







最近在学python,于是试试爬取osc热门动弹。程序爬取热门动弹及所有动弹评论。
from bs4 import BeautifulSoup
import urllib
import xlwt
import pymysql.cursors
# pls call me scott
# 亦真亦假、亦长亦短、亦喜亦悲
# 数据库连接
def getConnection():
con = pymysql.connect(host='localhost',
user='******',
password='******',
db='pythondb',
charset='utf-8',
cursorclass=pymysql.cursors.DictCursor)
return con
# 数据持久化 TODO
def insertData():
try:
con = getConnection();
with con.cursor() as cursor:
sql = 'insert into test(id,name)'
cursor.execute(sql,(1,'scott'))
cursor.close()
con.commit()
finally:
con.close()
# 获取html
def getHtml(url):
html=""
try:
data=None
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36'}
req=urllib.request.Request(url,data,headers)
response = urllib.request.urlopen(req)
html = response.read()
html = html.decode('UTF-8')
#print(html)
except Exception as e:
print(e)
return html
#获取相关内容
def getData(baseurl):
datalist=[]
html=getHtml(baseurl)
soup = BeautifulSoup(html)
hottweet = soup.find('article',{'class':'hot-tweet'})
for tweet in hottweet.find_all('div',{'class':'box tweetitem'}):
data=[]
name = tweet.find('a',{'class':'ti-uname'}).getText()
content = tweet.find('span',{'class':'inner-content'}).getText()
href = tweet.find('a',{'title':'查看详情'}).get('href')
detailhtml = getHtml(href)
detailsoup = BeautifulSoup(detailhtml)
reply_list = detailsoup.find('div',{'class':'tweet_reply_list'})
data.append(name)
data.append(content)
# 第一页所有评论
for reply in reply_list.find_all('div',{'class':'box tweet-reply-item'}):
ruser = reply.find('a',{'class':'replay-user'}).getText()
rcontent = reply.find('div',{'class':'sc sc-text wrap replay-content'}).getText()
#print(ruser+":"+rcontent)
data.append(ruser)
data.append(rcontent)
# 是否有下一页
pageli = reply_list.find_all('li')
if(pageli!=None):
for li in pageli:
# print(li.getText())
if(li.getText().isdigit()):
page = getHtml(href+'?p='+str(int(li.getText())+1))
pagesoup = BeautifulSoup(page)
reply_list = pagesoup.find('div',{'class':'tweet_reply_list'})
for reply in reply_list.find_all('div',{'class':'box tweet-reply-item'}):
ruser = reply.find('a',{'class':'replay-user'}).getText()
rcontent = reply.find('div',{'class':'sc sc-text wrap replay-content'}).getText()
#print(ruser+":"+rcontent)
data.append(ruser)
data.append(rcontent)
datalist.append(data)
return datalist
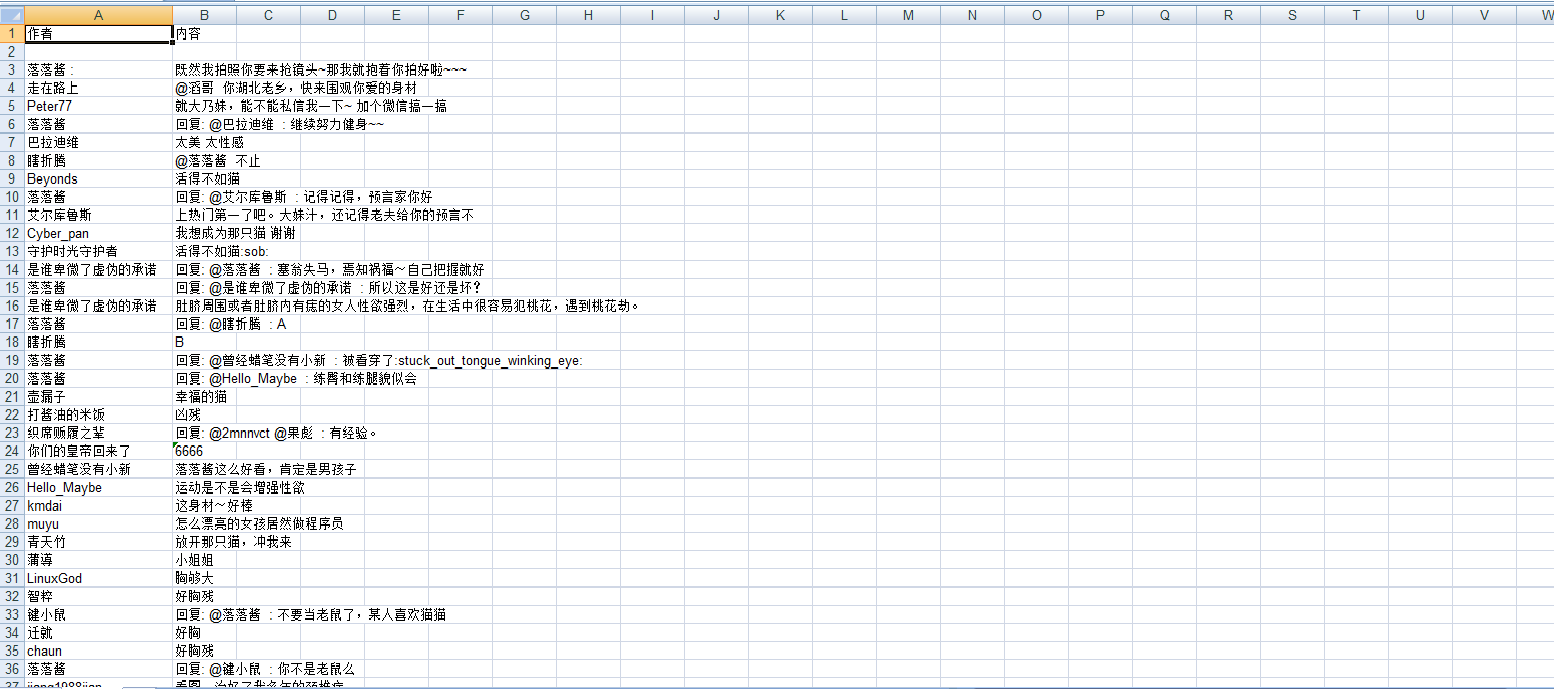
#将数据写入excel中 datalist 数据格式 list[list1,list2...] listX[0]是动弹作者,listX[1]是动弹内容,后面的listX[X]则是评论作者,listX+1[X+1]则是评论内容
def saveData(datalist,path):
if len(datalist)!=0:
book=xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet=book.add_sheet('top10',cell_overwrite_ok=True)
col=('作者','内容')
index = 1
for i in range(0,2):
sheet.write(0,i,col[i])#列名
for i in range(0,len(datalist)):#10
data=datalist[i]
for j in range(0,len(data)):
if(j%2==0):
columnIndex=0
index+=1
else:
columnIndex=1
sheet.write(index,columnIndex,data[j])#数据
index+=5
book.save(path)#保存
def main():
baseurl='https://www.oschina.net/tweets'
datalist=getData(baseurl)
path=u'TOP10动弹.xls'
saveData(datalist,path)
# insertData(datalist)
main()















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









