







这段时间一直在接触学习hadoop方面的知识,所以说对自然语言处理技术也是做了一些了解。网络上关于自然语言处理技术的分享文章很多,今天就给大家分享一下HanLP方面的内容。
自然语言处理技术其实是所有与自然语言的计算机处理相关联的技术的统称,自然语言处理技术应用的目的是为了能够让计算机理解和接收我们用自然语言输入的指令,实现从将我们人类的语言翻译成计算机能够理解的并且不会产生歧义的一种语言。接合目前的大数据以及人工智能,自然语言处理技术的快速发展能够很好的助力人工智能的发展。
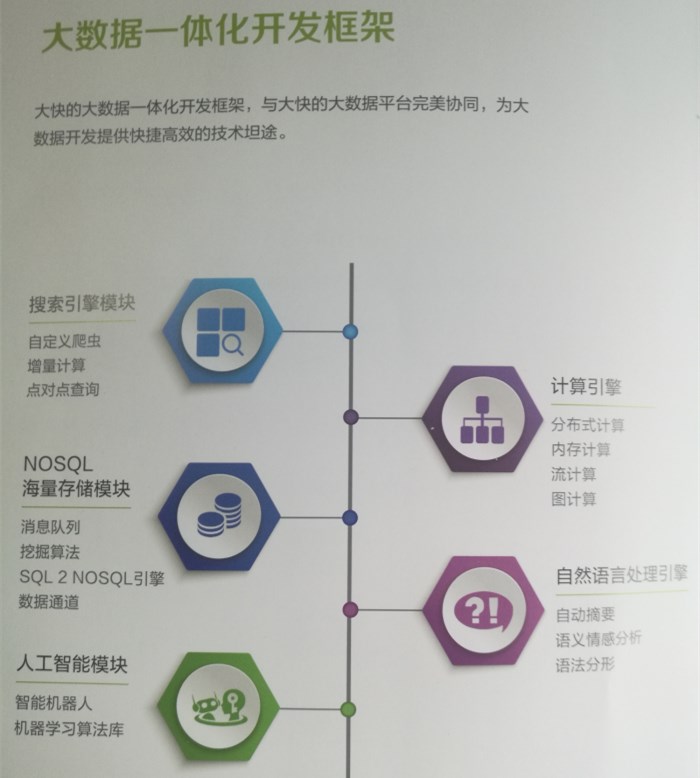
(大快DKhadoop大数据一体化框架)
这里要分享的HanLP是我在学习使用大快DKhadoop大数据一体化平台时使用到的自然语言处理技术,使用这个组建可以很高效的进行自然语言的处理工作,比如进行文章摘要,语义判别以及提高内容检索的精确度和有效性等。
本想找个通俗的案例来介绍一下HanLP,一时间也没想到什么好的案例,索性就从HanLp数据结构HE 分词简单介绍下吧。
首先我们来看了解下HanLP的数据结构:
二分tire树:Tire树是一种前缀压缩结构,可以压缩存大量字符串,并提供速度高于Map的get操作。HanLP中的trie树采用有序数组储存子节点,通过二分搜索算法检索,可以提供比TreeMap更快的查询速度。
不同于父节点储存子节点引用的普通trie树,双数组trie树将节点的从属关系转化为字符内码的加法与校验操作
对于一个接收字符c从状态s移动到t的转移,需满足条件是:
base[s] + c = t
check[t] = s比如:base[一号] + 店 = 一号店
check[一号店] = 一号
相较于trie树的前缀压缩(success表),AC自动机还实现了后缀压缩(output表)
在匹配失败时,AC自动机会跳转到最可能成功的状态(fail指针)
关于HanLP分词
1、词典分词
基于双数组trie树或ACDAT的词典最长分词(即从词典中找出所有可能的词,顺序选择最长的词语)
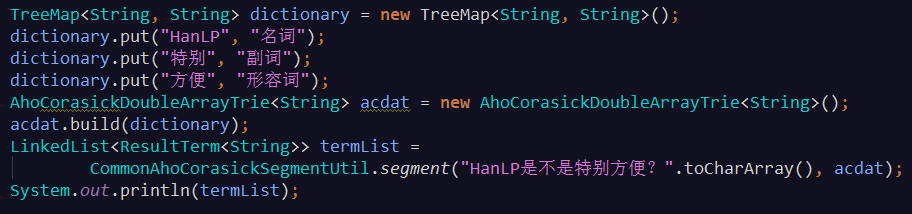
输出:[HanLP/名词, 是不是/null, 特别/副词, 方便/形容词, ?/null]
2、NGram分词
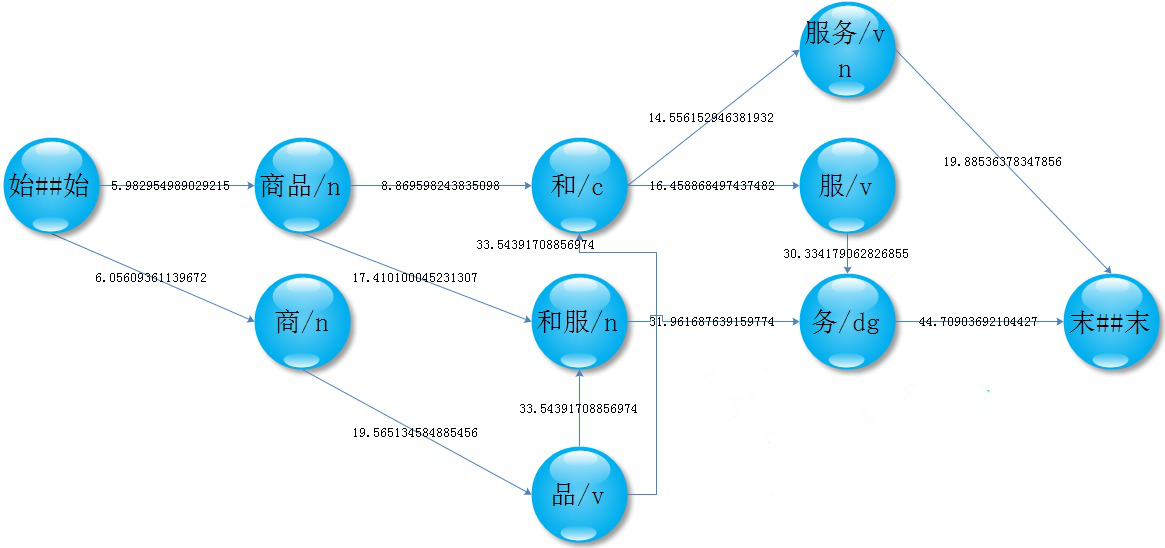
统计语料库中的BiGram,根据转移概率,选出最可能的句子,达到排除歧义的目的
3、HMM2分词
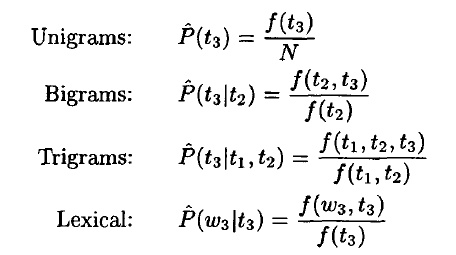
这是一种由字构词的生成式模型,由二阶隐马模型提供序列标注
被称为TnT Tagger,特点是利用低阶事件平滑高阶事件,弥补高阶模型的数据稀疏问题
4、CRF分词
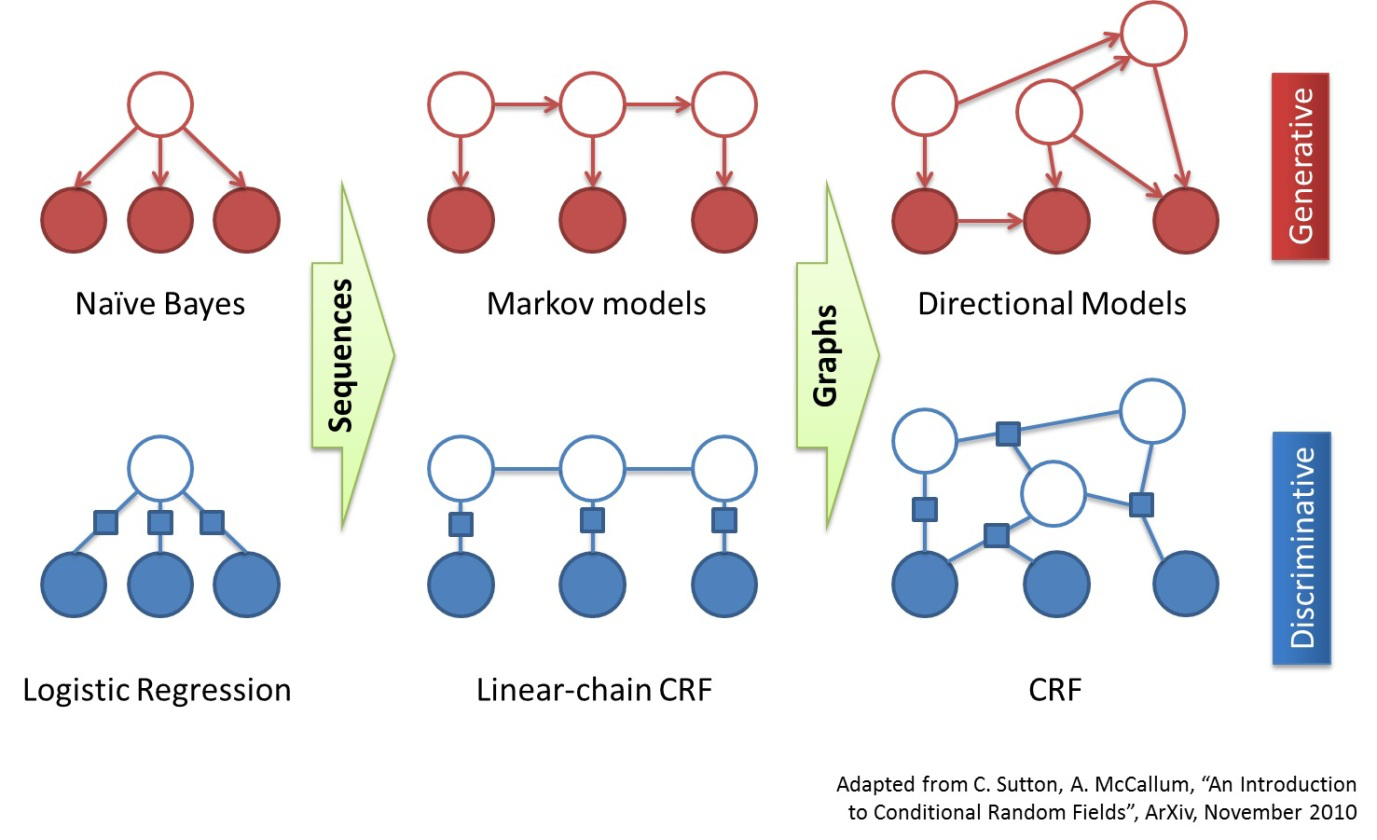
这是一种由字构词的生成式模型,由CRF提供序列标注
相较于HMM,CRF的优点是能够利用更多特征、对OOV分词效果好,缺点是占内存大、解码慢。















 2943
2943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









