







Local and distributed query processing in CockroachDB
原文引自
https://www.cockroachlabs.com/blog/local-and-distributed-processing-in-cockroachdb/
与本文相关的文档:
1.Executing Parallel Statements to Improve Performance
2.Parallel Statement Execution
When a CockroachDB node receives a SQL query, this is approximately what happens:
当CockroachDB 节点收到一个SQL语句,大致发生了以下过程:
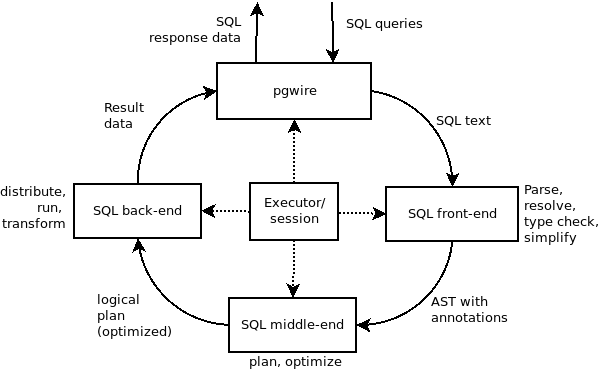
The pgwire module handles the communication with the client application, and receives the query from the client. The SQL text is analyzed and transformed into an Abstract Syntax Tree (AST). This is then further analyzed and transformed into a logical query plan which is a tree of relational operators like filter, render (project), join. Incidentally, the logical plan tree is the data reported by the EXPLAIN statement.
pgwire 模块负责与客户端应用程序的通信,接收来自客户端的SQL,并把分析后的SQL 文本传给抽象语法树(AST),作进一步的分析处理,并转换为带有关系运算的逻辑查询计划,比如like匹配,投影,连接。同时也提一下,逻辑执行计划树的信息是explan 语句生成的。
The logical plan is then handed up to a back-end layer in charge of executing the query and producing result rows to be sent back to the client.
There are two such back-ends in CockroachDB: a local execution engineand a distributed execution engine.
逻辑计划移交给负责执行查询的后端层, 并生成要发送回客户端的结果行。
在 CockroachDB 这样的后端层主要有两个: 一个本地查询引擎,一个分布式查询引擎。
Local query processing
本地查询处理
The local execution engine is able to execute SQL statements directly on the node that a client app is connected to. It processes queries mostly locally, on one node: any data it requires is read on other nodes in the cluster and copied onto the processing node to build the query results there.
当客户端的应用程序直接连接上某节点后,本地执行引擎,能够直接这个节点上执行SQL 语句。且在这种情况下,大部份SQ也主要在这个节点处理、对于这个节点来说: 它需要的任何数据,都可以在群集中的其他节点上读取, 并复制到这个节点,并生成查询结果。
The architecture of CockroachDB’s local engine follows approximately that of the Volcano model, described by Goetz Graefe in 1993 (PDF link). From a software architect’s perspective, each node in the logical query plan acts like a stateful iterator (e.g. what Python generators do): iterating over the root of the tree produces all the result rows, and at each node of the plan tree, one iteration will consume zero or more iterations of the nodes further in the tree. The leaves of the tree are table or index reader nodes, which issue KV lookup operations towards CockroachDB’s distributed storage layer.
CockroachDB 本地引擎架构,源自 Goetz Graefe 于1993年提出的火山模型(PDF link)。从软件架构师的角度来看, 逻辑查询计划中的每个节点都像一个有状态的迭代器 (如 Python 生成器):
迭代器先遍历树的根节点,处理根节点中的所有结果行 ,计划树其他每个节点也已同样的方式处理,(在这个过程中)每一个迭代器将处理树中下一个节点的零个或多个迭代的结果。(在下图中)树的叶子节点是对应的表或索引, 它向 CockroachDB 的分布式存储层执行 KV 查找操作。

Example logical plan for:
逻辑执行计划例子:SELECT cust_id, address FROM customer WHERE name LIKE 'Comp%' AND state = 'CA'
Assuming primary key is cust_id and an index on customer(name).
假如主键是 cust_id,索引列为 custer(name)
From a code perspective, each relational operator is implemented as an iterator’s “next” method; while a query runs, the tree of iterators is processed sequentially: each node’s “next” method waits until the source nodes have completed their own “next” method call. From the outside, the query execution logic processes data and makes decisions (e.g. keep/remove a row, compute derived results) row by row. The processing is essentially sequential.
The main characteristic of this engine is that it is relatively simple.
The code for this engine can be reviewed and validated for correctness using only local reasoning; we (the CockroachDB developers) have come to trust it the most.
Also, because the processing is performed locally, it can deliver results very fast if all the data it needs is available locally (on the same node), and/or when there are only few rows to process from the source tables/indices.
从代码的角度来看, 每个关系运算符都是以迭代器的 "next" 方法来实现的;当查询运行时, 迭代器树按顺序处理: 每个节点的 "next" 方法一直等到源节点完成自己的 "next" 方法调用。从外部来看, 查询操作一行行的执行逻辑处理数据并进行决策 (如保留/删除行, 计算派生结果) 。处理基本上是顺序的。
本地引擎的主要特点相对简单。
对于以上引擎的代码,我们 (CockroachDB 的开发者) 基本上可以保证,可以通过仅使用本地推理进行检查和验证其正确性。
此外, 由于该处理过程是在本地完成的, 因此, 对于查询处理中所需的所有数据都可以在本地 (在相同节点上) 找到, 并且/或只有很少的行可以从源表/索引中处理, 那么是可以非常快地返回结果。
(从以上可看出,对于本地查询引擎,适用于查询少的数据)
Parallelized local processing for updates
本地并行处理更新
A common pattern in client apps is to issue multiple INSERT or UPDATE (or UPSERT, or DELETE) statements in a row inside a single session/transaction. Meanwhile, data updates in CockroachDB necessarily last longer than with most other SQL engines, because of the mandatory network traffic needed for consensus.
客户端应用程序中的一个常见模式是,在单个会话/事务内的一行中发出多个插入或更新 (或插入或删除) 语句。这时, CockroachDB 中的数据更新显然会比大多数其他 SQL 引擎持续更长的时间, 因为需要协商一致的网络流量。(理解为:需要保证与其他节点的数据一致性)
We found ourselves wondering: could we accelerate the processing of data writes by executing them in parallel? This way, despite the higher latency of single data-modifying statements, the overall latency of multiple such statements could be reduced.
This is, however, not trivial.
The standard SQL language, when viewed as an API between a client app and a database server, has an inconvenient property: it does not permit concurrent processing of multiple queries in parallel.
我们询思: 我们是否可以通过并行执行写入数据来加快处理速度?这样, 尽管单个数据修改语句的延迟会更高, 然而, 这并不微不足道,因为对于多个这个类似语句话,可以减少总体滞后时间。
对于标准 SQL 语言,当被作为客户端应用程序和数据库服务器之间交互的API时,不允许并行处理多个查询。
The designers of the SQL language, especially the dialect implemented by PostgreSQL and that CockroachDB has adopted, have specified that each SQL statement should operate “as if the previous statement has entirely completed.” A SELECT statement following an INSERT, for example, must observe the data that has just been inserted. Furthermore, the SQL “API” or “protocol” is conversational: each statement may have a result, and the client app can observe that results before it decides which statement will be run next. For example UPDATE has a result too: the number of rows affected. A client can run UPDATE to update a row, and decide to issue INSERT if UPDATE reports 0 rows affected (the row doesn’t exist).
sql 语言的设计者, 指定了每个 sql 语句要执行,要求其前一条语句已经完全执行完毕,特别是 PostgreSQL 和 CockroachDB 所采用的特别sql语法 。例如, SELECT 在insert 语句后,须确保刚刚insert的数据已写入。此外, SQL "API" 或 "协议" 是会话式的: 每个语句都可能有自已的结果, 客户端应用程序可以在决定下一步运行哪个语句之前得到结果。例如,执行 UPDATE 时有结果是: 受影响的行数比较多。客户端可以运行update去更新行, 并确保在更新受影响的行为0时 (该行不存在) 时,执行insert。
These semantic properties of the SQL language are incredibly useful; they give a lot of control to client applications. However, the choice that was made to include these features in SQL has also, inadvertently, made automatic parallelization of SQL execution impossible.
What would automatic parallelization look like? This is a classic problem in computer science! At a sufficiently high level, every solution looks the same: the processing engine that receives instructions/operations/queries from an app must find which operations are functionally independent from the operations before and after them. If a client app / program says to the processing engine “Do A, then do B”, and the processing engine can ascertain that B does not need any result produced by A, and A would not be influenced if B were to complete before it does, it can start B before A completes (presumably, at the same time), so that A and B execute in parallel. And of course, the result of each operation reported back to the app/program must appear as if they had executed sequentially.
With standard SQL, this is extremely hard to determine as soon as data-modifying statements are interleaved with SELECTs on the same table.
这些 SQL 语言的语义属性是非常有用的;他们对客户端应用程序给予了很大的控制。但是, 在 sql 中包含这些功能的选择也无意中使 sql 执行并行化变为不可能。
自动并行化是什么样子?这是计算机科学中的一个经典问题! 在站高的角度来看, 每个解决方案看起来都一样:处理引擎从应用程序接收指令/操作/查询,必须知道哪些操作在功能上与它们前后的操作无关。如果一个客户端应app/程序对处理引擎说 "先做A, 然后做 b", 并且处理引擎能确定 b 不需要任何a的结果, 并且 , 如果 b 是在它之前完成,a 的结果也是不会受影响的, 它可以在 a 完成之前执行b (也可以在同一时间), 使 A 和 B 并行执行。当然, 每个操作的结果返回给app/程序时在显示时有先后,假装是按顺序执行。
对于标准 SQL来说,很难确保,修改语句与在同一表中执行的select 语句像以上方式处理。
In particular, it is hard to parallelize SELECT with anything else, because in order to determine which rows are touched by a specific INSERT/UPDATE, and whether these rows are involved in a SELECT close by, the analysis required would amount to running these statements, and thus defeat parallelism upfront.
尤其是, 为了确定哪些行被insert/update,以及确认是否涉及在select关闭的行,并行执行任意的select是非常难的 ,这些语句所需的分析时间将大于这些语句的执行, 这是也是并行所面临的困难。
It is further impossible to parallelize multiple standard INSERT/DELETE/UPSERT/UPDATE statements, because each of these statements return the number of rows affected, or even data from these rows when a standard RETURNING clause is mentioned, and parallelization would cause these results to be influenced by parallel execution and break the semantic definition that the results must appear as if the statements execute in sequence.
更不可能并行多个标准的insert/delete/update语句, 因为每一条语句都会返回受影响的行数, 甚至是正常返回这些语句时涉及的数据, 并行化将会打破上下文化的定义,导致这些结果受到影响, 为了得到正确的结果,必须顺序执行这些语句。
This is why there is not much CockroachDB can do to parallelize data updates using standard SQL syntax.
这就是为什么使用标准 SQL 语法来去做数据并行处理并不会比 CockroachDB 强。
However, when discussing this with some of our users who have a particular interest in write latencies, we found an agreement: we could extend our SQL dialect to provide CockroachDB-specific syntax extensions that enable parallel processing. This was found agreeable because the one-shot upfront cost of updating client code to add the necessary annotations was acceptable compared to ongoing business costs caused by higher-latency transactions.
但是, 在与一些对写入延迟有特殊要求的用户讨论此问题时, 我们发现并确认: 可以扩展我们的 SQL 语言来帮助 CockroachDB 对特定的语法时行扩展,以实现并行处理。 因为这与高延迟事务导致正常业务成本开销增加相比, 对客户端代码添加必要注释的 one-shot 前期的成本是可以接受的。(不怎么会翻译这句)
The detailed design can be found in our repository. To exploit this new feature, a client app can use the special clause RETURNING NOTHING to INSERT/DELETE/UPSERT/UPDATE. When two or more data-modifying statements are issued with RETURNING NOTHING, the local execution engine will start them concurrently and they can progress in parallel. Only when the transaction is committed does the engine wait until completion of every in-flight data update.
更多的设计细节,可以在我们的知识库中找到。要使用这一新功能, 客户端应用程序可以使用特殊子句 returning nothing, 以实现插入/删除/插入/更新。当使用子句 RETURNING NOTHING 处理两个或两个以上的数据修改语句时, 本地执行引擎将同时启动, 并且并行执行,这时 引擎会一直处理等状态,直到每个 in-flight 数据更新完成,事务提交。
Distributed query processing in CockroachDB
CockrochDB中的分布式查询处理
Next to the local engine, CockroachDB also provides a distributed execution engine. What this does is to delegate parts of the processing required for a single SQL statement to multiple nodes in the cluster, so that the processing can occur in parallel on multiple nodes and hopefully finish faster. We can also expect this to consume less network traffic, for example when filters can be applied at the source.
除了本地引擎,CockroachDB同进还提供 了一个分布式的执行引擎,这样做的目的是,将单个 SQL 语句的部分处理,分布到群集中的多个节点, 这样可以在多个节点上并行进行, 加快完成,减少网络流量开销, 比如, 对数据进行过滤器。
Why, and how?
原理及实现
This blog post details the why and outlines the how. We will dedicate a couple separate articles to further explain how it works.
这篇文章详细说明相应的原因及其实现。我们将在另外的文章中, 更深入的讲解它是如何工作的。
Dispelling the false idols
颠覆传统观念
The usual motivation for a distributed processing engine is the observation that the data for a query is often spread over multiple nodes in the cluster. Instead of bringing the data onto a single processing node, intuition suggests we could ship the computation where the data is stored instead, and save processing time (= make queries faster).
通常,分布式处理引擎是一个观察的角色,知道所查询的数据分布在群集中的多个节点上。而不是把数据传到单一的节点上处理, 直觉告诉我们,可以将计算在存储数据的节点进行, 以减少处理时间 (= 使查询更快)。
However, at a high level, this motivation is weak: if it were for only this motivation, there is a large range of possible solutions that we would have explored besides query distribution.
然而, 站在更的角度来看, 这种方式并不是很好: 如果仅仅是出于这种动机,除了查询分布之外, 我们还有很多可行的解决方案。
For example, one could argue that there are already good non-distributed solutions to improve performance.
例如, 有人反驳说,为了提高性能,已经有了非分布式解决方案。
A strong piece of wisdom crystallized over the past 30 years can be summarized thus: data workloads in production code have been historically observed to consist of either small bursty transactions that need up-to-date and consistent views of the data, but only touch very few rows (OLTP workloads), or long wide-spanning read-only transactions that touch a lot of rows, but don’t usually need a very up-to-date and consistent view of the data (analytical workloads, online or not).
对此在过去30年中对于分布式理论的认识,可以总结如下: 通常在生产代码中的数据工作负载来源是由突发的小事务与大的只读事务组成; 前者要求实时性,以及数据一致性, 这种事务只涉及非常少的行 (OLTP 工作负载),对于后者影响的数据行比较多, 但不要求数据的实时性与数据的一致性 (分析型负载, 在线或是非在线均可)。
From this observation, one can argue that OLTP workloads only need to talk to very few nodes in a distributed storage system (because primary and secondary indexes will narrow down the work to a few rows in storage), and analytical workloads can be run on materialized views that are maintained asynchronously in a separate system, optimized for fast throughput at the expense of consistency (as they do not need to update anything). In either case, distributed processing is not an obvious value-add.
基于以结论, 存在这样一个争议,OLTP 工作负载需要与分布式存储系统中极少的节点中进行处理 (因为主索引和辅助索引可以将负载缩小到存储中的少数行中), 并在独立系统上的物化视图上运行分析型的工作,但是异步同步数据,虽然对优化了大吞吐量的性能,以牺牲了一致性。 (因为它们不需要实时数据)。在这两种情况下, 显然分布式处理都不是一个直正意义上的分布式处理。
Another conventional motivation for distributed processing is a challenge to the aforementioned wisdom, acknowledging the rise of new workloads in internet services: it is now common to find OLTP workloads that need to read many rows before they update a few, and analytical workloads that benefit from reading from very up-to-date data. In both cases, distributed processing would seem to provide an effective technical solution to make these workloads faster.
分布式处理的另一个观点却提出了挑战, 认为 internet 服务中新增的负载: 现在, OLTP 工作负载通常是需要在更新少量的数据前,需要读非常多的数据,并且比分析实时数据更有效。在这两种情况下, 分布式处理似乎都提供了一种有效的技术解决方案, 以确保这些工作负载处理的更快。
However, again this motivation is weak at a high level, because since these workloads have become commonplace, we have already seen seemingly simpler and effective technology and standards emerge to address precisely these use cases.
然而, 这种出发点从严格的角度看是站不脚的, 因为由于这些工作负载已经变得司空见惯, 我们已经看到了更简单,有效的技术和标准来解决这些用例。
For transactional workloads containing large reads before an update decision is taken, the common approach is to use suitable caching.Memcached and related technology are an instance of this. For analytical processing in want of up-to-date data, an extra replication stack that maintains consistent materialized views ensures that the analytics input is both up-to-date and fast to access. Good caches and transaction/event logging to maintain materialized views externally are well-known and effective technical means to achieve this, and the corresponding technology relatively easier to provide by vendors than general-purpose distributed processing engines.
对于在传统,在更新数据前需要进行大量读的工作负载, 常用的方法是使用适当的缓存。Memcached及其相关技术是这方面的一个例子。为能对实时数据进行分析处理, 需要一个额外的复本,即维护一个同步的物化视图, 以确保数据的实效性与访问的高效性。众所周知,开发商为实现这一点,对传统分布式处理引擎来说,相对简单最有效的技术手段是使用缓存与事务日志或事件记录。
This back and forth between the expression of new computing needs and the design of specialized solutions that accelerate them is the staple diet of computer and software architects and, let’s face it, the most recurring plot device in the history of computing. After all, it “just works,“, right?
It works, but it is so complicated!
“Complicated”, here, being an euphemism for expensive to use.
新的计算需求与专业解决方案设计,加快他们之间的往返, 这是计算机和软件架构师的拿好好菜, 让我们面对它, 这是计算史上最经常出现的表演道具。毕竟, 它 "只是工作,", 对不对?
它的工作很简单,但是工作原理,却是如此复杂!
"复杂", 这里, 是一个昂贵的委婉说法。
Our motivation for distributed query processing in CockroachDB
CockroachDB 中分布式查询处理理论
This is the point in the story where we reveal the second most recurring plot device in the history of computing: rejection of complexity. This is how it goes:
在这一节中 我们揭示了计算史上第二个最经常出现的剧情装备: 拒绝复杂性。事情就是这样的:
“As a programmer, I really do not want to learn about all these specialized things. I just want to get my app out!”
“As a company owner, I do not want to have to deal with ten different technology providers to reach my performance numbers. Where’s my swiss army knife?”
"作为一个程序员, 我真的不想学习所有这些专业的东西。我只想把我的应用程序实现出来!
"作为一个公司的老板, 为达到业绩目标,我不想要处理十种不同的技术供应商, 我的瑞士军刀在哪里?“
Without a general-purpose distributed computing engine, a developer or CTO working with data must memorize a gigantic decision tree: what kind of workload is my app throwing at the database? What secondary indices do I need to make my queries fast? Which 3rd party technology do I need to cache? Which stack to use to keep track of update events in my data warehouse? Which client libraries do I use to keep a consistent view of the data, to avoid costly long-latency queries on the server?
如果没有 general-purpose 的分布式计算引擎, 对于数据处理的开发人员或 CTO 必须记住一个巨大的决策树: 我的应用程序给数据库带来什么样的工作负载?我需要哪些额外的索引才能使查询快速?我需要掌握哪些第三方技术?使用哪个堆栈来跟踪数据仓库中的更新事件?我使用哪些用户端库文件来保持数据的一致性, 以避免在服务器上进行开销大的长查询?
The cognitive overhead required to design a working internet-scale application or service has become uncomfortably staggering, and the corresponding operational costs (software + human resources) correspondingly unacceptable.
设计一个工互联网规模应用或服务,所需的开销已超乎人的想象, 相应的操作成本 (软件 + 人力资源) 也无法接受。
This is where we would like to aim distributed processing in CockroachDB: a multi-tool to perform arbitrary computations close to your data. Our goal in the longer term is to remove the burden of having to think about atomicity, consistency, isolation and durability of your arbitrarily complex operations, nor about the integration between tools from separate vendors.
我们希望在 CockroachDB 中实现分布式处理的目标: 使用multi-tool 对就近数据,实现任意计算。从长远来看, 我们的目标是消除,你所考虑的复杂杂操作的原子性、一致性、隔离性和持久性的负担, 也不要考虑独立供应商之间的集成工具。
In short, we aim to enable correctness, operational simplicity and higher developer productivity at scalable performance, above all, and competitive performance in common cases as a supplemental benefit.
This is a natural extension for building CockroachDB in the first place. After all, CockroachDB rides the NewSQL wave, fuelled by the renewed interest in SQL after a period of NoSQL craze: the software community has tried, and failed, to manage transactions and schemas client-side, and has come to acknowledge that delegating this responsibility to a database engine has both direct and indirect benefits in terms of correctness, simplicity and productivity.
简而言之, 我们的目标是,在可伸缩性能方面,实现正确性、操作简单性和开发人员高效性, 尤其是在一般性能争用情况下作为补偿。
这是建设 CockroachDB 的自然延伸。毕竟, CockroachDB 正赶上NewSQL浪潮, NoSQL在一段时间的 热潮后,由于对事务和客户端架构管理,软件社区已尝试并失败,并认识到把这些交给数据库引擎去责任处理,在正确性、简单性和生产率方面都有直接和间接的好处,于是对 SQL 又燃起新的热情。
Our distributed processing engine extends this principle, by proposing to take over some of your more complex computing needs.
This includes, to start, supporting the execution SQL queries, when maintaining a good combination of secondary indices and materialized views is either impractical or too detrimental to update performance.
It also include supporting some analytical workloads that regularly perform large aggregations where the results need up-to-date input data.
我们的分布式处理引擎通过"建议"接管一些更复杂的计算需求,来扩展这一原则。
在维护一个很好的复合二级索引和物化视图的组合时, 包括启动、支持执行 SQL 查询, 这既不实际, 也不利于更新性能。
同样,它还包括支持一些,需要定期对实时数据执行大的聚合的分析性工作负载, 。
Eventually, however, we wish to also cater to a larger class of workloads. We are very respectful of the vision that has produced Apache Samza, for example, and we encourage you to watch this presentation “Turning the Database Inside Out” by Martin Kleppmann to get an idea of the general direction where we’re aimed.
然而, 我们最终还是要迎合更多类型负载场景。Apache Samza,结了我们非常美好的愿景, 例如, 我们提议您观看来自Martin Kleppmann演示文稿 "Turning the Database Inside Out" , 以了解我们的大方向, 目标。
“Batteries included!”
So we are set on implementing a distributed processing engine in CockroachDB.
我们在 CockroachDB 中实现分布式处理引擎
It is inspired by Sawzall and at a high-level works as follows:
受Sawzall的启发,分布式处理的高明如下:
- The request coming from the client app is translated to a distributed processing plan, akin to the blueprint of a dataflow processing network.
- The node that received the query then deploys this query plan onto one or more other nodes in the cluster. This deployment consists of creating“virtual processors” (like little compute engines) on every node remotely, as well as the data flows (like little dedicated network connections) between them.
- The distributed network of processors is launched to start the computation.
- Concurrently, the node handling the query collects results from the distributed network and forwards them to the client. The processing is considered complete when all the processors stop.
- 来自客户端应用的请求被转换为分布式处理计划,类似于网络中的数据流处理。
- 节点接收到查询后,将查询计划分发到群集中的一个或多个其他节点上。这包括在每个远程节点上创建 "虚拟处理器" (如小计算引擎), 以及它们之间的数据流向 (如很少的专用网络连接)。
- 启动网络中分布式处理器,以开始计算。
- 同时,处理查询的节点,从分布式网络收集结果并将其转发给客户端。当所有处理器停止时,处理被视为完成
We highlight again that this is a general-purpose approach: dataflow processing networks are a powerful model from theoretical computer science known to handle pretty much any type of computation. Eventually, we will want our users to become able to leverage this general-purpose tool in arbitrary ways! However, in an initial phase we will restrict its exploitation to a few common SQL patterns, so that we can focus on robustness and stability.
In CockroachDB 1.0, for example, the distributed engine is leveraged automatically to handle SQL sorting, filtering, simple aggregations and some joins. In CockroachDB v1.1, it will take over more SQL aggregations and joins automatically. We will evaluate the reaction of our community to this first approach to decide where to extend the functionality further.
我们再次强调, 这是一个 general-purpose 的方法: 网络数据流处理是一个强大的模型, 从计算机科学理论知道,可以处理几乎任何类型的计算。最终, 我们将希望我们的用户能够以任意方式利用这个 general-purpose 工具!但是, 在初始阶段, 我们将限制在一些常见的 SQL 模式上, 以便我们能够集中于健壮性和稳定性。
例如, 在 CockroachDB 1.0 中, 将自动利用分布式引擎来处理 SQL 排序、筛选、简单聚合和某些联接。在 CockroachDB v1.1 中, 它将自动接管更多的 SQL 聚合和联接。我们将评估我们的社区对这第一种方法的反应, 以决定进一步扩展功能的位置。

Plans for the future in CockroachDB
Lots remain to be done
Truth be told, there are some complex theoretical questions we need to learn to answer before we can recommend distributed processing as a general tool. Some example questions we are working on:
- While data extraction processors can be intuitively launched on the nodes where the data lives, other processors like those that sort or aggregate data can be placed anywhere. How many of these should be launched? On which cluster nodes?
- How to ensure that computations stay close to the data while CockroachDB rebalances data automatically across nodes? Should virtual processors migrate together with the data ranges they are working on?
- What should users expect when a node fails while a distributed query is ongoing? Should the processing resume elsewhere and try to recover? Is partial data loss acceptable in some queries?
- How does distributed processing impact the performance of the cluster? When a node is running virtual processors on behalf of another node, how much throughput can it still provide to its own clients?
- How to ensure that a large query does not exhaust network or memory resources on many nodes? What to do if a client closes its connection during a distributed computation?
We promise to share our progress on these aspects with you in subsequent blog posts.
Summary: SQL processing in CockroachDB
You now know that CockroachDB supports two modes of execution for SQL queries: local and distributed.
In the local execution engine, data is pulled from where it is towards the one node that does the processing. This engine contains an optimization to accelerate multiple data updates, given some annotations in the SQL statements (RETURNING NOTHING), by parallelizing the updates locally, using multiple cores.
总结:cockroackDB 中的SQL处理
现在您知道 CockroachDB 支持 SQL 查询的两种执行模式: 本地和分布式。
在本地执行引擎中, 将数据直接从连接节点上获得处理。引擎包括优化过程, 以加速多个数据更新, 在 SQL 语句 (RETURNING NOTHING) 给出一些注释, 使用多内核心 在本地并行更新。
In the distributed execution engine, the processing is shipped to run close to where the data is stored, usually on multiple nodes simultaneously. Under the hood, we are building a general-purpose distributed computing engine using dataflow networks as the fundamental abstraction. We plan to expose this functionality later to all our users to cater to various distributed processing workloads, but for the time being we just use it to accelerate some SQL queries that use filtering, joins, sorts and aggregations, in particular those that you may not be able to, or do not want to, optimize manually using classical techniques (e.g. indexes or asynchronous materialized views).。
Both engines can be active simultaneously. However, because we are working hard on distributed execution, we want users to experiment with it:we thus decided to make distributed execution the default, for those queries that can be distributed. You can override this default with SET, or you can use EXPLAIN(DISTSQL) to check whether a given query can be distributed. Subsequent blog posts will detail further how exactly this is achieved.
And there is so, so, so much more we want to share about this technology. We’ll write more. Stay tuned.















 2624
2624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









