







https://gitee.com/jly521/lucene-demo.git
Lucene :开源的全文检索引擎工具包
- 优点::
- Lucene 架构图::

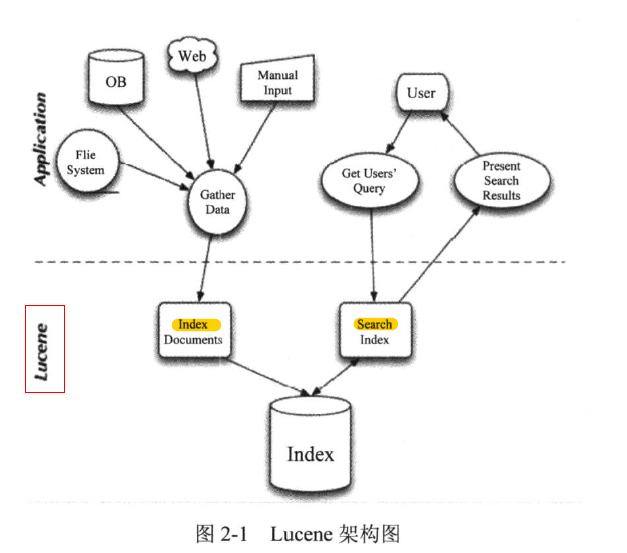
检索分4步::
- 查询分析
- 搜索通常全开放
- 纠错
- 分词技术
- 关键词检索
- 搜索排序
Luck 是Lucene、Solr、ES 索引查看的 GUI 工具
- 主要功能:

IK 分词器
- 开源的、基于java的中文分词工具包
Lucene 分词详解:
- 创建索引 和搜索的时候 要使用同一个分词器
- Lucene 自带的中文分词器IKAnalyzer 和 SmartChineseAnalyzer
IK 分词器
- 比SmartChineseAnalyzer 精准些
- 扩展停用词配置

Lucene索引详解::
- 文档是索引的基本单位,比文档更小的单位是字段
- 字段组成:name、type、value(取值)



- 倒排索引在进行排序时:
- 会访问所有文档集合中的排序字段
- 再构建一个排序好的文档集合
- 全部在内存中进行,
- 很容易内存溢出和性能缓慢
- 基于此,出现了DocValues 这一新特性
- 在构建索引时,对开启docValues的字段
- 额外构建一个已经排好序的文档到字段级别的列式存储映射
- 减轻了排序分组对内存的依赖,大大提升了该过程性能
- 在构建索引时,对开启docValues的字段
- 会访问所有文档集合中的排序字段
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//每次会清空原有索引
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
//没有则创建或有的就追加
//config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
- 索引的时候,FiledType 会设置 setIndexOptions
- 设定域的索引选项

- 全文检索,关键词高亮
- 在索引的时候,FiledType 提供方法设置 相对增量和位移信息
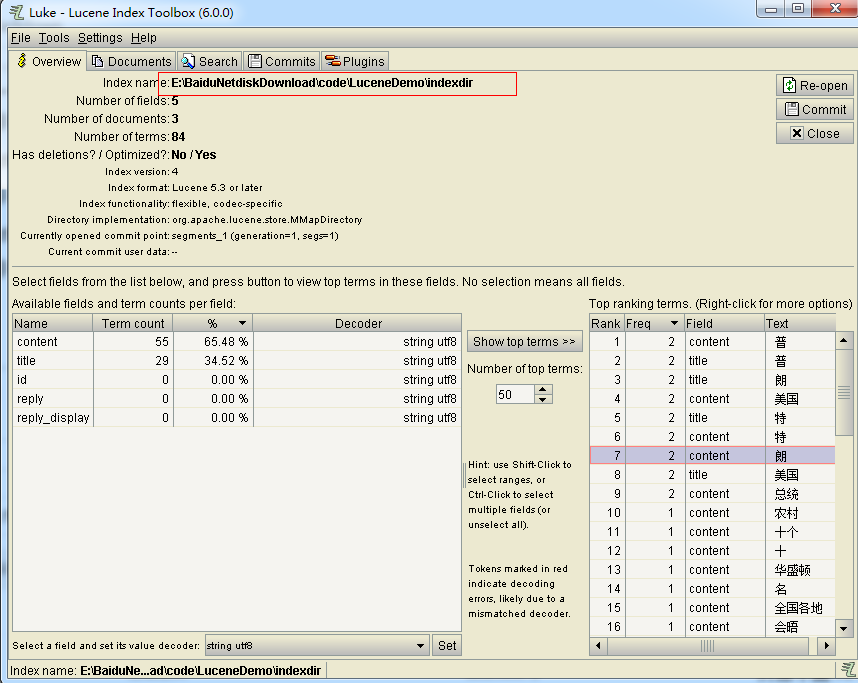
Luck 中查看索引
- 下载对应版本,是一个jar 包,
- 点击 luke.bat
Lucene 查询详解
- 搜索入门
-
QueryParser parser = new QueryParser(field, analyzer); parser.setDefaultOperator(Operator.AND); // 查询语句 Query query = parser.parse("农村学生");
-
- 多域搜索
-
String[] fields = { "title", "content" }; ... MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, analyzer); Query multiFieldQuery = parser.parse("日本");
-
- 词项搜索
-
Term term = new Term("title", "美国"); Query termQuery = new TermQuery(term);
-
- 布尔搜索
-
BooleanQuery boolQuery=new BooleanQuery.Builder().add(bc1).add(bc2).build();
- 默认是1024个 子查询,可以自定义设置
-
- 范围搜索
-
IndexSearcher searcher = new IndexSearcher(reader); Query rangeQuery=IntPoint.newRangeQuery("reply",500,1000);
-
- 前缀检索
-
Term term = new Term("title", "学"); Query prefixQuery = new PrefixQuery(term);
-
- 多关键字检索
- 支持短语查询
-
PhraseQuery.Builder builder = new PhraseQuery.Builder(); builder.add(new Term("title", "美国"),2); builder.add(new Term("title", "总统"),3); PhraseQuery phraseQuery = builder.build();
-
- 支持短语查询
- 模糊查询
- 拼错单词搜对结果
-
Term term = new Term("title", "Trmp"); FuzzyQuery fuzzyQuery = new FuzzyQuery(term);- 编辑距离算法:
- 就是从一个字符串转换成另一个字符串,需要插入、删除、替换的字母个数
- 编辑距离算法:
- 通配符搜索
-
Term term = new Term("content", "学*"); Query wildcardQuery = new WildcardQuery(term);- 可能会影响查询性能:
- 通配符前较长的前缀能减少匹配次数
- 第一个字符是通配符的话,请转换成枚举个数的第一个字符的查询
- 可能会影响查询性能:
-
Lucene 高亮
- 参见代码
Lucene 新闻高频词提取
- IndexDocs
- GetTopTerms














 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









