







最近有一件非常难过以及无限悲伤的事情发生了,那就是Firebug停止更新和维护了!!
Firebug作为一款前端调试工具,同时也是我接触的第一款前端工具(虽然我仅使用它来分析网页结构,以便于自己爬虫项目的编写),尤其是它的简介的界面,以及firexpath插件提供的xpath和css路径查询,以便于自己在网页上定位到目的信息,我的许多爬虫练习都是这款插件陪伴我的,but it leaves me forever todays。
Firebug最初是2006年1月由Joe Hewitt编写,Joe也是Firefox创始者之一。在没有Firebug等调试工具之前,JavaScript调试非常困难,找错误有时候就跟做噩梦一般。而作为网页浏览器 Mozilla Firefox下的一款开发类插件,Firebug集中了HTML查看和编辑、JavaScript控制台、网络状况监视器等多种功能,是开发JavaScript、CSS、HTML和AJAX的有效工具。
Firebug曾是很多前端开发者的必备工具,也有开发者是因Firebug而选择使用Firefox。Firebug也被很多人借鉴,早在2011年,就有人在InfoQ上评论“开发工具部分现在长的都差不多了,看上去都像是Firebug”,而其中一个案例就是被Chrome借鉴成 DOM inspector。
而实际上,Firebug停更早已有预兆。2015年底,为了进一步提供更加强大的功能,Mazilla的工程师就在努力进行原生Firefox开发者工具(DevTools)和Firebug的整合工作。该整合项目努力把所有的Firebug特性移植到DevTools中,使得其兼容多进程,并支持远程调试。而且,项目努力保证从Firebug到DevTools的转变过程尽可能平缓和简单,不影响用户体验。从结果上来看,Firebug 3也已不再是一个单独的工具,而是DevTools之上的一个外壳。它为DevTools提供了与之前版本Firebug相同的主题。用户可通过点击Firebug Theme选项打开主题。Firebug停更,相当于去掉了DevTools的一层外壳。
如今,浏览器调试工具已有很多可选项,虽然Firebug离开了历史舞台,但它曾经的荧光陪伴了很多开发者。
如今,我使用的是Firefox Developer Edition,换成中文来说就是“火狐开发者版”,怎么说呢,个人觉得这个明显没有Firebug好用(可能是因为刚用!!),在官网下载的是英文版,如果想要更换为中文版,首先需要去http://ftp.mozilla.org/pub/firefox/releases/57.0b11/win64/xpi/zh-CN.xpi下载中文库,然后在火狐浏览器地址框输入about:config,搜索useragent.locale,将其值设置为zh-CN,重启浏览器即可,记得下载中文库的时候要注意链接上的57.0b11是浏览器的版本号,win64是系统是什么,需要根据你自己的火狐浏览器和电脑系统版本进行修改。
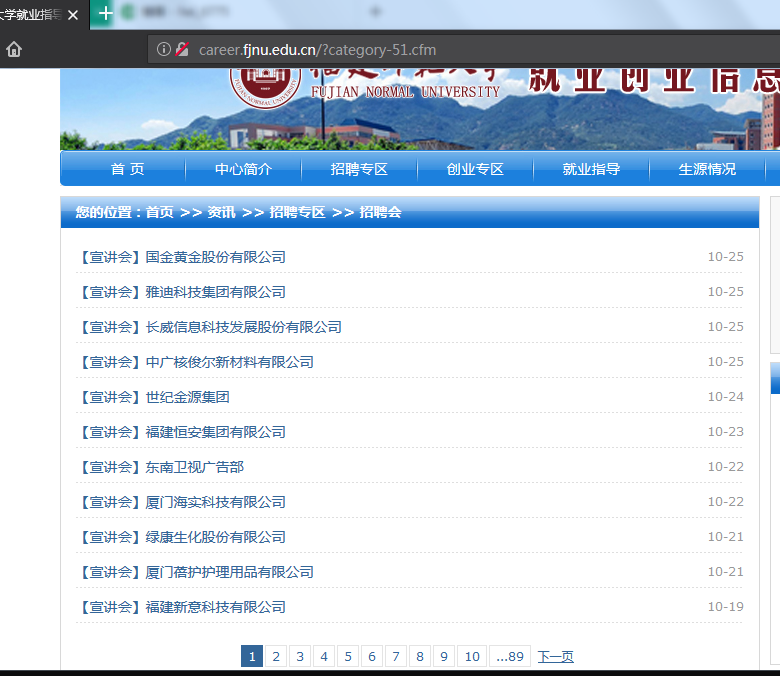
- 目的地址:http://career.fjnu.edu.cn/?category-51.cfm
- requests库
- re库
- BeautifulSoup库
- lxml库
- smtplib库
- email.mime.text.MIMEText
- python版本3.6
- win7 64位系统
- 编辑器Pycharm
访问目的地址我们可以看到如上图所示的网页信息,我们的需求就是爬取各个宣讲会的名字,时间,地点,主办方,将这些信息通过QQ的SMTP服务器将邮件发送至我的邮箱中。
首先分析目的地址的网页结构:
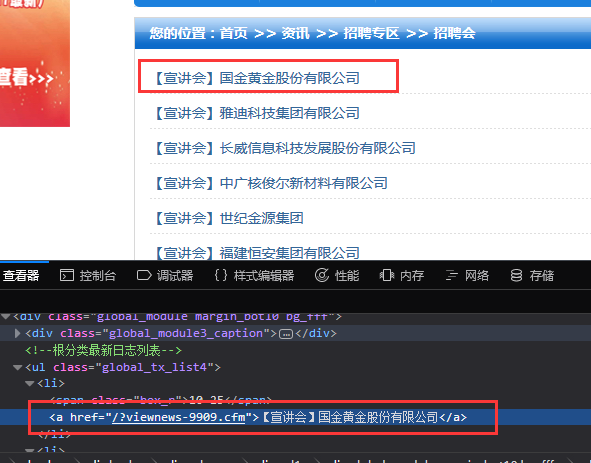
再继续看下一个的:
<ul class="global_tx_list4">
<li><span class="box_r">10-25</span><a href="/?viewnews-9909.cfm">【宣讲会】国金黄金股份有限公司</a></li>
<li><span class="box_r">10-25</span><a href="/?viewnews-9907.cfm">【宣讲会】雅迪科技集团有限公司</a></li>
<li><span class="box_r">10-25</span><a href="/?viewnews-9906.cfm">【宣讲会】长威信息科技发展股份有限公司</a></li>
<li><span class="box_r">10-25</span><a href="/?viewnews-9904.cfm">【宣讲会】中广核俊尔新材料有限公司</a></li>
<li><span class="box_r">10-24</span><a href="/?viewnews-9898.cfm">【宣讲会】世纪金源集团</a></li>
<li><span class="box_r">10-23</span><a href="/?viewnews-9877.cfm">【宣讲会】福建恒安集团有限公司</a></li>
<li><span class="box_r">10-22</span><a href="/?viewnews-9871.cfm">【宣讲会】东南卫视广告部</a></li>
<li><span class="box_r">10-22</span><a href="/?viewnews-9870.cfm">【宣讲会】厦门海实科技有限公司</a></li>
<li><span class="box_r">10-21</span><a href="/?viewnews-9865.cfm">【宣讲会】绿康生化股份有限公司</a></li>
<li><span class="box_r">10-21</span><a href="/?viewnews-9864.cfm">【宣讲会】厦门蓓护护理用品有限公司</a></li>
<li><span class="box_r">10-19</span><a href="/?viewnews-9850.cfm">【宣讲会】福建新意科技有限公司</a></li>
</ul>可以发现各个公司的各自的宣讲会信息的网页就在其中的a标签下的href下。只需要提取其href即可。
#可以使用.get('href')获取标签内的href属性的值通过上面获取的href很明显,只是正确网址的后面一段,我们需要对其进行拼接,随意打开一个宣讲会,我们就会发现其前部分网址是:http://career.fjnu.edu.cn。将前部分和后部分进行拼接,即可得到我们所需要的宣讲会的网址。然后再写一个函数,专门来处理宣讲会网址。
观察宣讲会的网页:
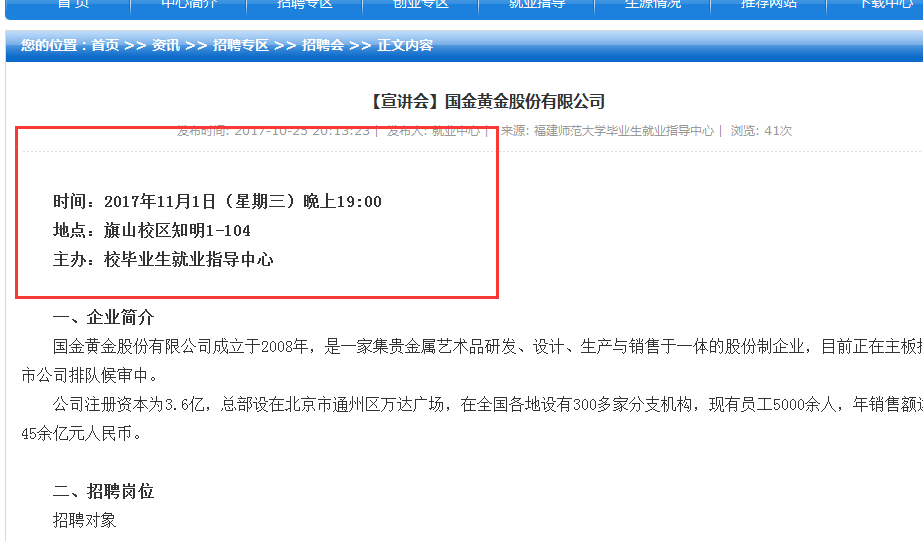
整个宣讲会的正文都在一个id为article_body的div标签下,而我们只需要前三行,所以通过split(‘\n’)进行分割,再拼凑前三行,使用strip()函数来去掉前后的空白符号。
需求分析:
- 我们需要前三行信息(因为每家公司的正文略有不同,如果做精细分的话,劳动量有点大,简单的宣讲会举行时间,举办地址,举办方,已经可以使得我记住有什么公司在什么时间开宣讲会)
- 发送邮件给目的邮箱(存成CSV??存成JSON??存成文件很明显是不行的,我要是能从电脑上打开文件,那我还不如直接登网页查看宣讲会信息。存在数据库??好像也没有任何作用。发个邮件??好像可以,直接可以通过QQ的STMP服务器发送邮件,免费还方便。)
那我们首先需要了解STMP:
1、 SMTP 服务器介绍
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。SMTP协议属于TCP/IP协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。通过SMTP协议所指定的服务器,就可以把E-mail寄到收信人的服务器上了,整个过程只要几分钟。SMTP服务器则是遵循SMTP协议的发送邮件服务器,用来发送或中转发出的电子邮件。
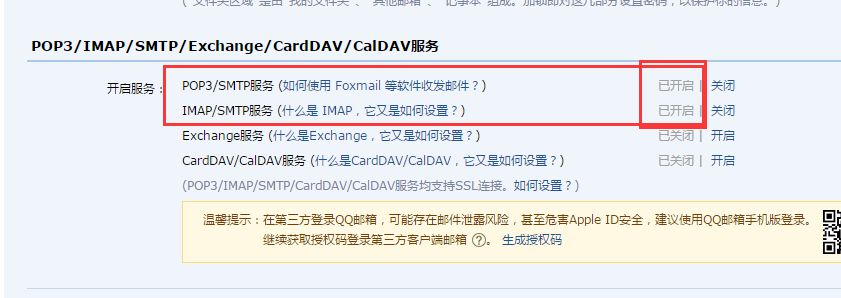
2、SMTP 邮件服务器开启
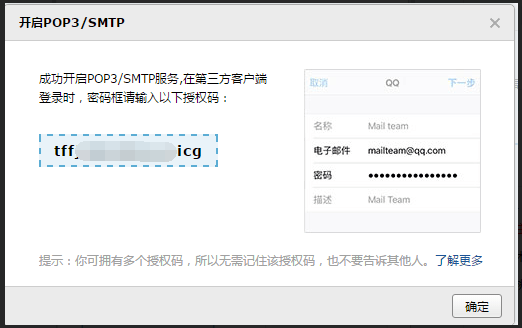
设置--账户--(POP3/SMTP服务)开启--(IMAP/SMTP服务)开启--(会分别得到两个授权码,授权码就是你在第三方登入时所使用的密码)
POP3/SMTP授权码:
IMAP/SMTP授权码:
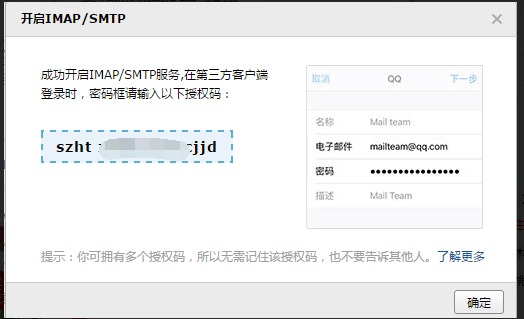
这两个授权码都是可以使用的。
3、发送邮件实例:
# -*- coding:utf-8 -*-
import smtplib#用来发送邮件
from email.mime.text import MIMEText#用来打包内容
#就是用来包装邮件的
msg = MIMEText("大家好,我是VAE,这是我发表的首张独创专辑自定义里面的","plain","utf-8")#第一个参数是发送的内容,第二个参数选择发生的是纯文本(plain),第三个是编码格式utf-8
msg['Subject'] = "邮件标题"
msg['From'] = "3323614864@qq.com"#发送源邮箱
msg['To'] = "913799761@qq.com"#目的源邮箱
server = smtplib.SMTP_SSL("smtp.qq.com",465)#实例化腾讯的邮件(smtp)服务器
server.set_debuglevel(1)#设置调试模式
server.login("3323614864@qq.com","********")#登录上面实例化的邮件服务器,第一个发送源邮箱帐号,第二个参数发送源授权码
server.sendmail("3323614864@qq.com",["913799761@qq.com"],msg.as_string()#发送邮件
server.quit()#退出服务器
最后,全部代码实现爬取+发送邮件:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import lxml
import re
import smtplib
from email.mime.text import MIMEText
def Spiderman(url):
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {'User-Agent': user_agent}
#url = r'http://career.fjnu.edu.cn/?viewnews-9909.cfm'
response = requests.get(url,headers=headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print('很抱歉,访问失败,访问状态码为:'+response.status_code+'请查询原因')
soup = BeautifulSoup(response.text,'lxml')
#time = soup.find('span').get_text().strip()
time02 = soup.find('div',id='article_body')
#print(time02.get_text().strip())
#place = soup.find(text=re.compile('地点')).strip()
#person = soup.find(text=re.compile('主办')).strip()
#dic = {}
#dic['time'] = time
#dic['place'] = place
#dic['person'] = person
s2 = time02.get_text().strip().split('\n')
return (s2[0:3])
def Spider(url):
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {'User-Agent':user_agent}
r = requests.get(url,headers=headers)
if r.status_code != 200:
r.encoding = 'utf-8'
print('很抱歉,访问失败,访问状态码为:'+r.status_code+'请查询原因')
soup = BeautifulSoup(r.text,'lxml')
companys = []
company_names = soup.find_all(href=re.compile("/?viewnews-\d+\.cfm"),title=False)
print(company_names[0].get_text())
for company_name in company_names:
company_name_href = r'http://career.fjnu.edu.cn'+company_name.get('href').strip()
companys.append(company_name_href)
print(companys)
messages = ''
for company,i in zip(companys,range(0,len(companys))):
list = []
list = Spiderman(company)
messages =messages+company_names[i].get_text().strip()+'\n'+list[0]+'\n'+list[1]+'\n'+list[2]+'\n'+'\n'+'\n'
try:
msg = MIMEText(messages,'plain','utf-8')
msg['Subject'] = "今日爬取"
msg['From'] = "3323614864@qq.com"
msg['To'] = "913799761@qq.com"
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login("3323614864@qq.com", "*********")
server.sendmail("3323614864@qq.com", ["913799761@qq.com"], msg.as_string())
server.quit()
print('邮件发送成功')
except:
print('邮件发送失败')
if __name__ == '__main__':
url = r"http://career.fjnu.edu.cn/?category-51.cfm"
print('正在为您爬取,请稍后')
try:
Spider(url)
print("恭喜您爬取成功")
except:
print("很抱歉,因为某些原因,爬取失败")1、第一步引入所需要的库,设置编码格式
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import lxml
import re
import smtplib
from email.mime.text import MIMEText2、第二步创建两个函数,if __name__ =='__main__':使得文件作为脚本直接执行
def Spiderman(url):
#爬取单个宣讲会的详细信息
pass
def Spider(url):
#爬取宣讲会的网址信息
pass
if __name__ == "__main__":
url = r"http://career.fjnu.edu.cn/?category-51.cfm"
Spider(url)
pass3、完善爬取宣讲会网址的函数
def Spiderman(url):
#爬取单个宣讲会的详细信息
pass
def Spider(url):
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {'User-Agent':user_agent}
r = requests.get(url,headers=headers)
if r.status_code != 200:
r.encoding = 'utf-8'
print('很抱歉,访问失败,访问状态码为:'+r.status_code+'请查询原因')
soup = BeautifulSoup(r.text,'lxml')
companys = []
company_names = soup.find_all(href=re.compile("/?viewnews-\d+\.cfm"),title=False)
print(company_names[0].get_text())
for company_name in company_names:
company_name_href = r'http://career.fjnu.edu.cn'+company_name.get('href').strip()
companys.append(company_name_href)
print(companys)
messages = ''
for company,i in zip(companys,range(0,len(companys))):
list = []
list = Spiderman(company)
messages =messages+company_names[i].get_text().strip()+'\n'+list[0]+'\n'+list[1]+'\n'+list[2]+'\n'+'\n'+'\n'
try:
msg = MIMEText(messages,'plain','utf-8')
msg['Subject'] = "今日爬取"
msg['From'] = "3323614864@qq.com"
msg['To'] = "913799761@qq.com"
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login("3323614864@qq.com", "*********")
server.sendmail("3323614864@qq.com", ["913799761@qq.com"], msg.as_string())
server.quit()
print('邮件发送成功')
except:
print('邮件发送失败')
if __name__ == '__main__':
url = r"http://career.fjnu.edu.cn/?category-51.cfm"
print('正在为您爬取,请稍后')
try:
Spider(url)
print("恭喜您爬取成功")
except:
print("很抱歉,因为某些原因,爬取失败")4、完善爬取单个宣讲会的信息的函数
def Spiderman(url):
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {'User-Agent': user_agent}
#url = r'http://career.fjnu.edu.cn/?viewnews-9909.cfm'
response = requests.get(url,headers=headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print('很抱歉,访问失败,访问状态码为:'+response.status_code+'请查询原因')
soup = BeautifulSoup(response.text,'lxml')
#time = soup.find('span').get_text().strip()
time02 = soup.find('div',id='article_body')
#print(time02.get_text().strip())
#place = soup.find(text=re.compile('地点')).strip()
#person = soup.find(text=re.compile('主办')).strip()
#dic = {}
#dic['time'] = time
#dic['place'] = place
#dic['person'] = person
s2 = time02.get_text().strip().split('\n')
return (s2[0:3])运行程序:

提示:开启stmp服务器,需要已经开通QQ邮箱14天,另外QQ邮箱的STMP服务器每天发送的邮件是有数量限制的,可以百度一下。
----------------------------
11.4再次实验,出了点问题,有空再处理下















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









