







一、概述
Swarm 是使用 SwarmKit 构建的 Docker 引擎内置(原生)的集群管理和编排工具。Swarm 集群由 管理节点 和 工作节点 组成。
本篇使用的环境包括3个节点,一个作为Swarm的manager节点,两个为worker节点,机器名和IP地址如下:
- wuweixiang: 139.9.44.81 (Swarm manager)
- VM_0_14_centos: 188.131.152.100 (Swarm worker)
- VM_38_55_centos: 140.143.206.99 (Swarm worker)
二、初始化Swarm集群
# 初始化一个集群 [root@wuweixiang ~]# docker swarm init --help Usage: docker swarm init [OPTIONS] Initialize a swarm Options: --advertise-addr string Advertised address (format: <ip|interface>[:port]) --autolock Enable manager autolocking (requiring an unlock key to start a stopped manager) --availability string Availability of the node ("active"|"pause"|"drain") (default "active") --cert-expiry duration Validity period for node certificates (ns|us|ms|s|m|h) (default 2160h0m0s) --data-path-addr string Address or interface to use for data path traffic (format: <ip|interface>) --default-addr-pool ipNetSlice default address pool in CIDR format (default []) --default-addr-pool-mask-length uint32 default address pool subnet mask length (default 24) --dispatcher-heartbeat duration Dispatcher heartbeat period (ns|us|ms|s|m|h) (default 5s) --external-ca external-ca Specifications of one or more certificate signing endpoints --force-new-cluster Force create a new cluster from current state --listen-addr node-addr Listen address (format: <ip|interface>[:port]) (default 0.0.0.0:2377) --max-snapshots uint Number of additional Raft snapshots to retain --snapshot-interval uint Number of log entries between Raft snapshots (default 10000) --task-history-limit int Task history retention limit (default 5) # Master - > 初始化一个集群, 创建swarm管理节点 [root@wuweixiang ~]# docker swarm init --advertise-addr 139.9.44.81 Swarm initialized: current node (xvmqc3op6e9lkao153u410m8x) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-255nm4msqjuij5q0phuhy25ptz4m1qw7rfdbhwv4rbjl0ftg4j-0moyoy6mn3i4ewpaqh5wqrdq4 139.9.44.81:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions. # Master - > 查看Worker节点连接所需要的Token信息 [root@wuweixiang ~]# docker swarm join-token worker To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-255nm4msqjuij5q0phuhy25ptz4m1qw7rfdbhwv4rbjl0ftg4j-0moyoy6mn3i4ewpaqh5wqrdq4 139.9.44.81:2377 # 使用docker info查看集群中的相关信息 [root@wuweixiang ~]# docker info …… Swarm: active NodeID: xvmqc3op6e9lkao153u410m8x Is Manager: true ClusterID: oucnrveg187xttygnm6fak4di Managers: 1 Nodes: 3 Default Address Pool: 10.0.0.0/8 SubnetSize: 24 Orchestration: Task History Retention Limit: 5 …… # Master - > docker node ls 查看集群 [root@wuweixiang ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION i3ma0jg3a0dzqezh1tjbwyxxk VM_0_14_centos Ready Active 18.09.0 nglbqs945y4p7t57yvnhiryze VM_38_55_centos Ready Active 18.09.0 xvmqc3op6e9lkao153u410m8x * wuweixiang Ready Active Leader 18.09.0
node ID旁边那个*号表示现在连接到这个节点上。
三、将Worker节点加入Swarm集群
[root@VM_0_14_centos ~]# docker swarm join --token SWMTKN-1-255nm4msqjuij5q0phuhy25ptz4m1qw7rfdbhwv4rbjl0ftg4j-0moyoy6mn3i4ewpaqh5wqrdq4 139.9.44.81:2377 This node joined a swarm as a worker.
四、管理Swarm集群
1、删除Swarm集群节点
[root@VM_0_14_centos ~]# docker swarm leave Node left the swarm.
[root@wuweixiang ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION i3ma0jg3a0dzqezh1tjbwyxxk VM_0_14_centos Down Active 18.09.0 nglbqs945y4p7t57yvnhiryze VM_38_55_centos Ready Active 18.09.0 xvmqc3op6e9lkao153u410m8x * wuweixiang Ready Active Leader 18.09.0 [root@wuweixiang ~]# docker node rm --force i3 i3 [root@wuweixiang ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION nglbqs945y4p7t57yvnhiryze VM_38_55_centos Ready Active 18.09.0 xvmqc3op6e9lkao153u410m8x * wuweixiang Ready Active Leader 18.09.0
2、更新Swarm集群节点
[root@wuweixiang ~]# docker swarm update
Usage: docker swarm update [OPTIONS]
Update the swarm
Options:
--autolock Change manager autolocking setting (true|false)
--cert-expiry duration Validity period for node certificates (ns|us|ms|s|m|h) (default 2160h0m0s)
--dispatcher-heartbeat duration Dispatcher heartbeat period (ns|us|ms|s|m|h) (default 5s)
--external-ca external-ca Specifications of one or more certificate signing endpoints
--max-snapshots uint Number of additional Raft snapshots to retain
--snapshot-interval uint Number of log entries between Raft snapshots (default 10000)
--task-history-limit int Task history retention limit (default 5)
五、Swarm集群的服务部署实践
1 在Swarm中部署服务
在wuweixiang也就是manager节点上运行如下命令来部署服务:
[root@wuweixiang ~]# docker service create --replicas 1 --name helloworld alpine ping docker.com
参数说明:
--replicas参数指定启动的服务由几个实例组成;--name参数指定启动服务的服务名;alpine ping docker.com指定了使用alpine镜像创建服务,实例启动时运行ping docker.com命令。
这与docker run命令是一样的。
使用docker service ls查看正在运行服务的列表:
[root@wuweixiang ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS iswutf06uqkm helloworld replicated 1/1 alpine:latest
2 查询Swarm中服务的信息
在部署了服务之后,登录到manager节点,运行下面的命令来显示服务的信息。参数--pretty使命令输出格式化为可读的格式,不加--pretty可以输出更详细的信息:
[root@wuweixiang ~]# docker service inspect --pretty helloworld ID: yzq3e2aqp81d2a63nxizaadh4 Name: helloworld Service Mode: Replicated Replicas: 1 Placement: UpdateConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Update order: stop-first RollbackConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Rollback order: stop-first ContainerSpec: Image: alpine:latest@sha256:621c2f39f8133acb8e64023a94dbdf0d5ca81896102b9e57c0dc184cadaf5528 Args: ping docker.com Init: false Resources: Endpoint Mode: vip
使用命令docker service ps <SERVICE-ID>可以查询到哪个节点正在运行该服务:
[root@wuweixiang ~]# docker service ps yz ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS qu7wc6cv3rlj helloworld.1 alpine:latest wuweixiang Running Running 56 seconds ago
3 在Swarm中动态扩展服务
登录到manager节点,使用命令docker service scale <SERVICE-ID>=<NUMBER-OF-TASKS>来将服务扩展到指定的实例数:
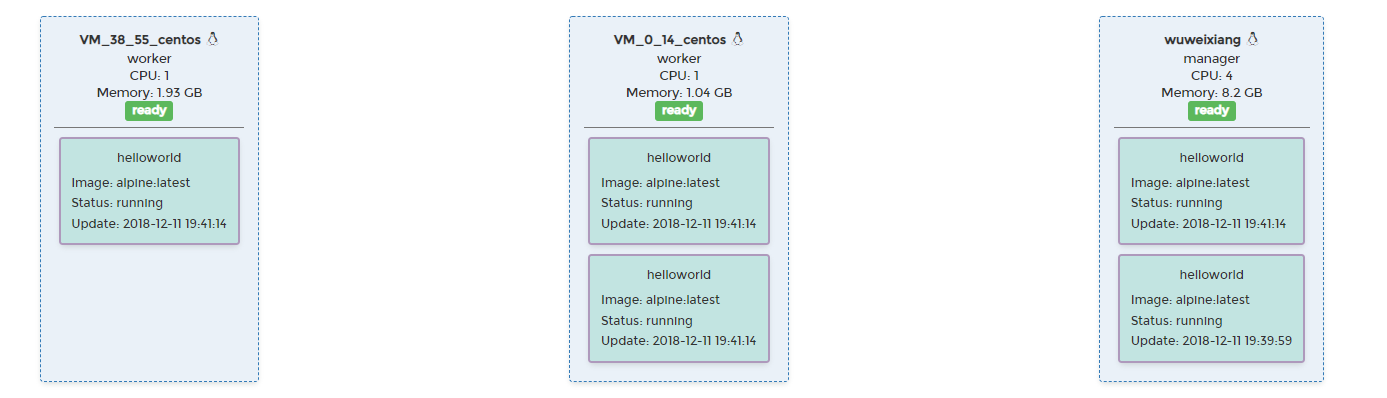
[root@wuweixiang ~]# docker service scale helloworld=5 helloworld scaled to 5 overall progress: 5 out of 5 tasks 1/5: running [==================================================>] 2/5: running [==================================================>] 3/5: running [==================================================>] 4/5: running [==================================================>] 5/5: running [==================================================>] verify: Service converged [root@wuweixiang ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS yzq3e2aqp81d helloworld replicated 5/5 alpine:latest [root@wuweixiang ~]# docker service ps yz ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS qu7wc6cv3rlj helloworld.1 alpine:latest wuweixiang Running Running about a minute ago lry00fiqgmw3 helloworld.2 alpine:latest VM_0_14_centos Running Running 19 seconds ago w4wvcghx57cn helloworld.3 alpine:latest VM_0_14_centos Running Running 19 seconds ago gi84iozh8vxh helloworld.4 alpine:latest wuweixiang Running Running 19 seconds ago kcf09wi7vzj2 helloworld.5 alpine:latest VM_38_55_centos Running Running 19 seconds ago
可见Swarm集群创建了4个新的task来将整个服务的实例数扩展到5个。这些服务分布在不同的Swarm节点上。
4 删除Swarm集群中的服务
在manager节点上运行docker service rm helloworld便可以将服务删除。删除服务时,会将服务在各个节点上创建的容器一同删除,而并不是将容器停止。
此外Swarm模式还提供了服务的滚动升级,将某个worker置为维护模式,及路由网等功能。在Docker将Swarm集成进Docker引擎后,可以使用原生的Docker CLI对容器集群进行各种操作,使集群的部署更加方便、快捷。
# ... and remove 删除服务
docker service rm nginx
# but usually it's better to scale down 但是更好的办法是缩容,而不是直接删除服务
docker service scale nginx=0
5 更新Swarm集群中的服务版本
在前面的步骤中, 我们扩展了一个服务的多个实例, 如上所示, 我们扩展了基于Tomcat Server 8.5.8的Docker镜像。 假如,现在我们需要使用Tomcat Server 8.6.0版本做为Docker容器版本来替换原有的Tomcat Server 8.5.8版本。
[root@centos7-Master ~]# docker service update --image tomcat:8.6.0 tomcat-service
tomcat-service
服务版本更新计划将按以下步骤执行:
重新启动一个暂停更新的服务, 可以使用docker service update <SERVICE-ID>命令, 例如:
[root@centos7-Master ~]# docker service update tomcat-service
- 在Swarm集群中的Manager节点上执行操作,用于完成服务版本的更新。
- 停止第一个任务
- 计划对已停止任务的更新
- 启动已更新任务的容器
- 如果任务更新返回“RUNNING”状态,等待指定的延迟时间后,停止下一个任务
- 如果在任务更新时,任务返回“FAILED”状态,将会暂停更新。
- 查看服务版本更新结果
[root@centos7-Master ~]# docker service ps tomcat-service6 停用Swarm集群中的服务节点
如果我们想要停止Swarm集群中某个服务的Worker节点, 我们可以使用docker node update --availability drain <Node-ID>来停止Worker节点上的服务。
[root@wuweixiang ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION v4zv3v207si2pvofuk9ma032h VM_0_14_centos Ready Active 18.09.0 nglbqs945y4p7t57yvnhiryze VM_38_55_centos Ready Active 18.09.0 xvmqc3op6e9lkao153u410m8x * wuweixiang Ready Active Leader 18.09.0 [root@wuweixiang ~]# docker node update --availability drain v4 v4 [root@wuweixiang ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION v4zv3v207si2pvofuk9ma032h VM_0_14_centos Ready Drain 18.09.0 nglbqs945y4p7t57yvnhiryze VM_38_55_centos Ready Active 18.09.0 xvmqc3op6e9lkao153u410m8x * wuweixiang Ready Active Leader 18.09.0
在停止Worker节点上的服务后, 我们可以通过docker node inspect --pretty <Node-ID>查看节点状态。
[root@wuweixiang ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
i3ma0jg3a0dzqezh1tjbwyxxk VM_0_14_centos Ready Drain 18.09.0
xvmqc3op6e9lkao153u410m8x * wuweixiang Ready Active Leader 18.09.0
[root@wuweixiang ~]# docker node inspect --pretty v4
ID: v4zv3v207si2pvofuk9ma032h
Hostname: VM_0_14_centos
Joined at: 2018-12-11 11:37:15.973392656 +0000 utc
Status:
State: Ready
Availability: Drain
Address: 188.131.152.100
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 992.7MiB
Plugins:
Log: awslogs, fluentd, gcplogs, gelf, journald, json-file, local, logentries, splunk, syslog
Network: bridge, host, macvlan, null, overlay
Volume: local
Engine Version: 18.09.0
TLS Info:
TrustRoot:
-----BEGIN CERTIFICATE-----
MIIBajCCARCgAwIBAgIUaoragJW4UwMO+DCs1zkxpt1xPdswCgYIKoZIzj0EAwIw
EzERMA8GA1UEAxMIc3dhcm0tY2EwHhcNMTgxMjExMDc0MTAwWhcNMzgxMjA2MDc0
MTAwWjATMREwDwYDVQQDEwhzd2FybS1jYTBZMBMGByqGSM49AgEGCCqGSM49AwEH
A0IABFLvlDlCVuPyAbqMCKIl4MAdVfvgYLvoAIbkzX0EPPdlB5jiVR2oI6xSmWHg
Yt5mivr+b0eRVg17RneCz/zJjgWjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB
Af8EBTADAQH/MB0GA1UdDgQWBBSoVH4AOp4ATVDNzsnA/8aP/Qx2aDAKBggqhkjO
PQQDAgNIADBFAiARza3fA5h4sFguVfiFEE4JYputzRyZ3CdvfUoR2DNK3QIhAM6j
5WCUR5syguW3xhFRpuQqgztsekBAjoUakQD7mSu/
-----END CERTIFICATE-----
Issuer Subject: MBMxETAPBgNVBAMTCHN3YXJtLWNh
Issuer Public Key: MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEUu+UOUJW4/IBuowIoiXgwB1V++Bgu+gAhuTNfQQ892UHmOJVHagjrFKZYeBi3maK+v5vR5FWDXtGd4LP/MmOBQ==
使用docker service ps tomcat-service查看当前helloworld启动的集群信息。
[root@wuweixiang ~]# docker service ps helloworld ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS qu7wc6cv3rlj helloworld.1 alpine:latest wuweixiang Running Running 4 minutes ago kmbmtq98pqxm helloworld.2 alpine:latest VM_38_55_centos Running Running about a minute ago lry00fiqgmw3 \_ helloworld.2 alpine:latest VM_0_14_centos Shutdown Shutdown about a minute ago 49ip45gz71q3 helloworld.3 alpine:latest VM_38_55_centos Running Running about a minute ago w4wvcghx57cn \_ helloworld.3 alpine:latest VM_0_14_centos Shutdown Shutdown about a minute ago gi84iozh8vxh helloworld.4 alpine:latest wuweixiang Running Running 3 minutes ago kcf09wi7vzj2 helloworld.5 alpine:latest VM_38_55_centos Running Running 3 minutes ago

如果我们需要重新启用VM_0_14_centos 的Swarm集群服务, 我们可以通过docker node update --availability active <NODE-ID>来实现对服务节点的启用。
[root@wuweixiang ~]# docker node update --availability active v4 v4 [root@wuweixiang ~]# docker node inspect --pretty v4 ID: v4zv3v207si2pvofuk9ma032h Hostname: VM_0_14_centos Joined at: 2018-12-11 11:37:15.973392656 +0000 utc Status: State: Ready Availability: Active Address: 188.131.152.100 Platform: Operating System: linux Architecture: x86_64 Resources: CPUs: 1 Memory: 992.7MiB Plugins: Log: awslogs, fluentd, gcplogs, gelf, journald, json-file, local, logentries, splunk, syslog Network: bridge, host, macvlan, null, overlay Volume: local Engine Version: 18.09.0 TLS Info: TrustRoot: -----BEGIN CERTIFICATE----- MIIBajCCARCgAwIBAgIUaoragJW4UwMO+DCs1zkxpt1xPdswCgYIKoZIzj0EAwIw EzERMA8GA1UEAxMIc3dhcm0tY2EwHhcNMTgxMjExMDc0MTAwWhcNMzgxMjA2MDc0 MTAwWjATMREwDwYDVQQDEwhzd2FybS1jYTBZMBMGByqGSM49AgEGCCqGSM49AwEH A0IABFLvlDlCVuPyAbqMCKIl4MAdVfvgYLvoAIbkzX0EPPdlB5jiVR2oI6xSmWHg Yt5mivr+b0eRVg17RneCz/zJjgWjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB Af8EBTADAQH/MB0GA1UdDgQWBBSoVH4AOp4ATVDNzsnA/8aP/Qx2aDAKBggqhkjO PQQDAgNIADBFAiARza3fA5h4sFguVfiFEE4JYputzRyZ3CdvfUoR2DNK3QIhAM6j 5WCUR5syguW3xhFRpuQqgztsekBAjoUakQD7mSu/ -----END CERTIFICATE----- Issuer Subject: MBMxETAPBgNVBAMTCHN3YXJtLWNh Issuer Public Key: MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEUu+UOUJW4/IBuowIoiXgwB1V++Bgu+gAhuTNfQQ892UHmOJVHagjrFKZYeBi3maK+v5vR5FWDXtGd4LP/MmOBQ==
当我们设置Swarm集群的Worker节点为可用时,它便能接收新的任务:
- 当服务需要进行扩展时
- 当对服务的版本进行更新时
- 当我们对停用另外一个Swarm集群节点时
- 当任务在另外一个活动状态节点出现失败时
参考garyond:https://www.jianshu.com/p/df744c4e375e















 3733
3733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









