







一、事务
1、事务的简介
事务的本质核心就是锁和并发。 事务只是让传统意义上难以理解的事情用一种更容易让大家理解的方式来表述的方法。事务比传统意义的锁和并发更容易让大家理解。

2、单个事务单元
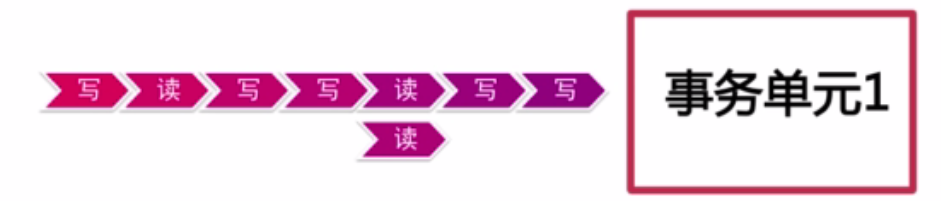
- Bob给Smith100块的一个事务案例会进行一下操作(图1):
 (图1)
(图1)
- 锁定Bob账户
- 锁定smith账户
- 查看Bob是否有100
- 从Bob账户中减少100块
- 给Smith账户中增加100块
当锁定Bob账户和锁定Smith账户之后,只有一个请求(一个线程)可以进入到里面去操作账户。线程2和线程3发现有锁,只能在外面等待。上面的3、4、5都可以用线程1来完成。只有线程1可以看到他们的中间状态(3、4、5)。线程2和线程3都看不到中间状态。在一个事务单元结束之前,其他的线程只能等待在锁外的。所以线程2和线程3只能看到要么Bob账户中有钱,要么Smith账户中有钱。
假设在从Bob账户中减少100块的步骤结束后,就解除锁的状态,当线程2和线程3访问Bob的账户和Smith的账户,就会发现Bob和Smith的账户都为0,就会出现数据不一致的情况(图2)。
 (图2)
(图2)
所以事务要保证的事情就是一致性,要么Bom有100块,要么Smith有100块(一致性)。Bob有100块或者Smith有100块的时候只要被线程2或线程3访问到,就必须是持久的,不能在回退到之前的状态(持久性)。这个过程就是一个事务单元。这个过程就可以保证A(一致性)I(原子性)D(持久性)。
3、其他的事务单元
- 商品要建立一个基于GMT_Modified的索引。索引列创建的过程也是一个事务单元。
- 从数据库中读取一行记录。也是一个事务单元。
- 向数据库中写入一行记录,同时更新这行记录的所有索引。也是一个事务单元。
- 删除整张表。
- 针对于数据库的每一个操作可以认为都是一个事务。
4、一组事务单元(事务单元和事务单元的关系)
4.1、假设有三个账户(Bob账户、Smith账户、Joe账户)(图3):
- 第一个事务单元:Bob给Smith100块。在这个事务单元内要锁住Bob的账户和锁住Smith的账户,才能完成操作。在这个事务单元没有完成的时候,第二个事务单元进入。
- 第二个事务单元:Smith100给Joe100块。这个事务单元会尝试锁住Smith和Joe的账户。因为Smith的账户被第一个事务单元锁定,这个事务单元只能等待在外面直到第一个事务单元完成以后,第二个事务单元才能进行。
- 第三个事务单元:Smith给Bob100块。这个单元也会等在Bob和Smith的锁上。
 (图3)
(图3)
整个系统内会有三个事务单元,只有一个事务单元完成以后才可以让其他的事务单元进入到里面拿到这把锁。每一个事务单元在运行的过程中的时候,看到的数据不会出现中间状态(Bob给Smith100块,Bob减少了钱,而Smith没有加上)。如果以这种方式考虑事务单元的关系,系统没有办法做到很清晰。事务单元的关系本身非常复杂。一些前辈就抽象了事务单元之间的关系(4.2章节)。
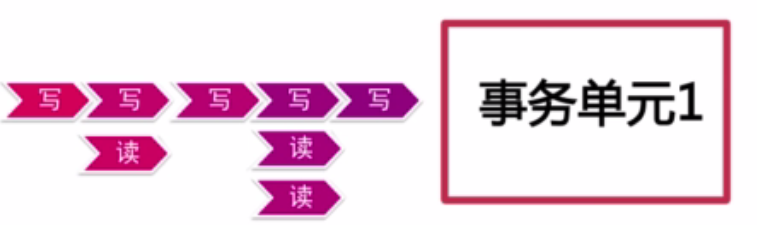
4.2、事务单元之间的Happy-before关系(抽象化的事务单元的关系)(图4):
- 读读
- 写读
- 读读
- 写写
 (图4)
(图4)
把这四种状态映射到所有的事务单元之间的关系,都是这四种状态的重复(引自:事务处理)。
4.3、如何最快速度完成多个事务单元
- 在满足的各种各样事务单元之间的关系后,仍然可以让系统以非常快的速度运行。
- 在处理多个事务单元关系的时候,不会出现数据不一致的情况。

4.3.1、排队法:序列化读写 (把所有的请求放入队列里)SERIALIZABLE(图5):
![]() (图5)
(图5)
优点:不需要冲突控制。
缺点:慢速设备。如果一旦一个队列里的某一个请求非常慢,因为所有请求都不能并行,会导致系统性能非常低。
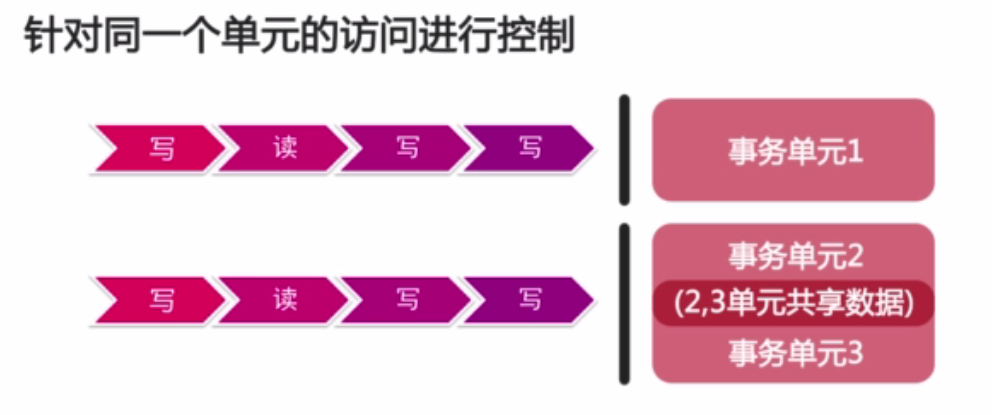
4.3.2、排他锁:针对同一个单元的访问进行控制(把一个队列分散到很多队列里)(图6):
- 我们可以把一个队列分散到许多队列里(用锁来实现的)。
 (图6)
(图6)
假设有3个事务单元。事务单元1锁住了两行记录。事务单元2和3共享了一个事务记录。只要保证事务单元数据没有出现冲突,事务之间就不应该出现冲突。(比如:Bob给了Simth100块,李雷给了韩梅梅100块)。Bob给了Simth100块,李雷给了韩梅梅100块这两个事务单元完全没有冲突。如果在完全没有冲突的情况下,事务单元完全可以并行起来。因此
- 事务单元可以出现并行的场景(Bob给了Simth100块,李雷给了韩梅梅100块。他们互不影响)(图7):
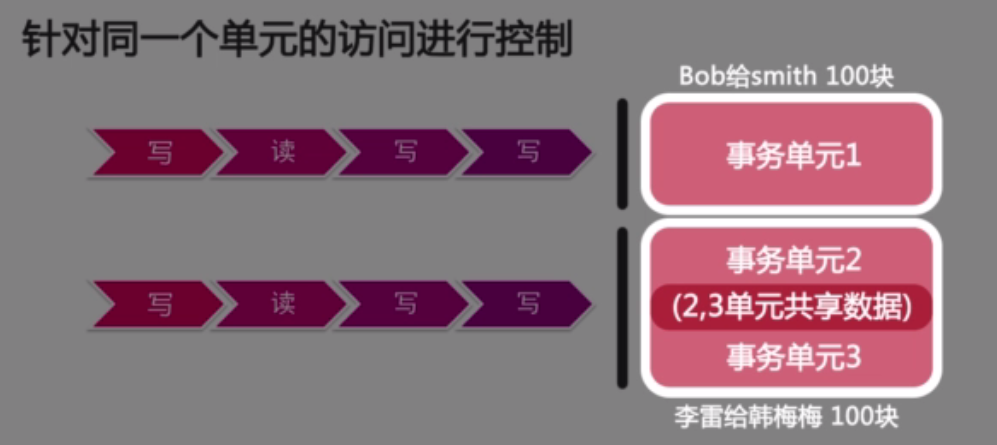 (图7)
(图7)
- 事务单元不可以出现并行的场景(李雷给了韩梅梅100块,韩梅梅给了李雷100块。这两个事务单元会共享数据)(图8):
 (图8)
(图8)
结论:如果事务单元之间有可能发生冲突,就让它们串行。如果不发生冲突,完全可以并行。实现这种方式只要在一个事务单元加锁就可以实现。只允许一个线程访问。这种加锁的方式,其它事务单元自然而然不会在上一个事务单元还没有结束前就可以访问。系统就可以通过加锁的方式来实现并发。同时又可以实现读读、写读、读写、读读。在保证数据一致的情况下,有没有更好的办法实现更高的速度呢?
4.3.3、读写锁
事务单元之间的关系有四种场景:读写、写读、读读、写写。如果可以把它们分离开,就可以让读完全并行。读和读的场景完全并行,而写读、读写、写写仍然串行。对于读多写少的情况下,可以更近一步的提升系统性能。传统数据库主流的做法就是写和读之间完全分开(图9)。
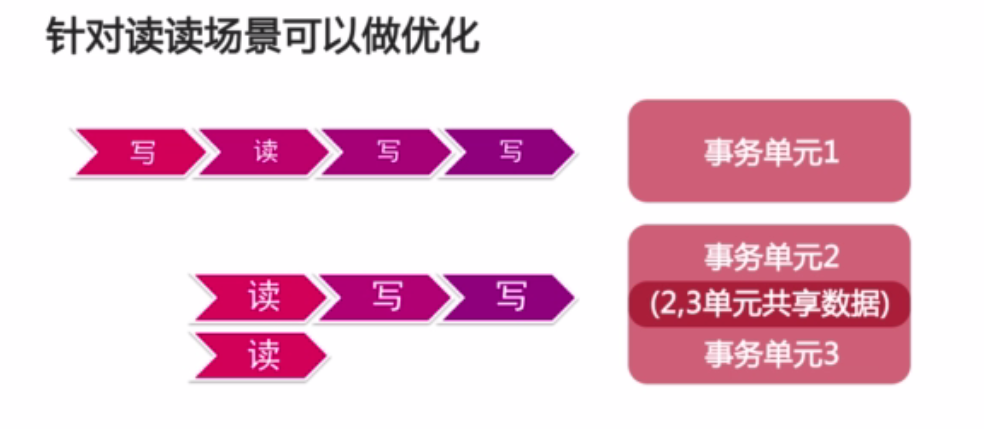 (图9)
(图9)
因为、读和读的场景完全并行,而写读、读写、写写仍然串行的情况下,才会出现隔离性的不同的隔离级别。
- 可序列化:读写放入队列里串行。
- 可重复读:如果读锁后面有一个写锁,写锁就只能等待读锁释放后才能进入本行记录。如果第一次读成功了以后,事务没有释放的情况,在发生一次读的事务,因为锁没有释放,所以它仍然可以读到数据之前的状态。因为后面的写( W )还没有发生,它在外面等待。所以整个系统就可以保证读到的数据是上一次读到的数据。但是可重复读无法做到读写并行,只能做到读和读之间的并行。如果是先读后写的场景是没有办法并行的。先写后读的场景也没有办法并行。(图10)。
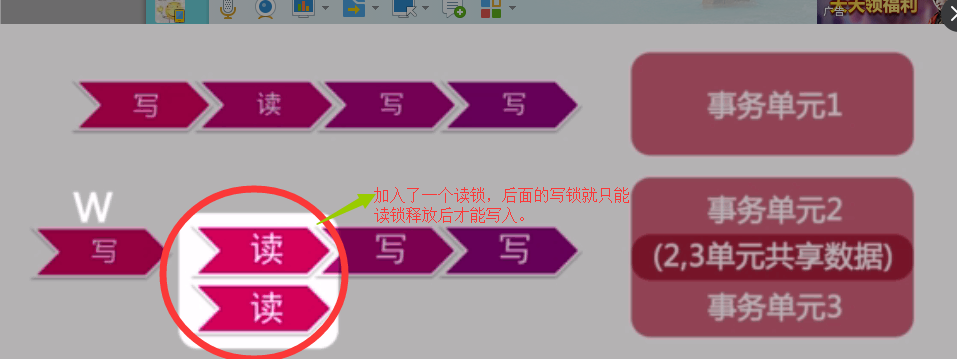 (图10)
(图10)
- 读已提交:读写并行
把读的锁彻底的去掉。读的时候如果不加锁,只有写的时候加锁(读的时候如果有个新的锁进来,就让它进入)。系统的并行读可以进一步提升。代价就是第一次读的时候,可能是一条数据。第二次读的是另外的数据。这个场景下可以解决读写、读读的并行,但不可以解决写读、写写的并行,写写、写读、仍然是串行的。因为每次写的事务单元都是加锁的。
总结:隔离性(I) 本身就是对于传统数据库的一致性的一种破坏。最强的一致性一定是读写放入队列里串行的。
4.3.4、MVCC(多版本并发控制)Copy on Write 写不阻塞读
当加了写的操作的时候,系统完全可以并发读。现在主流的数据库都在使用这种方式。这种方式可以做到写读不冲突、读读不冲突、读写不冲突。唯一冲突的就是写和写。这种方式并发度更高,实现起来更复杂。这个场景下可以解决读写、读读写读、的并行,但不可以写写的并行,写写仍然是串行的。(图11)。
 (图11)
(图11)
4.4、事务处理的常见问题
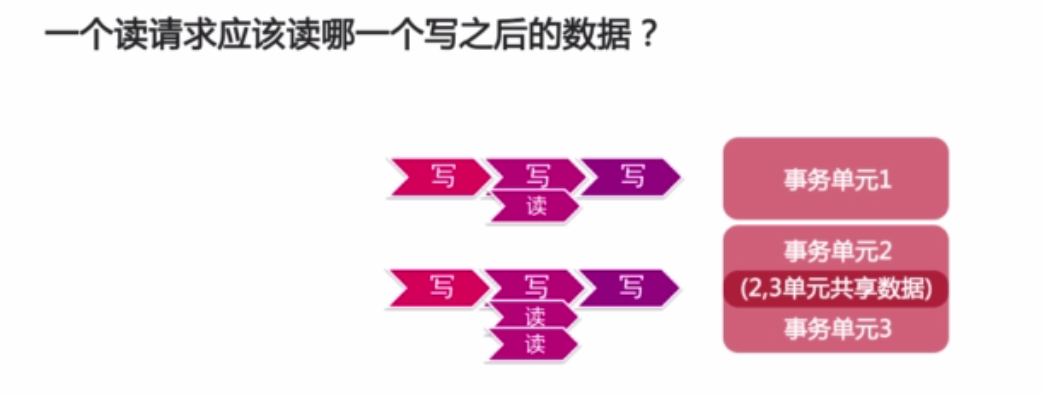
4.4.1、多个事务,谁先谁后?(图12)
 (图12)
(图12)
当发生写的时候,数据库就会记录一个版本号。当读的时候也会记录一个版本号,当读的版本号大于写的版本号才可以。
逻辑时间戳(只是保证先后顺序):Oracle :SCN 。Innerdb : Trx_id 。
内存里面维持一个自增号,每一次写的时候就把自增号+1。这样就可以读到数据本身的最新值。如果读的时候在一个事务内读的话,内存里自增号也会+1。通过自增的ID号就可以保证事务本身的先后顺序。
4.4.2、如何故障恢复?
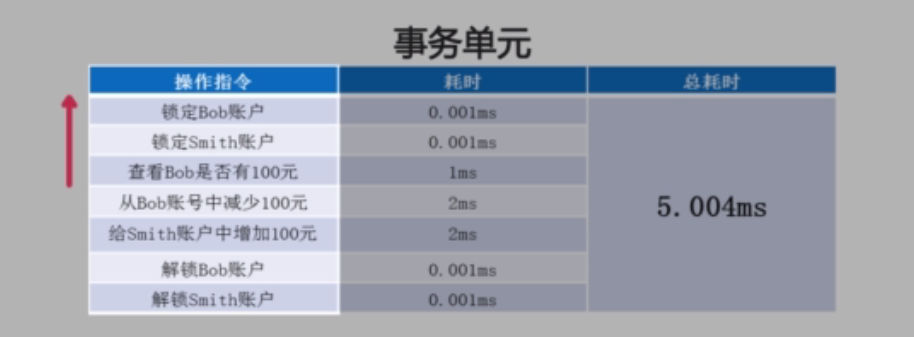
4.2.1、业务属性不匹配(图13)
 (图13)
(图13)
当Bob的账户里没有100块的时候,事务就需要回滚。需要记录当前事务之前在做的所有操作的反向操作。这样的情况下。如果业务属性出现问题,就可以调用回滚的方式,来恢复到之前数据没有发生到任何更改的状态。
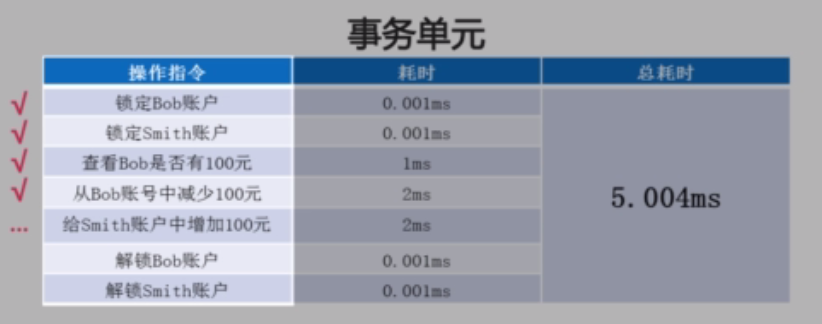
4.2.2、系统的崩溃(图14)
 (图14)
(图14)
当一个事务单元做完第四步(从Bob的账户中减少100元)第5步(给Smith的账户中增加100元)还没有来得及做的时候,整个系统崩溃了。必须需要再恢复回来。在进行数据恢复的时候还没有从故障中完全恢复回来的时候,系统不能够被外部的其他应用访问的。 数据库系统本身对外暴露一个监听,为了防止数据库出现故障。
4.3.3、碰到死锁了怎么办?
4.3.3.1、死锁产生的原因(图15)
- 两个线程
- 不同方向
- 相同资源
 (图15)
(图15)
相互等待,相互又维持了一个锁。
4.3.3.2、解决方案
1、尽可能不死锁(降低隔离级别:比如说读不加锁)。
2、碰撞检测(终止一边)(图16)
 (图16)
(图16)
3、等锁超时
五、深入单机事务
5.1、怎么才能做到事务的ACID
- 原子性
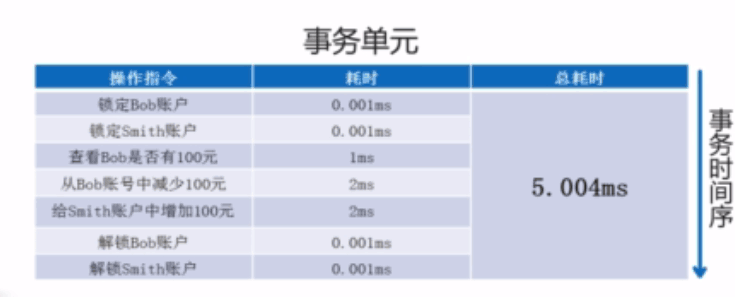

还是这个图(Bom给Smith100块的事务单元)。假设Bob账户有100块,Smith账户有没有钱,这样就可以把一个事务单元分成多个步骤:
- version 1 :Bob有100元 Smith有0元
- version 2 :Bob有0元 Smith有0元
- version 3 :Bob有0块 Smith有100元
第一个操作先检查Bob账户有没有100元,发现Bob有100块,就会进入第二个操作(将Bob的钱取出100块)。Bob的钱就为0元。Smith的钱也是0。接着进入第三个步骤(将Bob的100块加到Smith的账户中去)。Bob的钱就为0元,Smith的钱为100元。

任何系统内出现的故障,都有可能导致系统回滚。比如说在第二个版本会出现的问题是:如果Smith账户不存在的话,必须到回滚到第一个版本的状态(Bob有100元,Smith有0元)。

如果在最后提交事务的时候超时了,事务就要回滚到第二步的状态(Bob有0元,Smith有0元)

前面两种回滚状态都需要面对同一个问题,都需要知道回滚到哪里去。数据库就会加入回滚段,数据库把这些回滚段记录到单独的地方去(如:日志表)。在版本2的时候记录一个回滚端(Bob有100元,Smith有0元)。如果第二个状态需要回滚,只需要把undo的信息(Bob有100元,Smith有0元)直接回溯到这个账户上。
这就是原来事务处理自动化操作的一个逆向操作。

如果在第三个版本中,发现Commit没有成功,就会先回滚到上一个版本(先把Smith的钱减掉)。接着再回滚到上一个版本(Bob有100元,Smith有0元)。这种操作就是原子性的保证(要么全部成功,要么全部失败)。原子性操作不涉及到一致性相关问题的。原子性的语义只保证一个回滚段,这个回滚段能回滚到之前的版本。
如果有另外的一个事务进入到版本2的时候,把Smith的账户进行了修改(假设把Smith的钱加了300块钱)。同时事务一出现了故障,进行回滚,回将Smth的钱改为0。这种情况(在一致性不保证的情况下)就会出现300块钱丢失的问题。但是从原子性的定义来说,原子性不关心(care)这件事。


原子性只记录了一个undo日志回滚到之前的版本而已。

- 一致性
一致性的核心就是Can(happen before):

如果事务之间按照并列的关系来排列整个系统没有任何一致性问题。
假如两个事务同时发生的时候,就会有一致性问题(视点3)。:如果事务2出现问题之后进行回滚,两个事务就会出现冲突的情况(如:更新丢失、数据不一致问题)。

整个系统问题核心就是如何处理视点3(有读的请求,也有写的请求)(事务4)也就是如何处理不同事务之前的读写并行,就是处理一致性的部分。
一个事务单元要保证一个事务单元全部成功以后才可见,这就是一致性的保证。如果说一个事务单元全部处理成功以后,下个事务才能进来,整个系统一定是一致性的。
但是这样做的话系统的并发度明显耗时。因此系统不的不选择另外一个概念,就是隔离性。
- 隔离性(隔离性就是以性能为理由,对一致性的破坏。)
如果所有的事务都是(happy-before)的关系的时候绝对能够保证事务单元的强一致性。

如果利用这种方式进行操作的时候,所有的事务单元理论上说都是串行的(序列化)。序列化读写(排他锁)串行就会非常严重的影响系统的性能。单位时间内只有一个事务单元能够进入。
性能差一定是认为是不可取的。
有没有更好的方式呢?:读写锁:
1、可重复读(Repeatable read):
它的核心是读写锁:一个很重要的概念是:读锁能不能被写锁升级。假如说对一个事务单元加一个读锁的情况下,如果有一个写写进来,之前的读锁要不要放开,让这个写进去。假如读锁不打开,不让写进去。只能做到读读并行。这种情况只能做到读读并行,不能完美的提升系统性能的。
2、读以提交(Read Committed):
就会出现幻读和不可重复读为什么会产生。读已提交也是一个读写锁,不一样的是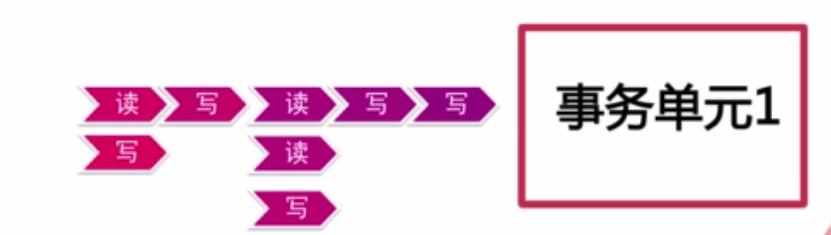
读锁可以被写锁升级。如果一个新写锁进来的时候,就可以将原来的读锁升级为写锁。 就会有一种新的模式:读写也可以并行。这样很多请求就可以往前提了。每一次将请求往前提的过程就可以认为都是增加的并行的情况。
在读已提交的时候为什么会出现不可重复读。?
读写并行的话会出现下面的场景:第一次读取完成以后,读到一条数据(版本号为1),因为第二次写是并行的,所以第二次写会更新到这个数据。于是下个事务的读在进来的时候 就会发现原来事务新的数据已经被更改过了。第一次读数据和第二次读的数据之前数据读的版本是不同的。于是就会出现不可重复读。因为读锁可以升级为写锁,就会出现同一个事务内的两次读可能会读到不同版本的问题。
3、读未提交:只加写锁,读不加锁。
读读并行、读写并行、写读也可以并行。
全部的写是串行的,所有的读都可以并行。这种方式带来的问题。
可能读到写过程中的数据。可能会读到内部没有提交完成的数据。因为读没有加锁。会读到中间状态的数据。
总结:

就是因为有读写锁,然后这些读写锁各种各样的组合就会出现不同的隔离级别。因为有读写锁,读能不能升级,又被分出来两个隔离级别:读以提交,读未提交。
隔离性小结:

四个不同的隔离级别是SQL92定义的标准的隔离性。
除了那四种标准的隔离级别之外,还有一种新的隔离级别出现:快照隔离级别(MVCC)。核心思路:无锁编程。Copy on Write.


快照读的核心方法(刚刚都是用锁来实现的):
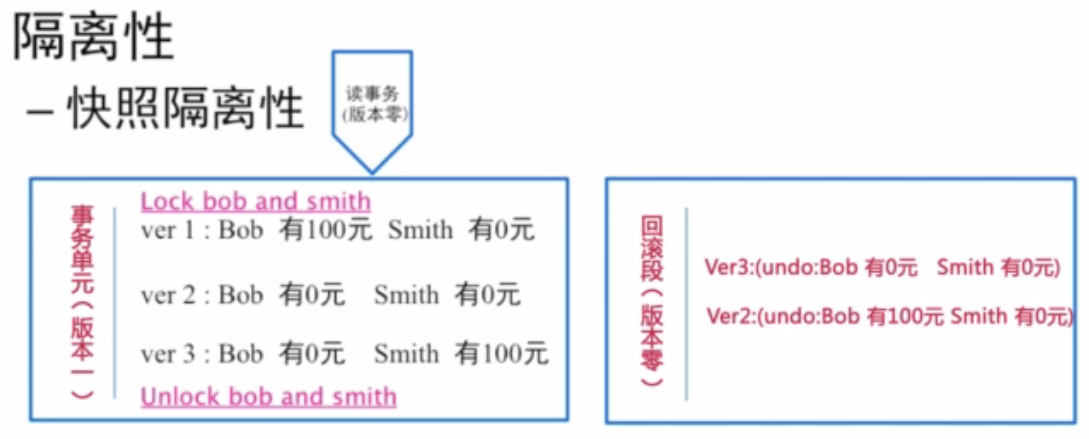
事务开始之前的版本让你先读到。
- 持久性
每一次的写都要落到磁盘上,保证数据的持久性。事务完成之后,该事务对数据库的所做的更改便持久的保存在数据库之中。
但是,如何保证数据不丢?:RAID特性:如果将数据只写到1块A磁盘,如果A磁盘坏了,数据仍然不会丢失呢?就在Copy一份数据到另外一个磁盘上。
1、磁盘的物理损坏
2、
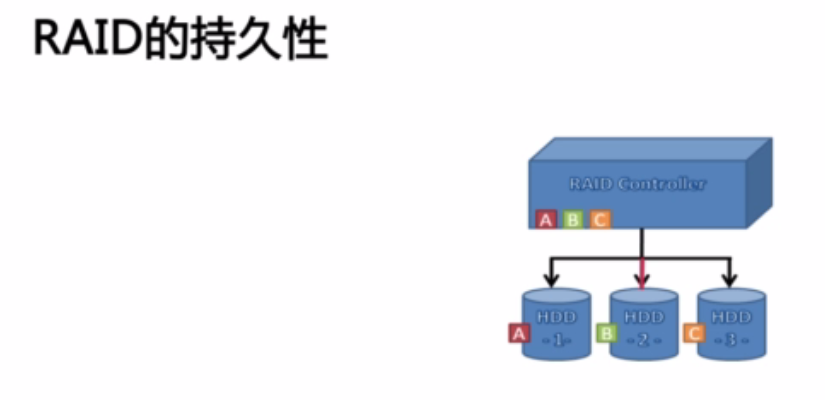
事务:多个不同的命令组装到一起的过程。
5.2、单机事务典型异常应对策略(实现事务过程中会经常碰到的一些问题)
任何看起来相对简单的东西,背后其实要考虑的因素,远远超过你现在所想象的。
1、业务属性不匹配,需要回滚
2、系统的DOWN机:计算机就是个打字机。


如果走到第一步,当Lock的时候DOWN机了。

事务原子性操作只有一个标记:commit。如果commit之前所有的请求都要回滚。当commit完成的时候,之后的请求必须正常的提交完成并且必须可见。
数据库重启后进入recovery模式。会将提交后的事务单元继续完成提交。未提交事务单元回滚。在这期间,整个系统是不能被访问的。只有当所有recovery结束以后,将没有提交的返回回去。将提交后的继续完成。在这操作结束以后才会真正开始提供外部访问。(recovery过程也类似于原子操作,也必须保证ACID,只是实现方法不一样)

如果recovery(恢复)的时候又挂了,在重启需要继续recovery。因此在recovery的时候也要记录日志,保证数据不会丢失。

5.3、事务的调优原则
1、减少锁的覆盖范围。(Myisam表锁 -->Innodb行锁)。将一个大锁变为多个小锁。

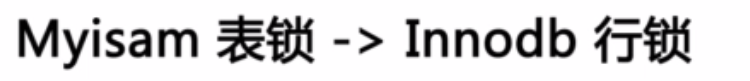
2、增加锁上可并行的线程数。

3、选择正确的锁类型:

单机事务小结
1、读写比例比较高的情况 MVCC

2、


3、

4、调优

二、单机事务拾遗
-
事务单元扩展
-
死锁扩展 - U锁
读锁。写锁分离
-
MVCC拾遗
三、分布式事务
1、分布式事务的目标
像传统单机事务一样的操作方式。可按需无限扩展

2、分布式事务与单机事务的相同点和不同点
3、传统数据库的分布式事务
4、分布式事务面临的问题
2、分布式事务流行的解决方案 (Google Spanner、DRDS/TDDL)
四、参考链接:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









