







集成学习是构建一组基学习器,并将它们综合作为最终的模型,在很多集成学习模型中,对基学习器的要求很低,集成学习适用于机器学习的几乎所有的领域:
1、回归
2、分类
3、推荐
4、排序
集成学习有效的原因
多样的基学习器可以在不同的模型中取长补短
每个基学习器都犯不同的错误,综合起来犯错的可能性不大
但是想同的多个基学习器不会带来任何提升
集成学习示例: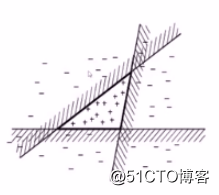
例如在上图中每个线性模型都不能成功将该数据集分类
但是三个线性模型的简单综合即可将数据集成功分类,每个模型犯不同的错,但是在综合时能够取长补短,使得综合后的模型性能更好。
那么如何构建不同的基学习器?如何将基学习器综合起来?
如何构建不同的学习器
1、采用不同的学习算法
2、采用相同的学习算法,但是使用不同的参数
3、采用不同的数据集,其中采用不同的样本子集,在每个数据集中使用不同的特征
如何综合不同的基学习器
1、投票法
每个基学习器具有相同的权重
2、有权重的投票
可用不同的方法来确定权重
3、训练一个新模型来确定如何综合
stacking
我们一般偏好简单的模型(线性回归)
主要的集成学习模式有以下几种
1、bagging random forest(随机森林)
2、boosting
adaboost
GBDT
3、stacking
bagging
在集成算法中,bagging 方法会在原始训练集的随机子集上构建一类黑盒估计器的多个实例,然后把这些估计器的预测结果结合起来形成最终的预测结果。 该方法通过在构建模型的过程中引入随机性,来减少基估计器的方差(例如,决策树)。 在多数情况下,bagging 方法提供了一种非常简单的方式来对单一模型进行改进,而无需修改背后的算法。 因为 bagging 方法可以减小过拟合,所以通常在强分类器和复杂模型上使用时表现的很好(例如,完全决策树,fully developed decision trees),相比之下 boosting 方法则在弱模型上表现更好(例如,浅层决策树,shallow decision trees)。
bagging 方法有很多种,其主要区别在于随机抽取训练子集的方法不同:
如果抽取的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









