),在图b中则得到了一步扩展的机会。它是如何分裂的呢?递归式的系数为3,因此有3个子结点;n被分为2部分,因此每个结点的耗时为T(n/2)。图c所示的则是更加进一步的扩展,且直到最后的终点。
这棵树有多高(深)呢?
我们发现对于深度为i的结点,相应的规模为n/2i。因此当n/2i=1时,也就意味着等式i=log2n成立,此时子问题的规模为1。因此这个递归树有log2n+1层。那为什么不是log2n层呢?因为深度从0开始,也就是(0,1,2,...,log2n)。
有了深度还需要计算每一层的代价。其中每层的结点数都是上一层的3倍,因此深度为i的结点数为3i。而每一层的规模都是上一层的1/4,所以对于i=0,1,2,...,log4n−1,深度为i的每个结点的代价为c(n/2i)2。
因此对于i=0,1,2,...,log4n−1,深度为i的所有结点的总代价为(3i)∗(c(n/2i)2),也就是3ic(n/2i)2。
递归树的最底层深度为log2n,它有3log2n=nlog23个结点,每个结点的代价为T(1),总代价就是nlog23T(1),假定T(1)为常量,即为Θ(nlog23)。
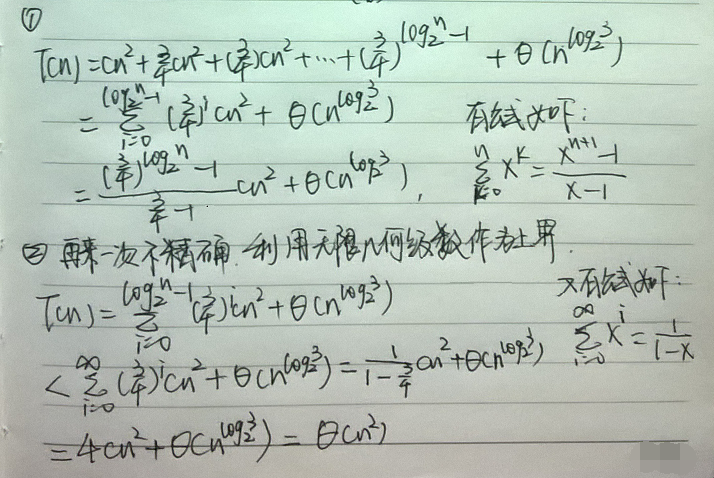
至于这最后的4c为什么可以直接省略掉,如上一节所说的,渐近记号都包含了常量因子。因此猜测T(n)=Θ(n2)。在这个示例中,cn2的系数形成了一个递减几何级数。由于根结点对总代价的贡献为cn2,所以根结点的代价占总代价的一个常量比例,也就是说,根结点的代价支配了整棵树的总代价。

不知道大家看不看得清,上面的两行文字是“我们要证的是T(n)≤dn2对某个常量d>0成立,使用常量c>0“和”当d≥4c时,最后一步成立。
写一篇博客本来不会这么漫长的,可是这是算法,结果就不一样了……
感谢您的访问,希望对您有所帮助。 欢迎大家关注、收藏以及评论。















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









