







1、行存储
定义:关系模型使用记录(行或者元组)进行存储,记录存储在表中,表由架构界定。表中的每个列都有名称和类型,表中的所有记录都要符合表的定义。SQL是专门的查询语言,提供相应的语法查找符合条件的记录,如表联接(Join)。表联接可以基于表之间的关系在多表之间查询记录。
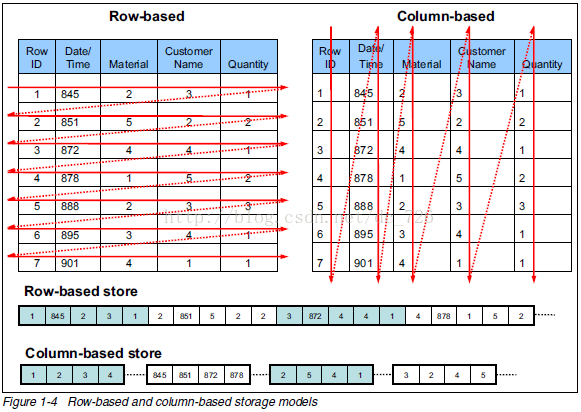
存储格式:行式数据库把一行中的数据值串在一起存储起来(行头信息,列长,列值),然后再存储下一行的数据,以此类推。
特点:据以行相关的存储体系架构进行空间分配,主要适合与小批量的数据处理,常用于联机事务型数据处理。不能满足后面三个需求:对数据库高并发读写要求,对海量数据的高效率存储和访问需求,对数据库高可扩展性和高可用性。 一句话不适合分布式、高并发和海量。
2、列存储
定义:什么是列式数据库?列式数据库是以列相关存储架构进行数据存储的数据库。列式存储以流的方式在列中存储所有的数据,主要适合与批量数据处理和即席查询。
存储格式 :列式数据库把一列中的数据值串在一起存储起来,然后再存储下一列的数据,以此类推。
特点:包括查询快,由于查询需要读取的blocks少;数据压缩比高,正因为同一类型的列存储在一起。Load快。 简化数据建模的复杂性。但是插入更新慢,不太适合数据老是变化,它是按列存储的。这时候你就知道它适做DSS(决策支持系统),BI的优秀选择,数据集市,数据仓库,它不适合OLTP。
列式存储: 每一列单独存放,数据即是索引。
行式与列式比较
Ø Row-based storage stores atable in a sequence of rows.
Ø Column-based storage storesa table in a sequence of columns.

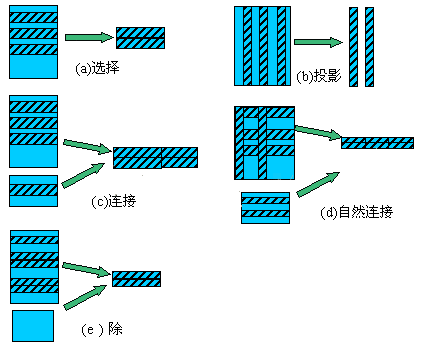
关系型数据库理论- 选择(Selection)和投影(Projection)
Speedup和Scaleup
Speedup指用两倍的硬件换来一半的执行时间。Scaleup指两倍的硬件换来同等时间内执行两倍的任务。但往往事情不是那么简单,两倍的硬件也会带来其他问题:更多CPU带来的长启动时间和通信开销,以及并行计算带来的数据倾斜问题。

多处理器架构
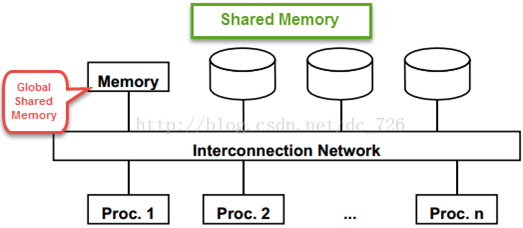
共享内存:任意CPU都能访问任意的内存(全局共享)和磁盘。优点是简单,缺点是扩展性差,可用性低。
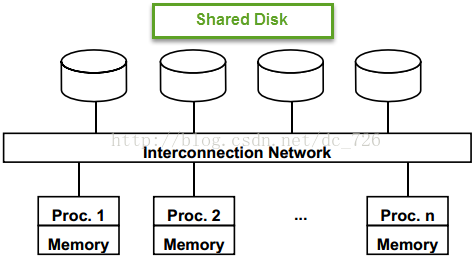
共享磁盘:任意CPU都能访问任何的磁盘,但是只能访问自己的主存。优点是可用性和扩展性比较好,缺点是实现复杂以及潜在的性能问题。
不共享:任意CPU都只能访问自己的主存和磁盘。优点也是扩展性和可用性,缺点是实现复杂以及复杂均衡。
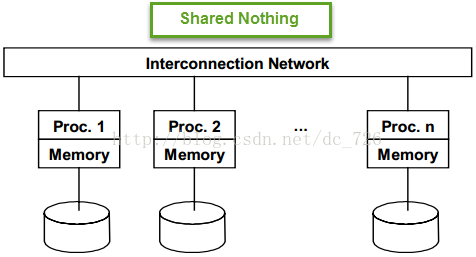
混合型:系统整体上是shared nothing架构,但结点内部可能是其他架构。这样就混合了多种架构的优点。
数据分区
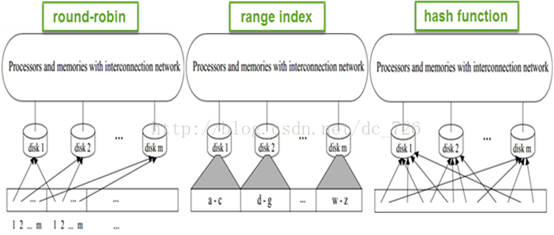
数据分区的目的就是:让数据库能够并行地读写数据,最大程度地挖掘I/O的潜力。常见的分区算法有:round-robin、范围索引、哈希。
3、键值存储
即Key-Value存储,简称KV存储。它是NoSQL存储的一种方式。它的数据按照键值对的形式进行组织,索引和存储。KV存储非常适合不涉及过多数据关系业务关系的业务数据,同时能有效减少读写磁盘的次数,比SQL数据库存储拥有更好的读写性能。
典型例子 Sorted String Table即SSTable。其实STL 库中map和hash_map, Java中hash_table, hash_map就是键值存储。 但是他们值只支持内存操作,而且map的查询效率太低,关键是他们只是简单的数据结构,不能实现较大规模存储和分布式,而且数据的修改效率比较低。 而 SSTalbe就解决了这些问题。
键值存储实际是分布式表格系统的一种。
4、文档存储
文档存储支持对结构化数据的访问,不同于关系模型的是,文档存储没有强制的架构。
事实上,文档存储以封包键值对的方式进行存储。在这种情况下,应用对要检索的封包采取一些约定,或者利用存储引擎的能力将不同的文档划分成不同的集合,以管理数据。
与关系模型不同的是,文档存储模型支持嵌套结构。例如,文档存储模型支持XML和JSON文档,字段的“值”又可以嵌套存储其它文档。文档存储模型也支持数组和列值键。
与键值存储不同的是,文档存储关心文档的内部结构。这使得存储引擎可以直接支持二级索引,从而允许对任意字段进行高效查询。支持文档嵌套存储的能力,使得查询语言具有搜索嵌套对象的能力,XQuery就是一个例子。MongoDB通过支持在查询中指定JSON字段路径实现类似的功能。
对SQL 和ACID 支持的比较全面的数据库了。不过,比较多的还是介绍日志的采集和存储,小文件的分布式存储,类似互联网微博应用的数据存储等方面的内容。
5、图形数据
图形数据库存储顶点和边的信息,有的支持添加注释。
图形数据库可用于对事物建模,如社交图谱、真实世界的各种对象。IMDB(Internet MovieDatabase)站点的内容就组成了一幅复杂的图像,演员与电影彼此交织在一起。
图形数据库的查询语言一般用于查找图形中断点的路径,或端点之间路径的属性。Neo4j是一个典型的图形数据库。















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









