






关于爬虫的有效链接:
https://blog.csdn.net/ccg_201216323/article/details/53576654
http://www.cnblogs.com/Jims2016/p/5877300.html
https://blog.csdn.net/zhengshidao/article/details/72845794
系列文档的链接
https://blog.csdn.net/qy20115549/article/details/52203722
有关网页爬虫的几个重要文件说明。
网络爬虫基础学习篇
网络爬虫的爬行策略分为深度优先(每一步一直走到最底层)和广度优先(一层一层的走)
跟网页有什么关系
爬虫的一般步骤
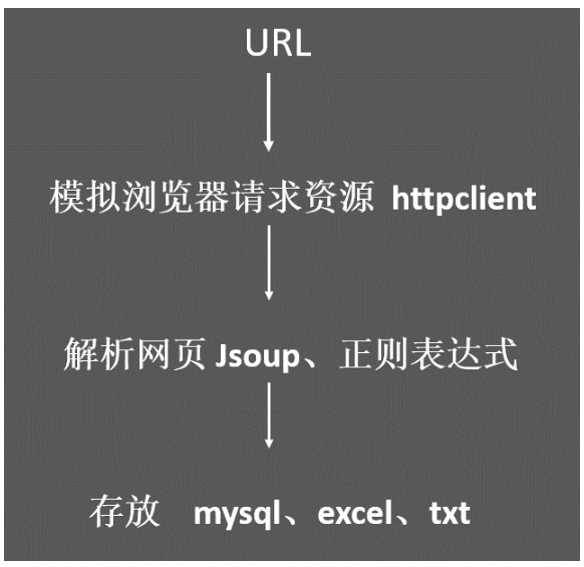
首先是给定一个待爬取的URL队列,然后通过抓包的方式,获取数据的真实请求地址。接着采用httpclient模拟浏览器将相应的数据抓取下来(一般是html文件或者是json数据)。由于网页中的内容很多,很复杂,很多内容并不是我们需要的,所以我们需要对其进行解析。针对html的解析很简单,通过Jsoup(Dom解析工具)、正则表达式便可完成。针对Json数据的解析,这里我建议一款快速解析工具fastjson(阿里开源的一个工具)
(1)网络网络抓包,(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,经常被用来进行数据截取等。在针对数据响应为Json或者需要针对需要用户名、密码登陆的网站,抓包显得尤为重要,抓包也是编写网络爬虫的第一步。其可以直观的看到数据请求的真实地址,请求方式(post、get请求),数据的类型(html还是Json数据)
HTTP部分状态码的说明
HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码。当我们打开一个网页时,如果网页能够返回数据,也就是说影响成功了,一般状态响应码都是200。当然状态响应码,包括很多内容,下面列举了,状态响应码,及其表示的含义,其中加错的是在爬虫中经常遇到的:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
网络爬虫涉及到的Java基础知识:
1.Java中maven的使用。
使用maven能很轻松的从网络中下载所需的插件
及依赖(下载程序所依赖的JAR包),存储在某一位置中,在程序编译时自动去寻找jar包。
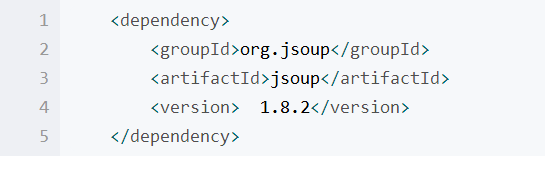
使用maven最大的方面,在ecliplse中建工程的时候,我们选择maven工程。如下图所示,maven工程上面会有一个M的标致,同时生成一个pom.xml文件,通过在pom.xml中加入以下类型的文件,便可把jar包引入到Maven Dependencies中。
2.log4j日志的信息控制与文件的读写控制流
3.添加jsoup开始进行爬虫实例。jsoup是个jar包,引入方法如下所示:

跑第一个demo实例的时候,出现如下错误:
PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at com.sun.net.ssl.internal.ssl.Alerts.getSSLException(Alerts.java:174)














 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









