







一、定义:
Base64是一种基于64个可打印字符来表示二进制数据的表示方法.以每6个位为一个单元,对应某个可打印字符。三个字节有24个位元,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。
二、使用范围:
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email,email via MIME,在XML中存储复杂数据.
三、base64 编码过程:
转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。数据不足3byte的话,于缓冲区中剩下的bit用0补足。然后,每次取出6(因为)个bit,按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出。不断进行,直到全部输入数据转换完成。
完整的base64定义可见RFC 1421和RFC 2045。编码后的数据比原始数据略长,为原来的4/3。在电子邮件中,根据RFC 822规定,每76个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的135.1%。
举例:
如下是"Man" 的base64 编码过程:
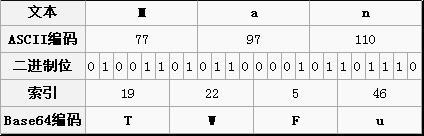
即"Man" 编码过程为 "TWFu"
其中的"索引"通过下表查询:

base64编码特殊处理:
当原数据长度不是3的整数倍时,最后会多出1个或2个字节,这时候处理方法:
1.先使用0字节值在末尾补足,使其能够被3整除,
2.然后再进行base64的编码。
3.最后在编码后的base64文本后加上一个或两个'='号,代表补足的字节数。也就是说:
a.当最后剩余一个字节时,最后一个6位的base64字节块有四位是0值,编码结果后加上两个'='号;
b.当最后剩余两个字节时,最后一个6位的base字节块有两位是0值,编码结果后加上一个'='号。
详细过程可以参考下面两个例子:
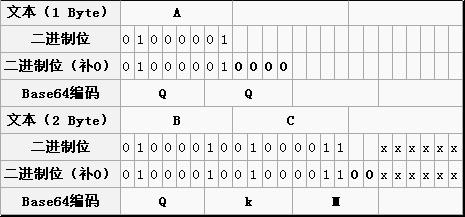
即:
"A" 编码结果为 "QQ=="
"BC" 编码结果为 "QkM="
base64编码特殊处理:
当原数据长度不是3的整数倍时,最后会多出1个或2个字节,这时候处理方法:
1.先使用0字节值在末尾补足,使其能够被3整除,
2.然后再进行base64的编码。
3.最后在编码后的base64文本后加上一个或两个'='号,代表补足的字节数。也就是说:
a.当最后剩余一个字节时,最后一个6位的base64字节块有四位是0值,编码结果后加上两个'='号;
b.当最后剩余两个字节时,最后一个6位的base字节块有两位是0值,编码结果后加上一个'='号。
详细过程可以参考下面两个例子:
即:
"A" 编码结果为 "QQ=="
"BC" 编码结果为 "QkM="
四、base64 解码过程:
解码过程是编码过程的逆过程,大致流程
1、首先确认需要解码的 base64编码字串 所有字符是否在上面索引表中,如果不是,则只解析前面满足部分,否则报错;
2、编码时通过索引值找到对应字符,解码的时候通过对应字符找到对应索引值,参考下表。
3、通过4个索引值,进行位操作组成3字节数值。最后根据具体业务,不同原始二进制流采用不同编码,再进行处理。
static const unsigned char pr2six[256] =
{
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 62, 64, 64, 64, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 64, 64, 64, 64, 64, 64,
64, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 64, 64, 64, 64, 64,
64, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64
};
例如:解码"TWFu" 过程:

解码特殊处理:
因为编码有特殊处理,所以理论上编码文本字节数是4的倍数,解码完成后,根据编码文本最后有多少个"="号,去掉对应个字节字符。
我测试的是通过从xml文件中把base64编码的图片解析出来:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iostream>
using namespace std;
static const unsigned char pr2six[256] =
{
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 62, 64, 64, 64, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 64, 64, 64, 64, 64, 64,
64, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 64, 64, 64, 64, 64,
64, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,
64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64
};
int Base64decode_len(const char *bufcoded)
{
int nbytesdecoded;
register const unsigned char *bufin;
register int nprbytes;
bufin = (const unsigned char *) bufcoded;
while (pr2six[*(bufin++)] <= 63);
nprbytes = (bufin - (const unsigned char *) bufcoded) - 1;
nbytesdecoded = ((nprbytes + 3) / 4) * 3;
return nbytesdecoded + 1;
}
/*
*base64 decode
*param:
*bufplain: IN, plain buff after decode.
*bufcoded: IN, bufer needed decode.
*return: len: len of plain buffer after decode.
*/
int Base64decode(unsigned char *bufplain, const char *bufcoded)
{
int nbytesdecoded;
register const unsigned char *bufin;
register unsigned char *bufout;
register int nprbytes;
bufin = (const unsigned char *) bufcoded;
while (pr2six[*(bufin++)] <= 63);
nprbytes = (bufin - (const unsigned char *) bufcoded) - 1;
nbytesdecoded = ((nprbytes + 3) / 4) * 3;
bufout = (unsigned char *) bufplain;
bufin = (const unsigned char *) bufcoded;
while (nprbytes > 4)
{
*(bufout++) = (unsigned char) (pr2six[*bufin] << 2 | pr2six[bufin[1]] >> 4);
*(bufout++) = (unsigned char) (pr2six[bufin[1]] << 4 | pr2six[bufin[2]] >> 2);
*(bufout++) = (unsigned char) (pr2six[bufin[2]] << 6 | pr2six[bufin[3]]);
bufin += 4;
nprbytes -= 4;
}
/* Note: (nprbytes == 1) would be an error, so just ingore that case */
if (nprbytes > 1)
{
*(bufout++) = (unsigned char) (pr2six[*bufin] << 2 | pr2six[bufin[1]] >> 4);
}
if (nprbytes > 2)
{
*(bufout++) = (unsigned char) (pr2six[bufin[1]] << 4 | pr2six[bufin[2]] >> 2);
}
if (nprbytes > 3)
{
*(bufout++) = (unsigned char) (pr2six[bufin[2]] << 6 | pr2six[bufin[3]]);
}
*(bufout++) = '\0';
nbytesdecoded -= (4 - nprbytes) & 3;
return nbytesdecoded;
}
static const char basis_64[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int Base64encode_len(int len)
{
return ((len + 2) / 3 * 4) + 1;
}
/*
*base64 decode
*param:
*string: IN, plain buff before encode.
*encoded: IN, bufer after encode.
*len: len of plain buffer before encode.
*/
int Base64encode(char *encoded, const char *string, int len)
{
int i;
char *p;
p = encoded;
for (i = 0; i < len - 2; i += 3)
{
*p++ = basis_64[(string[i] >> 2) & 0x3F];
*p++ = basis_64[((string[i] & 0x3) << 4) | ((int) (string[i + 1] & 0xF0) >> 4)];
*p++ = basis_64[((string[i + 1] & 0xF) << 2) | ((int) (string[i + 2] & 0xC0) >> 6)];
*p++ = basis_64[string[i + 2] & 0x3F];
}
if (i < len)
{
*p++ = basis_64[(string[i] >> 2) & 0x3F];
if (i == (len - 1))
{
*p++ = basis_64[((string[i] & 0x3) << 4)];
*p++ = '=';
}
else
{
*p++ = basis_64[((string[i] & 0x3) << 4) | ((int) (string[i + 1] & 0xF0) >> 4)];
*p++ = basis_64[((string[i + 1] & 0xF) << 2)];
}
*p++ = '=';
}
*p++ = '\0';
return p - encoded;
}
int main(void)
{
int encode_len = 0, decode_len = 0;
unsigned char *decode_str = NULL;
char *encode_str = NULL;
#if 0 //just test encode and decode
char src[2000] = "Man";
encode_len = Base64encode_len(strlen(src));
encode_str = (char *) malloc (encode_len);
if(NULL != decode_str)
{
cout << "encode_str malloc error !" << endl;
return -1;
}
memset(encode_str, 0, encode_len);
Base64encode(encode_str, src, strlen(src));
decode_len = Base64decode_len(encode_str));
decode_str = (unsigned char*) malloc (sizeof(unsigned char)*(decode_len);
if(NULL == decode_str)
{
free(encode_str);
encode_str = NULL;
cout << "decode_str malloc error !" << endl;
return -1;
}
memset(decode_str, 0, decode_len);
decode_len = Base64decode(decode_str, encode_str);
printf("encode_len = %d, encode_str = {%s}\n", encode_len, encode_str);
printf("decode_len = %d, decode_str = {%s}\n", decode_len, decode_str);
free(encode_str);
encode_str = NULL;
free(decode_str);
decode_str = NULL;
#else //read from file, then decode, and write to image file.
char * buffer = NULL;
FILE * pSrcFile;
FILE * pDstFile;
long lSize;
char c;
size_t total = 0, result = 0;
pSrcFile = fopen ( "icon.txt" , "rb" );
if(NULL == pSrcFile)
{
printf("file open error !\n");
return -1;
}
fseek (pSrcFile , 0 , SEEK_END);
lSize = ftell (pSrcFile);
buffer = (char*) malloc (sizeof(char)*lSize);
if (buffer == NULL)
{
fputs ("Memory error", stderr);
return -1;
}
memset(buffer, 0, sizeof(char)*lSize);
rewind (pSrcFile); //import!!!
result = fread (buffer, 1, lSize, pSrcFile);
if (result != lSize)
{
fputs ("Reading error !", stderr);
if ( ferror(pSrcFile) )
perror( "Error reading myfile" );
else if ( feof(pSrcFile))
perror( "EOF found" );
free(buffer);
buffer = NULL;
return -1;
}
decode_len = Base64decode_len(buffer);
decode_str = (unsigned char*) malloc (decode_len);
if(NULL == decode_str)
{
free(buffer);
buffer = NULL;
cout << "decode_str malloc error !" << endl;
return -1;
}
memset(decode_str, 0, decode_len);
decode_len = Base64decode(decode_str, buffer);
pDstFile = fopen ("icon.jpg", "wb");
fwrite (decode_str , sizeof(char), decode_len, pDstFile);
fclose (pDstFile);
fclose (pSrcFile);
free (buffer);
buffer = NULL;
free(decode_str);
decode_str = NULL;
#endif
return 0;
}reference:
http://zh.wikipedia.org/wiki/Base64
http://www.ruanyifeng.com/blog/2008/06/base64.html
http://www.opensource.apple.com/source/QuickTimeStreamingServer/QuickTimeStreamingServer-452/CommonUtilitiesLib/base64.c















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









