







AntDB3.1版本与2.2版本相比,性能上做了很大改善
1、支持并行计算(继承Postgres9.6新增并行功能);
2、优化执行计划,将计算尽量下放到datanode上,然后在coordinator上汇总,而不是如2.2那样,将数据上拉到coordinator上计算;
3、支持datanode之间,datanode和coordinator之间数据reduce,当要查询的数据分布不平衡时,将数据reduce到一个节点上计算,最大限度提高查询效率。
下面是和提高性能相关的重要参数。下面将举例说明参数的使用。
enable_cluster_plan
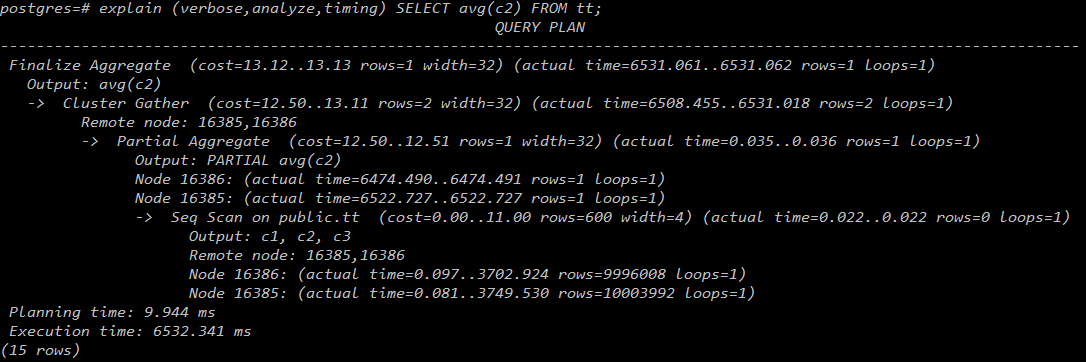
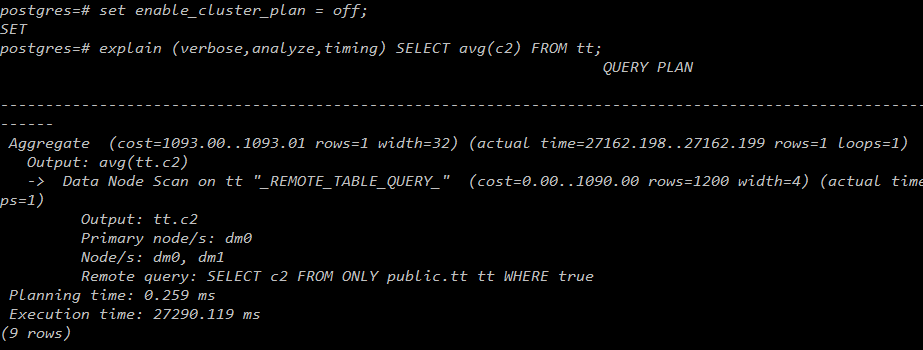
3.1与2.2相比,在性能上做了很多优化。打开此开关,会走3.1的执行计划,会大幅提高性能。
下面的同样的查询语句在打开开关和关闭开关的情况下,执行计划不同,打开开关后,查询时间大大缩短。
pgxc_enable_remote_query = off
打开开关:
关闭开关:
max_parallel_workers_per_gather
这个参数决定了每个gather最多允许启用多少个work process
max_worker_processes
这个参数决定了每个节点在同一时间允许启动多少个work process。
这两个参数共同决定在datanode和coordinator上启动多少个worker,worker数量决定
另外,执行计划是在coordinator上生成的,建议在coordinator和datanode上参数设置一样,否则,datanode上的最终值是二者较小值。
下面举例说明这两个参数配置对执行计划和效率的影响。
postgres=# create table aa(a1 int, a2 int);
CREATE TABLE
postgres=# copy aa from '/home/mass/data/big_ranint_int_10million.sql' with delimiter as ',';
COPY 10000000
postgres=# analyze aa;
ANALYZE
postgres=# explain(verbose, analyze) select count(*) from aa;
下面开始通过设置参数来控制worker的数量,来测试查询效率随worker和datanode数量的关系。
max_parallel_workers_per_gather =2
max_worker_processes = 3
最终启动2个worker
2个datanode:
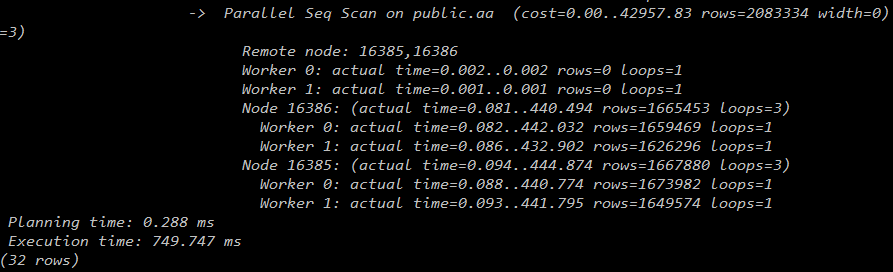
3个datanode:
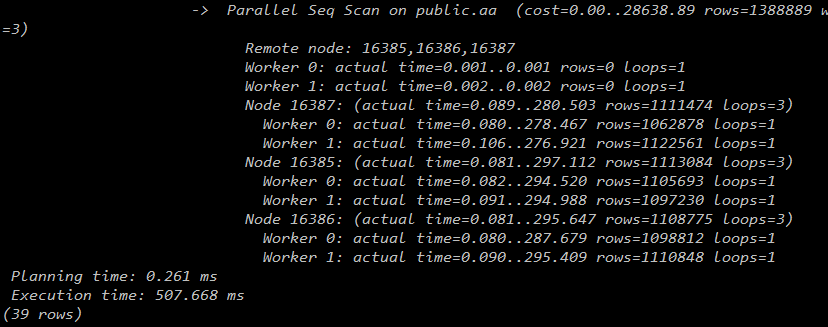
4个datanode:
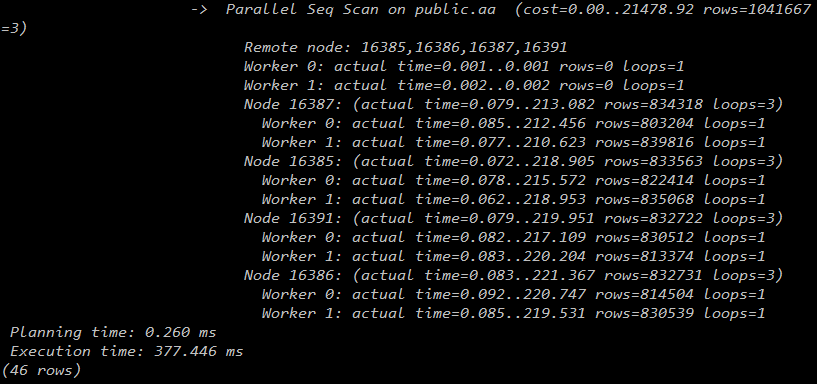
max_parallel_workers_per_gather =4
max_worker_processes = 3
最终启动3个worker
2个datanode:
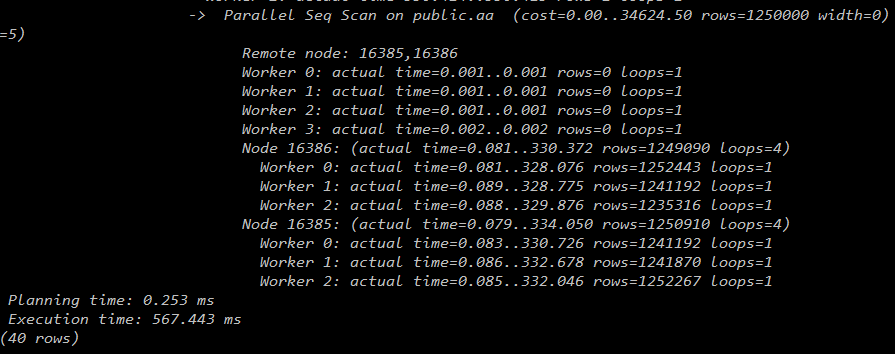
3个datanode:
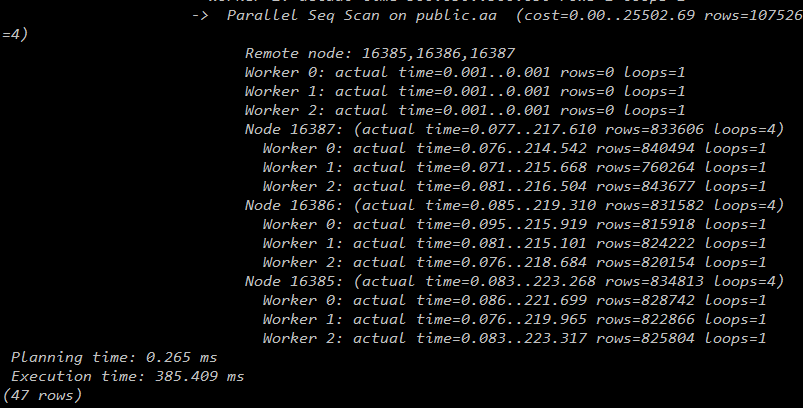
4个datanode:
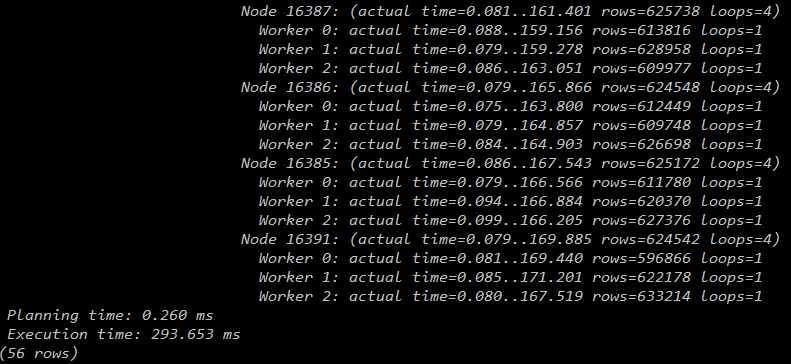
max_parallel_workers_per_gather =4
max_worker_processes =4
最终启动4个workers
2个datanode:
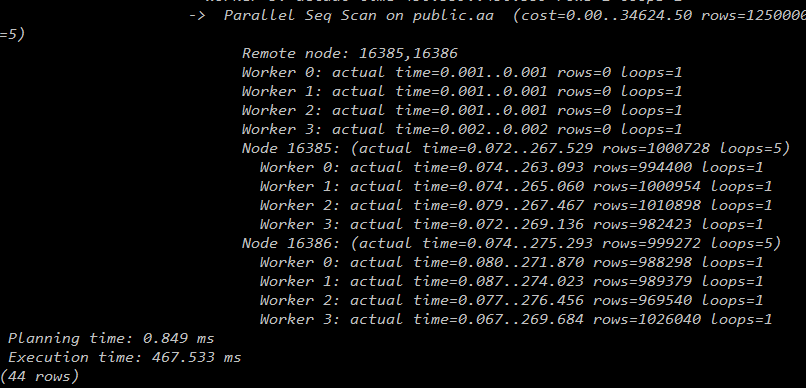
3个datanode:
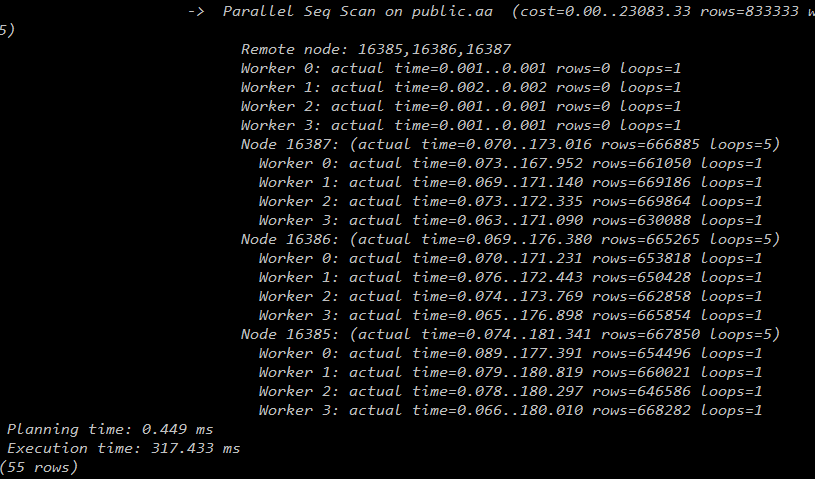
4个datanode:
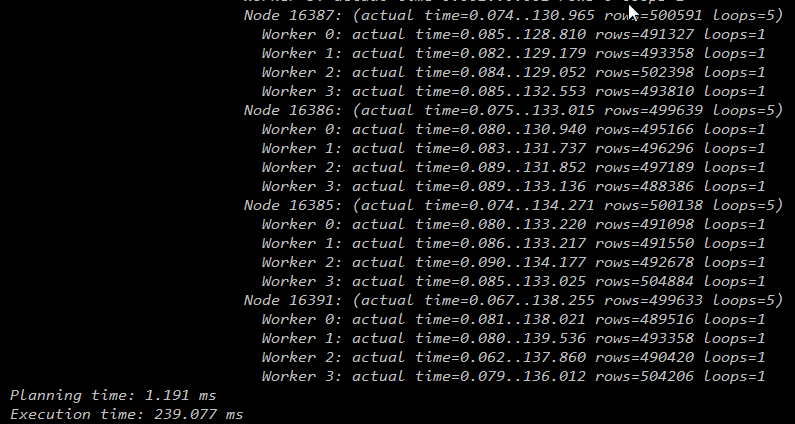
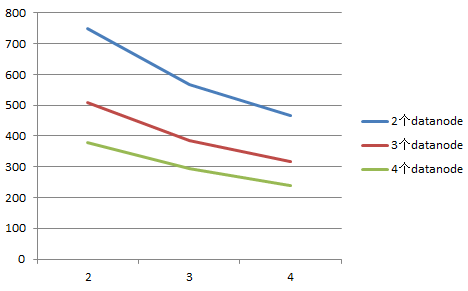
从下图可见,随着datanode的增加,worker数的增加,查询时间越来越少
参考:
QQ交流群:496464280
源码地址:http://github.com/ADBSQL
欢迎广大postgresql爱好者使用和交流。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









