






原博地址:http://blog.sciencenet.cn/blog-377709-1102168.html 超级好的博主,很详细,适合零基础学习。
Anaconda 下anaconda prompt:pip install pipenv
运行完后运行: pipenv install
安装软件包requests_html:pip install requests_html
读入网页加以解析抓取,需要用到的软件包是 requests_html 。
from requests_html import HTMLSession
session = HTMLSession() #建立一个会话,让python作为一个客户端,和远端服务器交谈
url = 'https://www.jianshu.com/p/85f4624485b9' #输入爬取网址
r = session.get(url) #利用 session 的 get 功能,把这个链接对应的网页整个儿取回来
print(r.html.text)#我们告诉Python,请把服务器传回来的内容当作HTML文件类型处理。我不想要看HTML里面那些乱七八糟的格式描述符,只看文字部分。
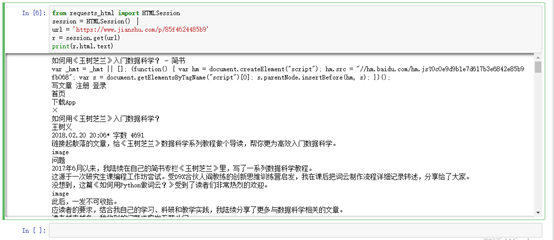
获取网页中的所有链接
把返回的内容作为HTML文件类型,我们查看 links 属性:
r.html.links
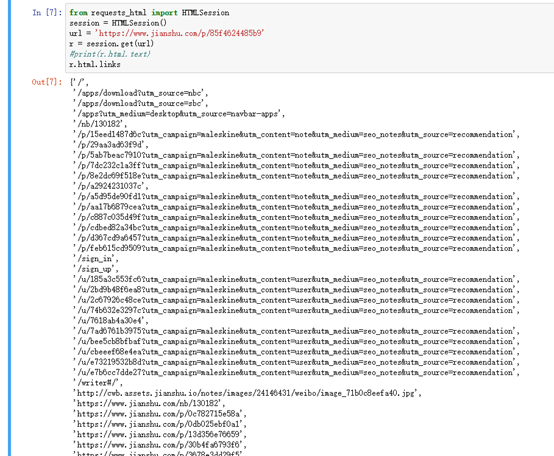
注释:看似不完整的链接,是相对链接,它是某个链接,相对于我们采集的网页所在域名(https://www.jianshu.com)的路径。
获取绝对链接的方法:
r.html.absolute_links
所谓HTML,就是一种标记语言(超文本标记语言,HyperText Markup Language)。
标记的作用是什么?它可以把整个的文件分解出层次来
用谷歌浏览器打开爬取网页,右击鼠标,点击检查,或者点击F12,这时,屏幕下方就会出现一个分栏。我们点击这个分栏左上角(上图红色标出)的按钮。然后把鼠标悬停在第一个文内链接(《玉树芝兰》)上面,点击一下。
此时,你会发现下方分栏里面,内容也发生了变化。这个链接对应的源代码被放在分栏区域正中,高亮显示。
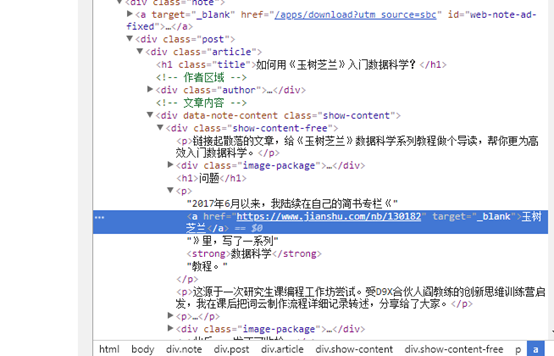
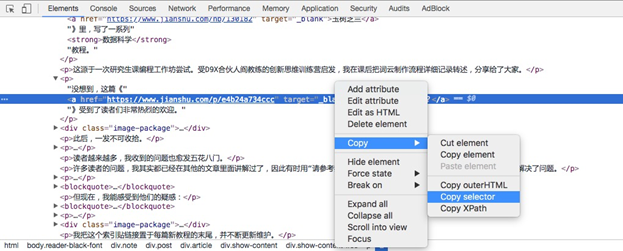
确认该区域就是我们要找的链接和文字描述后,我们鼠标右键选择高亮区域,并且在弹出的菜单中,选择 Copy -> Copy selector。
找一个文本编辑器,执行粘贴,就可以看见我们究竟复制下来了什么内容。
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a
这一长串的标记,为电脑指出了:请你先找到 body 标记,进入它管辖的这个区域后去找 div.note 标记,然后找……最后找到 a 标记,这里就是要找的内容了。
回到咱们的 Jupyter Notebook 中,用刚才获得的标记路径,定义变量sel。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a'
我们让 Python 从返回内容中,查找 sel 对应的位置,把结果存到 results 变量中。
results = r.html.find(sel)
我们看看 results 里面都有什么。
results
这是结果:
[<Element 'a' href='https://www.jianshu.com/nb/130182' target='_blank'>]
results 是个列表,只包含一项。这一项包含一个网址,就是我们要找的第一个链接(《玉树芝兰》)对应的网址。
可是文字描述“《玉树芝兰》”哪里去了?
别着急,我们让 Python 显示 results 结果数据对应的文本。
results[0].text
这是输出结果:
'玉树芝兰'
我们把链接也提取出来:
results[0].absolute_links
显示的结果却是一个集合。
{'https://www.jianshu.com/nb/130182'}
我们不想要集合,只想要其中的链接字符串。所以我们先把它转换成列表,然后从中提取第一项,即网址链接。
list(results[0].absolute_links)[0]
这次,终于获得我们想要的结果了:
'https://www.jianshu.com/nb/130182'
有了处理这第一个链接的经验,你信心大增,是吧?
其他链接,也无非是找到标记路径,然后照猫画虎嘛。
可是,如果每找一个链接,都需要手动输入上面这若干条语句,那也太麻烦了。
这里就是编程的技巧了。重复逐条运行的语句,如果工作顺利,我们就要尝试把它们归并起来,做个简单的函数。
对这个函数,只需给定一个选择路径(sel),它就把找到的所有描述文本和链接路径都返回给我们。
def get_text_link_from_sel(sel):
mylist = []
try:
results = r.html.find(sel)
for result in results:
mytext = result.text
mylink = list(result.absolute_links)[0]
mylist.append((mytext, mylink))
return mylist
except:
return None
我们测试一下这个函数。
还是用刚才的标记路径(sel)不变,试试看。
print(get_text_link_from_sel(sel))
输出结果如下:
[('玉树芝兰', 'https://www.jianshu.com/nb/130182')]
没问题,对吧?
好,我们试试看第二个链接。
我们还是用刚才的方法,使用下面分栏左上角的按钮点击第二个链接。
下方出现的高亮内容就发生了变化:
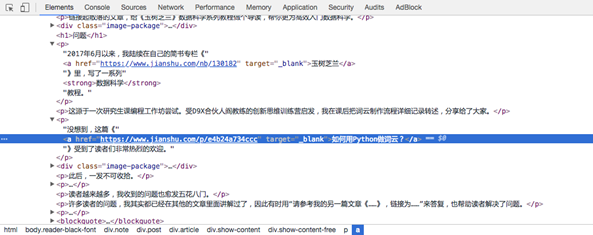
我们还是用鼠标右键点击高亮部分,拷贝出 selector。
然后我们直接把获得的标记路径写到 Jupyter Notebook 里面。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p:nth-child(6) > a'
用我们刚才编制的函数,看看输出结果是什么?
print(get_text_link_from_sel(sel))
输出如下:
[('如何用Python做词云?', 'https://www.jianshu.com/p/e4b24a734ccc')]
检验完毕,函数没有问题。
下一步做什么?
你还打算去找第三个链接,仿照刚才的方法做?
那你还不如全文手动摘取信息算了,更省事儿一些。
我们要想办法把这个过程自动化。
对比一下刚刚两次我们找到的标记路径:
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a
以及:
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(6) > a
发现什么规律没有?
对,路径上其他的标记全都是一样的,唯独倒数第二个标记("p")后冒号后内容有区别。
这就是我们自动化的关键了。
上述两个标记路径里面,因为指定了在第几个“子”(nth-child)文本段(paragraph,也就是"p"代表的含义)去找"a"这个标记,因此只返回来单一结果。
如果我们不限定"p"的具体位置信息呢?
我们试试看,这次保留标记路径里面其他全部信息,只修改"p"这一点。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p > a'
再次运行我们的函数:
print(get_text_link_from_sel(sel))
这是输出结果:

好了,我们要找的内容,全都在这儿了。
但是,我们的工作还没完。
我们还得把采集到的信息输出到Excel中保存起来。
还记得我们常用的数据框工具 Pandas 吗?又该让它大显神通了。
import pandas as pd
只需要这一行命令,我们就能把刚才的列表变成数据框:
df = pd.DataFrame(get_text_link_from_sel(sel))
让我们看看数据框内容:df
更换为更有意义的列名称:
df.columns = ['text', 'link']
再看看数据框内容:df

好了,下面就可以把抓取的内容输出到Excel中了。
Pandas内置的命令,就可以把数据框变成csv格式,这种格式可以用Excel直接打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意这里需要指定encoding(编码)为gbk,否则默认的utf-8编码在Excel中查看的时候,有可能是乱码。
可以点击查看输出文件,是想要的格式。















 2015
2015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









