






《Netty 进阶之路》、《分布式服务框架原理与实践》作者李林锋深入剖析Netty消息接收类故障案例。李林锋此后还将在 InfoQ 上开设 Netty 专题持续出稿,感兴趣的同学可以持续关注。
1. 背景
1.1 消息接收类故障
尽管Netty应用广泛,非常成熟,但是由于对Netty底层机制不太了解,用户在实际使用中还是会经常遇到各种问题,大部分问题都是业务使用不当导致的。Netty使用者需要学习Netty的故障定位技巧,以便出了问题能够独立、快速的解决。
在各种故障中,Netty服务端接收不到客户端消息是一种比较常见的异常,大部分场景下都是用户使用不当导致的,下面我们对常见的消息接收接类故障进行分析和总结。
1.2 消息接收类故障定位技巧
如果业务的ChannelHandler接收不到消息,可能的原因如下:
业务的解码ChannelHandler存在BUG,导致消息解码失败,没有投递到后端。
业务发送的是畸形或者错误码流(例如长度错误),导致业务解码ChannelHandler无法正确解码出业务消息。
业务ChannelHandler执行了一些耗时或者阻塞操作,导致Netty的NioEventLoop被挂住,无法读取消息。
执行业务ChannelHandler的线程池队列积压,导致新接收的消息在排队,没有得到及时处理。
对方确实没有发送消息。
定位策略如下:
在业务的首个ChannelHandler的channelRead方法中打断点调试,看是否读取到消息。
在ChannelHandler中添加LoggingHandler,打印接口日志。
查看NioEventLoop线程状态,看是否发生了阻塞。
通过tcpdump抓包看消息是否发送成功。
2. 服务端接收不到车载终端消息
2.1 业务场景
车联网服务端使用Netty构建,接收车载终端的请求消息,然后下发给后端其它系统,最后返回应答给车载终端。系统运行一段时间后发现服务端接收不到车载终端消息,导致业务中断,需要尽快定位出问题原因。
2.2 故障现象
服务端运行一段时间之后,发现无法接收到车载终端的消息,相关日志示例如下:
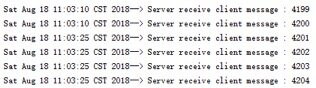
从日志看,服务端每隔一段时间(示例中是15秒,实际业务时间是随机的)就会接收不到消息,隔一段时间之后恢复,然后又没消息,周而复始。跟车载终端确认,终端设备每隔固定周期就会发送消息给服务端(日志分析),因此排除是终端没发消息导致的问题。怀疑是不是服务端负载过重,抢占不到CPU资源导致的周期性阻塞,采集CPU使用率,发现CPU资源不是瓶颈,排除CPU占用率高问题。
排除CPU之后,怀疑是不是内存有问题,导致频繁GC引起业务线程暂停。采集GC统计数据,示例如下:
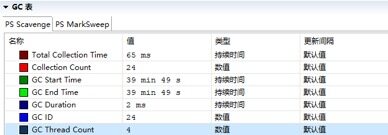
通过CPU和内存资源占用监控分析,发现硬件资源不是瓶颈,问题应该出在服务端代码侧。
2.3 故障分析
从现象上看,服务端接收不到消息,排除GC、网络等问题之后,很有可能是Netty的NioEventLoop线程阻塞,导致TCP缓冲区的数据没有及时读取,故障期间采集服务端的线程堆栈进行分析,示例如下:

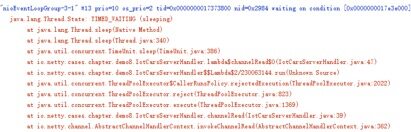
从线程堆栈分析,Netty的NioEventLoop读取到消息后,调用业务线程池执行业务逻辑时,发生了RejectedExecutionException异常,由于后续业务逻辑由NioEventLoop线程执行,因此可以判断业务使用了CallerRunsPolicy策略,即当业务线程池消息队列满之后,由调用方线程来执行当前的Runnable。NioEventLoop在执行业务任务时发生了阻塞,导致NioEventLoop线程无法处理网络读写消息,因此会看到服务端没有消息接入,当从阻塞状态恢复之后,就可以继续接收消息。
如果后端业务逻辑处理慢,则会导致业务线程池阻塞队列积压,当积压达到上限容量之后,JDK会抛出RejectedExecutionException异常,由于业务设置了CallerRunsPolicy策略,就会由调用方线程NioEventLoop执行业务逻辑,最终导致NioEventLoop线程被阻塞,无法读取请求消息。
除了JDK线程池异常处理策略使用不当之外,有些业务喜欢自己写阻塞队列,当队列满之后,向队列加入新的消息会阻塞当前线程,直到消息能够加入到队列中。案例中的车联网服务端真实业务代码就是此类问题:当转发给下游系统发生某些故障时,会导致业务定义的阻塞队列无法弹出消息进行处理,当队列积压满之后,就会阻塞Netty的NIO线程,而且无法自动恢复。
2.4 NioEventLoop线程防挂死策略
由于ChannelHandler是业务代码和Netty框架交汇的地方,ChannelHandler里面的业务逻辑通常由NioEventLoop线程执行,因此防止业务代码阻塞NioEventLoop线程就显得非常重要,常见的阻塞情况有两类:
直接在ChannelHandler写可能导致程序阻塞的代码,包括但不限于数据库操作、第三方服务调用、中间件服务调用、同步获取锁、Sleep等。
切换到业务线程池或者业务消息队列做异步处理时发生了阻塞,最典型的如阻塞队列、同步获取锁等。
在实际项目中,推荐业务处理线程和Netty网络I/O线程分离策略,原因如下:
充分利用多核的并行处理能力:I/O线程和业务线程分离,双方可以并行的处理网络I/O和业务逻辑,充分利用多核的并行计算能力,提升性能。
故障隔离:后端的业务线程池处理各种类型的业务消息,有些是I/O密集型、有些是CPU密集型、有些是纯内存计算型,不同的业务处理时延,以及发生故障的概率都是不同的。如果把业务线程和I/O线程合并,就会存在如下问题:
某类业务处理较慢,阻塞I/O线程,导致其它处理较快的业务消息的响应无法及时发送出去。
即便是同类业务,如果使用同一个I/O线程同时处理业务逻辑和I/O读写,如果请求消息的业务逻辑处理较慢,同样会导致响应消息无法及时发送出去。
可维护性:I/O线程和业务线程分离之后,双方职责单一,有利于代码维护和问题定位。如果合并在一起执行,当RPC调用时延增大之后,到底是网络问题、还是I/O线程问题、还是业务逻辑问题导致的时延大,纠缠在一起,问题定位难度非常大。例如业务线程中访问缓存或者数据库偶尔时延增大,就会导致I/O线程被阻塞,时延出现毛刺,这些时延毛刺的定位,难度非常大。
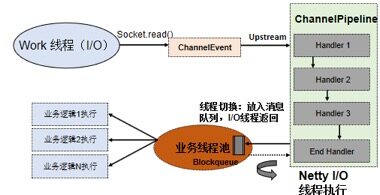
Netty I/O线程和业务逻辑处理线程分离之后,线程模型如下所示:
3. MQTT服务端拒绝接入
3.1 问题现象
生产环境的MQTT服务运行一段时间之后,发现有新的端侧设备无法接入,连接超时。分析MQTT服务端日志,没有明显的异常,但是内存占用较高,查看连接数,发现有数10万个TCP连接处于ESTABLISHED状态,实际的MQTT连接数应该在1万个左右,显然这么多的连接肯定存在问题。
由于MQTT服务端的内存是按照2万个左右连接数规模配置的,因此当连接数达到数十万规模之后,导致了服务端大量SocketChannel积压,内存暴涨,高频率的GC和较长的STW时间对端侧设备的接入造成了很大影响,导致部分设备MQTT握手超时,无法接入。
3.2 客户端连接数膨胀原因分析
通过抓包分析发现,一些端侧设备并没有按照MQTT协议规范进行处理,包括:
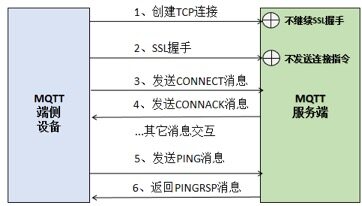
客户端发起CONNECT连接,SSL握手成功之后没有按照协议规范继续处理,例如发送PING命令。
客户端发起TCP连接,不做SSL握手,也不做后续处理,导致TCP连接被挂起。
由于服务端是严格按照MQTT协议规范实现的,上述端侧设备不按规范接入,实际上消息调度不到MQTT应用协议层。MQTT服务端依赖Keep Alive机制做超时检测,当一段时间接收不到客户端的心跳和业务消息时,就会触发心跳超时,关闭连接。针对上述两种接入场景,由于MQTT的连接流程没有完成,MQTT协议栈不认为这个是合法的MQTT连接,因此心跳保护机制无法对上述TCP连接做检测。客户端和服务端都没有主动关闭这个连接,导致TCP连接一直保持。
问题原因如下所示:
3.3 无效连接的关闭策略
针对这种不遵循MQTT规范的端侧设备,除了要求对方按照规范修改之外,服务端还需要做可靠性保护,具体策略如下:
端侧设备的TCP连接接入之后,启动一个链路检测定时器加入到Channel对应的NioEventLoop中。
链路检测定时器一旦触发,就主动关闭TCP连接。
TCP连接完成MQTT协议层的CONNECT之后,删除之前创建的链路检测定时器。
3.4 问题总结
生产环境升级补丁版本之后,平稳运行,查看MQTT连接数,稳定在1万个左右,与预期一致,问题得到解决。
对于MQTT服务端,除了要遵循协议规范之外,还需要对那些不遵循规范的客户端接入做保护,不能因为一些客户端没按照规范实现,导致服务端无法正常工作。系统的可靠性设计更多的是在异常场景下保护系统稳定运行。
4. HTTP消息被多次读取问题
针对Channel上发生的各种网络操作,例如链路创建、链路关闭、消息读写、链路注册和去注册等,Netty将这些消息封装成事件,触发ChannelPipeline调用ChannelHandler链,由系统或者用户实现的ChannelHandler对网络事件做处理。
由于网络事件种类比较多,触发和执行机制也存在一些差异,如果掌握不到位,很有可能遇到一些莫名其妙的问题。而且有些问题只有在高并发或者生产环境出现,测试床不容易复现,因此这类问题定位难度很大。
4.1 channelReadComplete方法被调用多次
故障场景:业务基于Netty开发了HTTP Server,在生产环境运行一段时间之后,部分消息逻辑处理错误,但是在灰度测试环境验证却无法重现问题,需要尽快定位并解决。
在生产环境中将某一个服务实例的调测日志打开一段时间,以便定位问题。通过接口日志分析,发现同一个HTTP请求消息,当发生问题时,业务ChannelHandler的channelReadComplete方法会被调用多次,但是大部分消息都是调用一次,按照业务的设计初衷,当服务端读取到一个完整的HTTP请求消息之后,在channelReadComplete方法中进行业务逻辑处理。如果一个请求消息它的channelReadComplete方法被调用多次,则业务逻辑就会出现异常。
通过对客户端请求消息和Netty框架源码分析,找到了问题根因:TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的拆分,所以在业务上认为一个完整的HTTP报文可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送。导致数据报拆分和重组的原因如下:
应用程序write写入的字节大小大于套接口发送缓冲区大小。
进行MSS大小的TCP分段。
以太网帧的payload大于MTU进行IP分片。
开启了TCP Nagle’s algorithm。
由于底层的TCP无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案,可以归纳如下:
消息定长,例如每个报文的大小为固定长度200字节,如果不够,空位补空格。
在包尾增加回车换行符(或者其它分隔符)进行分割,例如FTP协议。
将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常设计思路为消息头的第一个字段使用int32来表示消息的总长度。
对于HTTP请求消息,当业务并发量比较大时,无法保证一个完整的HTTP消息会被一次全部读取到服务端。当采用chunked方式进行编码时,HTTP报文也是分段发送的,此时服务端读取到的也不是完整的HTTP报文。为了解决这个问题,Netty提供了HttpObjectAggregator,保证后端业务ChannelHandler接收到的是一个完整的HTTP报文,相关示例代码如下所示:
*//**代码省略...* *ChannelPipeline p = ...;* *p.addLast(\u0026quot;decoder\u0026quot;, new HttpRequestDecoder());* *p.addLast(\u0026quot;encoder\u0026quot;, new HttpResponseEncoder());* *p.addLast(\u0026quot;aggregator\u0026quot;, new HttpObjectAggregator(10240));* *p.addLast(\u0026quot;service\u0026quot;, new ServiceChannelHandler());* *//**代码省略...*通过HttpObjectAggregator可以保证当Netty读取到完整的HTTP请求报文之后才会调用一次业务ChannelHandler的channelRead方法,无论这条报文底层经过了几次SocketChannel的read调用。但是对于channelReadComplete方法,它并不是业务语义上的读取消息完成之后触发,而是每次从SocketChannel成功读取到消息之后,系统就会触发对channelReadComplete方法的调用,也就是说如果一个HTTP消息被TCP协议栈发送了N次,则服务端的channelReadComplete方法就会被调用N次。
在灰度测试环境中,由于客户端并没有采用chunked的编码方式,并发压力也不是很高,所以一直没有发现该问题,到了生产环境有些客户端采用了chunked方式发送HTTP请求消息,客户端并发量也比较高,所以触发了服务端BUG。
4.2 ChannelHandler使用的一些误区
ChannelHandler由ChannelPipeline触发,业务经常使用的方法包括channelRead方法、channelReadComplete方法和exceptionCaught方法等,它的使用比较简单,但是里面还是有一些容易出错的地方,使用不当就会导致诸如上述案例中的问题。
4.2.1 channelReadComplete****方法调用
对于channelReadComplete方法的调用,很容易误认为前面已经增加了对应协议的编解码器,所以只有消息解码成功之后才会调用channelReadComplete方法。实际上它的调用与用户是否添加协议解码器无关,只要对应的SocketChannel成功读取到了ByteBuf,它就会被触发,相关代码如下所示(NioByteUnsafe类):
*public final void read() {* *//**代码省略...* *try {* *do {* *byteBuf = allocHandle.allocate(allocator);* *allocHandle.lastBytesRead(doReadBytes(byteBuf));* *if (allocHandle.lastBytesRead() \u0026lt;= 0) {* *byteBuf.release();* *byteBuf = null;* *close = allocHandle.lastBytesRead() \u0026lt; 0;* *if (close) {* *readPending = false;* *}* *break;* *}* *allocHandle.incMessagesRead(1);* *readPending = false;* *pipeline.fireChannelRead(byteBuf);* *byteBuf = null;* *} while (allocHandle.continueReading());* *allocHandle.readComplete();* *pipeline.fireChannelReadComplete();* *//**代码省略...**}*对于大部分的协议解码器,例如Netty内置的ByteToMessageDecoder,它会调用具体的协议解码器对ByteBuf做解码,只有解码成功之后,才会调用后续ChannelHandler的channelRead方法,代码如下所示(ByteToMessageDecoder类):
*static void fireChannelRead(ChannelHandlerContext ctx, CodecOutputList msgs, int numElements) {* *for (int i = 0; i \u0026lt; numElements; i ++) {* *ctx.fireChannelRead(msgs.getUnsafe(i));* *}**}*但是对于channelReadComplete方法则是透传调用,即无论是否有完整的消息被解码成功,只要读取到消息,都会触发后续ChannelHandler的channelReadComplete方法调用,代码如下所示(ByteToMessageDecoder类):
*public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {* *numReads = 0;* *discardSomeReadBytes();* *if (decodeWasNull) {* *decodeWasNull = false;* *if (!ctx.channel().config().isAutoRead()) {* *ctx.read();* *}* *}* *ctx.fireChannelReadComplete();**}*4.2.2 ChannelHandler职责链调用
ChannelPipeline以链表的方式管理某个Channel对应的所有ChannelHandler,需要说明的是下一个ChannelHandler的触发需要在当前ChannelHandler中显式调用,而不是自动触发式调用,相关代码示例如下(SslHandler类):
*public void channelActive(final ChannelHandlerContext ctx) throws Exception {* *if (!startTls) {* *startHandshakeProcessing();* *}* *ctx.fireChannelActive();**}*如果遗忘了调用ctx.fireChannelActive方法,则SslHandler后续的ChannelHandler的channelActive方法将不会被执行,职责链执行到SslHandler就会中断。
Netty内置的TailContext有时候会执行一些系统性的清理操作,例如当channelRead方法执行完成,将请求消息(例如ByteBuf)释放掉,防止因为业务遗漏释放而导致内存泄漏(内存池模式下会导致内存泄漏),相关代码如下所示(TailContext类):
*protected void onUnhandledInboundMessage(Object msg) {* *try {* *logger.debug(* *\u0026quot;Discarded inbound message {} that reached at the tail of the pipeline. \u0026quot; +* *\u0026quot;Please check your pipeline configuration.\u0026quot;, msg);* *} \\**finally {*** **ReferenceCountUtil.release(msg);** **}***}*当执行完业务最后一个ChannelHandler时,需要判断是否需要调用系统的TailContext,如果需要,则通过ctx.firexxx方法调用。
4.3 总结
通常情况下,在功能测试或者并发压力不大时,HTTP请求消息可以一次性接收完成,此时ChannelHandler的channelReadComplete方法会被调用一次,但是当一个整包消息经过多次读取才能完成解码时,channelReadComplete方法就会被触发调用多次。如果业务的功能正确性依赖channelReadComplete方法的调用次数,当客户端并发压力大或者采用chunked编码时,功能就会出错。因此,需要熟悉和掌握Netty的事件触发机制以及ChannelHandler的调用策略,这样才能防止在生成环境踩坑。
5. 作者简介
李林锋,10年Java NIO、平台中间件设计和开发经验,精通Netty、Mina、分布式服务框架、API Gateway、PaaS等,《Netty进阶之路》、《分布式服务框架原理与实践》作者。目前在华为终端应用市场负责业务微服务化、云化、全球化等相关设计和开发工作。
联系方式:新浪微博 Nettying 微信:Nettying
Email:neu_lilinfeng@sina.com














 4095
4095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









