







数据源CDN日志。
每行日志数据格式:
| 序号 | 名称 | 说明 |
| 1 | 客户端IP |
|
| 2 | 预留字段 |
|
| 3 | 预留字段 |
|
| 4 | 请求时间 | 格式为:[dd/MMM/yyyy:HH:mm:ss Z] |
| 5 | 请求url | 格式为:”GET url HTTP/1.1” |
| 6 | Http状态码 |
|
| 7 | 下载资源大小 | 单位:B(字节) |
| 8 | 请求响应时间 | 单位:S(秒) |
| 9 | http HOST |
|
| 10 | referer |
|
| 11 | UA | 格式:-“UA” |
| 12 | http_x_forwarded_for |
|
| 13 | cache_status |
|
行日志举例:
122.96.47.110 - - [31/Mar/2015:18:39:18 +0800] "GET /proxy/url HTTP/1.1" 206 16986961 215.905 112.80.4.187 "-" "Xiaomi_2013023_TD/V1 Linux/3.4.5 Android/4.2.1 Release/03.11.2013 Browser/AppleWebKit534.30 Mobile Safari/534.30 MBBMS/2.2 System/Android 4.2.1;" "-" -
分析需求:
(1)整体请求的平均响应时间 并按照从大到小排序
(2)各个IP请求的平均响应时间 并按照从大到小排序
(3) 各个IP访问的总流量统计 并按照从大到小排序
(4) 使用iphone/android访问的用户数
(5) 不同http状态码占比情况
分析开始:
第一步加载数据源: 从hdfs文件系统读取日志文件,创建RDD对象
val rdds = sc.textFile("hdfs://132.bd:8020/spark/testdata/localhost.access.log")
第二步定义数据解析结构类: LogEntity
class LogEntity(val ip: String, val res1 : String, val res2: String,
val timestamp : String, val url: String, val http_code : Int, val size: Long, val reponse : Float,
val host : String, val refer: String, val ua : String, val forward: String, val cache_status : String) {
}
def convert2 (line : String): LogEntity = {
val regex = """([0-9|\.]+) (.|-) (.|-) (\[\w+\/\w+/\w+\:\w+\:\w+\:\w+) (\+\w+\]) (\"GET.+\") (\d+) (\d+) ([\d|\.]+) ([0-9|\.|\:]+) (\".+\") (\".+\") (\".+\") (.)""". r
try {
val regex(f1, f2, f3, f4, f5, f6, f7, f8, f9, f10, f11, f12, f13, f14) = line
val l = new LogEntity( f1, f2, f3, f4 + f5, f6, f7.toInt , f8.toLong, f9.toFloat , f10 , f11 , f12 , f13 , f14 )
return l
} catch {
case e: Exception => {
return null
}
}
}第四步定义模式匹配类 用于生成DataFrame对象Schema
case class CDNLog(ip: String, res1: String, res2 : String,
timestamp: String , url : String, http_code: Int, size: Long, reponse: Float,
host: String, refer : String, ua: String, forward: String, cache_status: String )
val sqlc = new SQLContext(sc)
import sqlc.implicits._
val logs = rdds.map(x => convert2 (x)).filter (x=>x !=null).map (l => CDNLog (l.ip , l .res1, l .res2, l .timestamp, l .url, l .http_code, l .size, l .reponse, l .host, l .refer, l .ua, l .forward, l .cache_status)).toDF ()
至此我们实现了将日志文本数据转换成DataFrame的过程,
DataFrame是SparkSQL的核心概念,基于该对象我们可以有两种方式来实现对数据的分析
(1)将DataFrame 注册为一个临时内存表,从而使用SQL语句来实现数据统计分析
(2)基于DataFrame的API操作可以实现数据的统计分析
方式一:将DataFrame对象 logs注册为临时内存表,再使用sql语句进一步分析
logs .registerTempTable( "cdnlog") //将logs对象注册为临时内存表 命名为cdnlog
val responses = sqlc.sql("select avg(reponse) as avg_response from cdnlog") //使用sql语句查询cdnlog数据表,查询平均响应时间。
打印执行结果: responses.show

方式二 使用DataFrame API实现所有需求 , 重点将详述该种方式来实现所有需求模型。
(1)整体请求的平均响应时间 并按照从大到小排序
使用DataFrame.agg函数
logs.agg(avg("reponse")).show

结果:所有用户平均访问响应时间5.68s
(2)各个IP请求的平均响应时间 并按照从大到小排序
使用DataFrame.grouBy函数
logs.groupBy("ip").agg(avg("reponse") as "avgg").sort($"avgg" desc).show
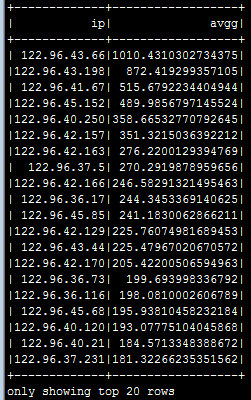
结果展示了:各个IP访问的平均像一个时间(s)并按照从大到小顺序排序
(3) 各个IP访问的总流量统计 并按照从大到小排序
使用DataFrame.grouBy函数
logs.groupBy("ip").agg(sum("size") as "total-bytes").sort($"total-bytes" desc).show

结果展示了:各个IP的访问流量总和,以及按照流量大小进行了排序。
(4) 使用iphone/android访问的用户数
使用DataFrame.filter函数
(5) 不同http状态码占比情况
依然是DataFrame.groupBy函数
logs.groupBy("http_code").count.sort($"count" desc).show

分析结果展示了:各个状态码的统计结果,以及排序。
总结: 本文主要通过一个数据例子,枚举了一些需求模型,并记录了SparkSQL实践的过程。 具体原理以及各个步骤原因没有熬述。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









