







 在高并发时代,单机已无法满足需求,分布式存储系统成为趋势,数据同步成为关键问题。本文介绍了全同步、半同步和最终一致性三种数据同步方案。全同步方案保证数据一致性和读取性能,但受最慢节点影响。半同步方案在保证基本数据可靠性的同时提升性能,允许部分节点故障。最终一致性方案牺牲一致性以提升性能,适用于对可用性要求高的场景。各种方案各有优劣,适用于不同的业务需求。
在高并发时代,单机已无法满足需求,分布式存储系统成为趋势,数据同步成为关键问题。本文介绍了全同步、半同步和最终一致性三种数据同步方案。全同步方案保证数据一致性和读取性能,但受最慢节点影响。半同步方案在保证基本数据可靠性的同时提升性能,允许部分节点故障。最终一致性方案牺牲一致性以提升性能,适用于对可用性要求高的场景。各种方案各有优劣,适用于不同的业务需求。

在海量数据,高并发时代的今天,单机由于其CPU,磁盘IO,网络带宽以及存储空间等原因,已经不再能及时响应用户的所有请求,系统都开始走向分布式,由多台机器组件成一个集群响应用户请求。具体到分布式存储系统,一个很重要的问题就在于数据的同步。本文将简要介绍当前较为流行的数据同步方案,简要分析其原理和利弊,希望能起到一个抛砖引玉的作用。
数据同步初步
数据同步的基本思想很简单,就是将单台机器上的用户数据和请求,通过复制Replicate的方式复制用户的操作命令到多台机器执行。从而应对当某台机器出现故障时,数据仍能存其他机器获取。
一种最朴素的实现方式是采用多台机器构成集群存储数据,机器按照职责分为一个主节点和多个从节点。其中主节点负责接收用户的数据请求,在本地执行用户请求的同时,将数据复制到集群中其他从节点。
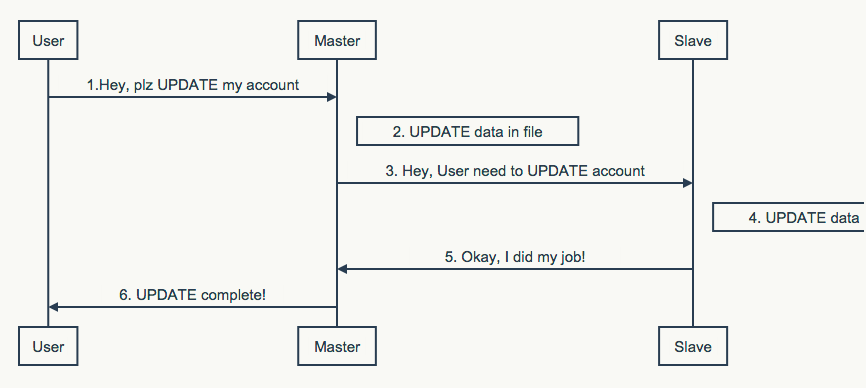
同步复制
上图中描述了同步复制的基本流程。
主节点收到用户请求后,在本地执行的同时,将请求转发到了从节点。当主节点和从节点都执行完毕后,像用户发出响应。此方法保证了主节点和从节点的数据是一致的,从而当节点出现故障时,从节点可以取而代之,而不会造成数据的损失。为了提供更高的数据可靠性,可采用1主多从的方式。
此方案被称作”全同步方案”,能提供良好的可靠性,以及数据读取性能(每个节点都能读)。同时通过调整步骤3,4,5,6的顺序,以及最大允许的主从之间的数据差额,可产生许多变形,诸如全异步方案,半异步方案等。许多熟知系统(如Mysql,Redis)提供的就是以上方案。原则上,主/从数据差额越大,性能越高,但同时数据丢失的风险越高。
此系统的最大问题在于,当系统需要保证数据一致时,写入性能取决于集群中所有节点中最慢的那个。对于将部分节点失效视为系统正常行为的分布式系统,往往是不可接受的。
为了解决该问题,大致分为三类解决方案:在全同步方案进行改进的半同步方案,利用同步协议的类Paxos方案,以及牺牲数据一致性的最终一致性方案。
半同步方案
半同步方案虽然存在多种变形,但基本思想都是结合同步方案和异步方案,使得系统在尽可能保证数据可靠性的前提下,提升系统的性能。该方案仍然采用主从架构,只是对数据同步过程进行了部分闲置。这里简要介绍Kafka采用的半同步方案。
Kafka采用的也是一主多从模式,其中只有主负责接收用户的读写请求,从节点只负责被动的接受主节点的数据。但它对主从同步进行了如下的限制:
- 从节点需定时汇报自身的同步状态到中央节点。当从节点的数据与主节点的数据差异在指定条数M以内时,被认为是同步状态(in-sync),否则认为是追赶状态(in-pace)。
- 只有处于同步状态的节点,当主节点出现故障时,才能被选为新的节点。当系统中没有处于同步状态的节点时,系统可选择停止工作&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









