







本期内容:
1. KafkaInputDStream源码解密
2. KafkaReceiver源码解密
Direct方式,是No Receiver方式,和普通Receiver方式,最大的区别,是元数据的管理方式。
Direct方式是没有通过zookeeper,由应用自身来管理。
KafkaUtils.createDirectStream:
/**
* Create an input stream that directly pulls messages from Kafka Brokers
* without using any receiver. This stream can guarantee that each message
* from Kafka is included in transformations exactly once (see points below).
*
* Points to note:
* - No receivers: This stream does not use any receiver. It directly queries Kafka
* - Offsets: This does not use Zookeeper to store offsets. The consumed offsets are tracked
* by the stream itself. For interoperability with Kafka monitoring tools that depend on
* Zookeeper, you have to update Kafka/Zookeeper yourself from the streaming application.
* You can access the offsets used in each batch from the generated RDDs (see
* [[org.apache.spark.streaming.kafka.HasOffsetRanges]]).
* - Failure Recovery: To recover from driver failures, you have to enable checkpointing
* in the [[StreamingContext]]. The information on consumed offset can be
* recovered from the checkpoint. See the programming guide for details (constraints, etc.).
* - End-to-end semantics: This stream ensures that every records is effectively received and
* transformed exactly once, but gives no guarantees on whether the transformed data are
* outputted exactly once. For end-to-end exactly-once semantics, you have to either ensure
* that the output operation is idempotent, or use transactions to output records atomically.
* See the programming guide for more details.
*
* @param ssc StreamingContext object
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>. Requires "metadata.broker.list" or "bootstrap.servers"
* to be set with Kafka broker(s) (NOT zookeeper servers) specified in
* host1:port1,host2:port2 form.
* @param fromOffsets Per-topic/partition Kafka offsets defining the (inclusive)
* starting point of the stream
* @param messageHandler Function for translating each message and metadata into the desired type
* @tparam K type of Kafka message key
* @tparam V type of Kafka message value
* @tparam KD type of Kafka message key decoder
* @tparam VD type of Kafka message value decoder
* @tparam R type returned by messageHandler
* @return DStream of R
*/
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K]: ClassTag,
VD <: Decoder[V]: ClassTag,
R: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
fromOffsets: Map[TopicAndPartition, Long],
messageHandler: MessageAndMetadata[K, V] => R
): InputDStream[R] = {
val cleanedHandler = ssc.sc.clean(messageHandler)
new DirectKafkaInputDStream[K, V, KD, VD, R](
ssc, kafkaParams, fromOffsets, cleanedHandler)
}
我们来看看Receiver方式。
KafkaUtils.createStream:
/**
* Create an input stream that pulls messages from Kafka Brokers.
* @param ssc StreamingContext object
* @param zkQuorum Zookeeper quorum (hostname:port,hostname:port,..)
* @param groupId The group id for this consumer
* @param topics Map of (topic_name -> numPartitions) to consume. Each partition is consumed
* in its own thread
* @param storageLevel Storage level to use for storing the received objects
* (default: StorageLevel.MEMORY_AND_DISK_SER_2)
* @return DStream of (Kafka message key, Kafka message value)
*/
def createStream(
ssc: StreamingContext,
zkQuorum: String,
groupId: String,
topics: Map[String, Int],
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[(String, String)] = {
val kafkaParams = Map[String, String](
"zookeeper.connect" -> zkQuorum, "group.id" -> groupId,
"zookeeper.connection.timeout.ms" -> "10000")
createStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topics, storageLevel)
}
在Receiver的工厂方法,有一些比较重要的参数:
- zkQuorum,就是zookeeper的地址,一般是奇数个。数据是存储在broker中的,所以只是从zookeeper去查询我们需要的数据在哪里,由zookeeper来管理offset等元数据的信息。
- groupId,sparkStreaming在消费kafka的数据时,是分group的,当进行不同业务类型消费时,会很需要。
- topics,表明消费的内容,每个partition有个单独的线程来抓取数据。
- storageLevel,存储级别,模式是MEMORY_AND_DISK_SER_2,内存放的下放在内存,否则放磁盘,所以不用担心内存不够的问题。
我们可以看到,Receiver方式需要传入zookeeper的地址。
KafkaReceiver
根据前面的课程,我们知道InputDStream最终都会创建一个Receiver对象来工作,在这个功能中,就是KakfaReceiver。
在onStart方法中,最为关键的就是创建consumerConnector。
KafkaInputDStream.
onStart:
def onStart() {
logInfo("Starting Kafka Consumer Stream with group: " + kafkaParams("group.id"))
// Kafka connection properties
val props = new Properties()
kafkaParams.foreach(param => props.put(param._1, param._2))
val zkConnect = kafkaParams("zookeeper.connect")
// Create the connection to the cluster
logInfo("Connecting to Zookeeper: " + zkConnect)
val consumerConfig = new ConsumerConfig(props)
consumerConnector = Consumer.create(consumerConfig)
logInfo("Connected to " + zkConnect)
val keyDecoder = classTag[U].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(consumerConfig.props)
.asInstanceOf[Decoder[K]]
val valueDecoder = classTag[T].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(consumerConfig.props)
.asInstanceOf[Decoder[V]]
// Create threads for each topic/message Stream we are listening
val topicMessageStreams = consumerConnector.createMessageStreams(
topics, keyDecoder, valueDecoder)
val executorPool =
ThreadUtils.newDaemonFixedThreadPool(topics.values.sum, "KafkaMessageHandler")
try {
// Start the messages handler for each partition
topicMessageStreams.values.foreach { streams =>
streams.foreach { stream => executorPool.submit(new MessageHandler(stream)) }
}
} finally {
executorPool.shutdown() // Just causes threads to terminate after work is done
}
}
内部会生成一个zookeeperConsumerConnector,这是一个门面模式,封装了与zookeeper沟通的细节。在其中,最关键的是调用了下面三个方法。
也就是,创建zk连接,创建fetcher,并且将zk中的元数据与fetcher进行连接。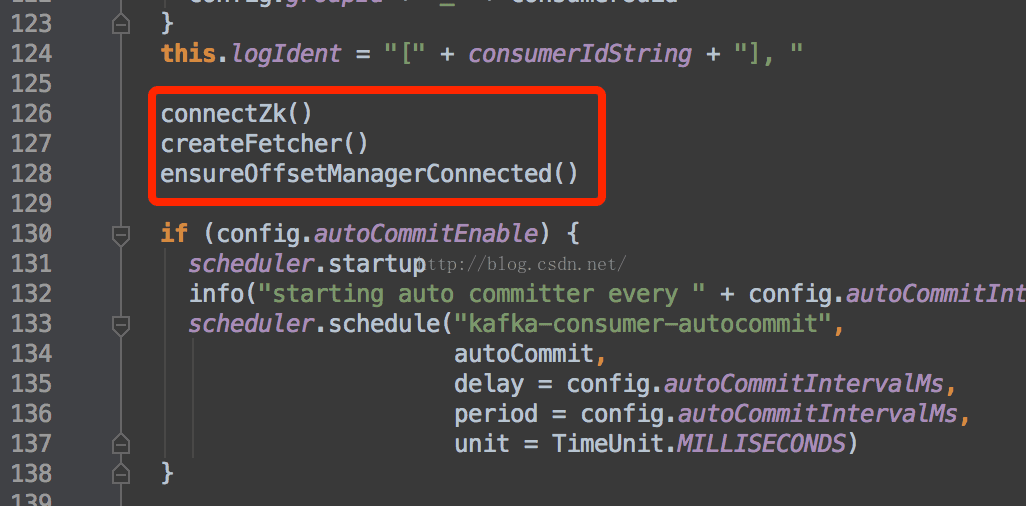
然后,是根据consumer连接来获取stream,consumer获取数据过程前面已经完整介绍过,这里就不重复说明。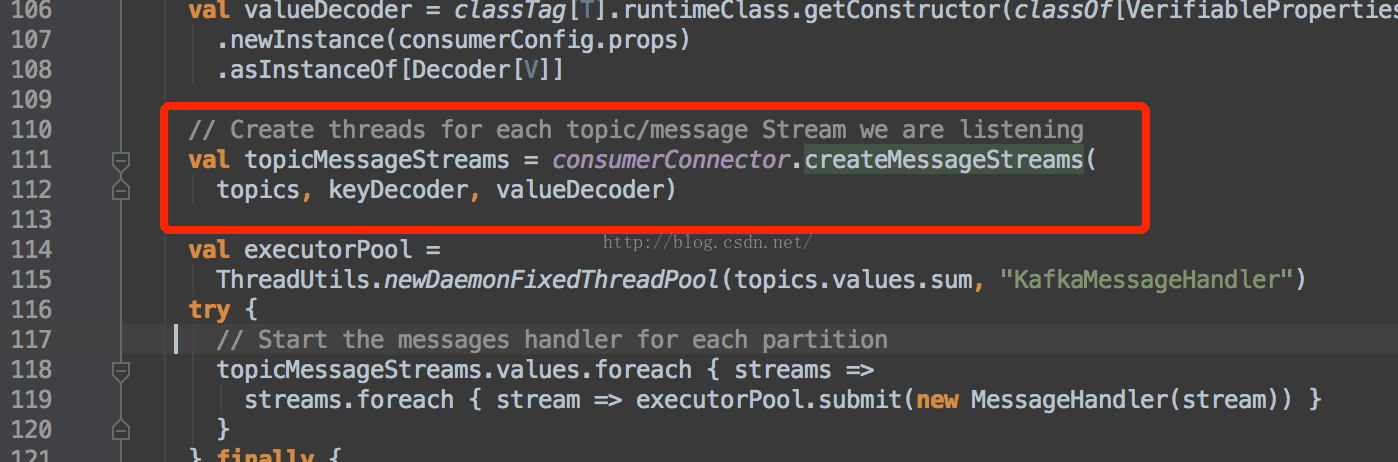
最后,会跟据监听的不同的topic,开启线程,每一个线程中都放一个MessageHandler。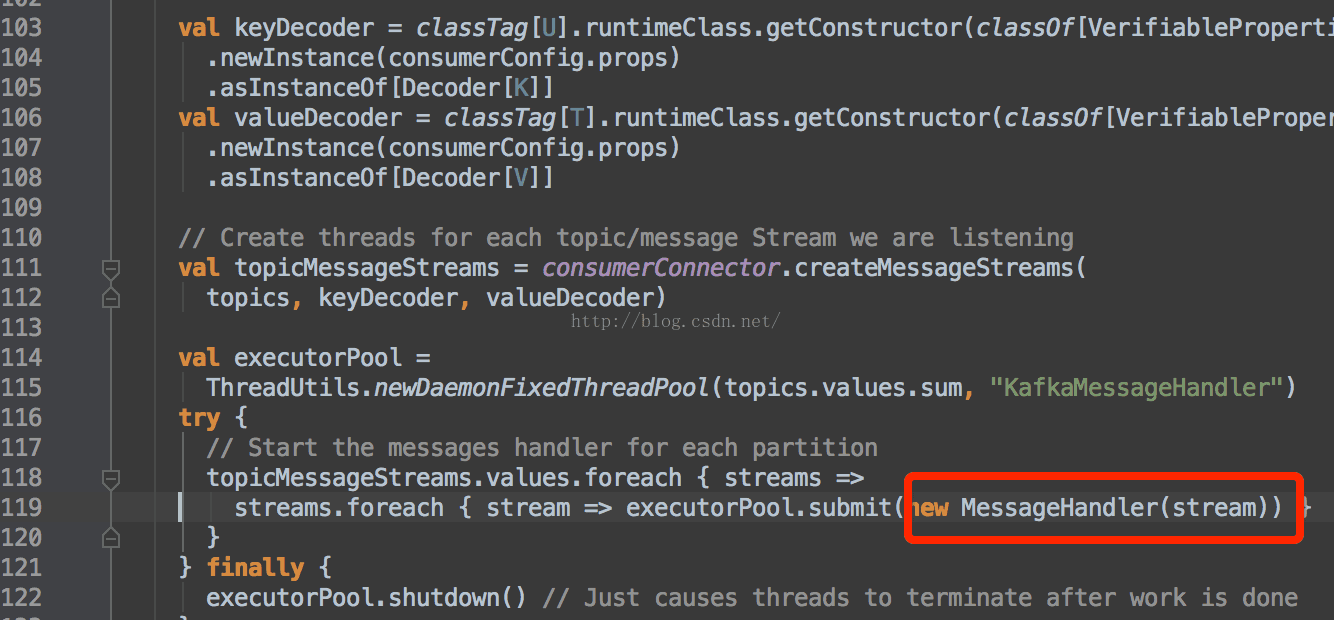
MessageHandler里面的功能就是取出数据,然后store给Spark。
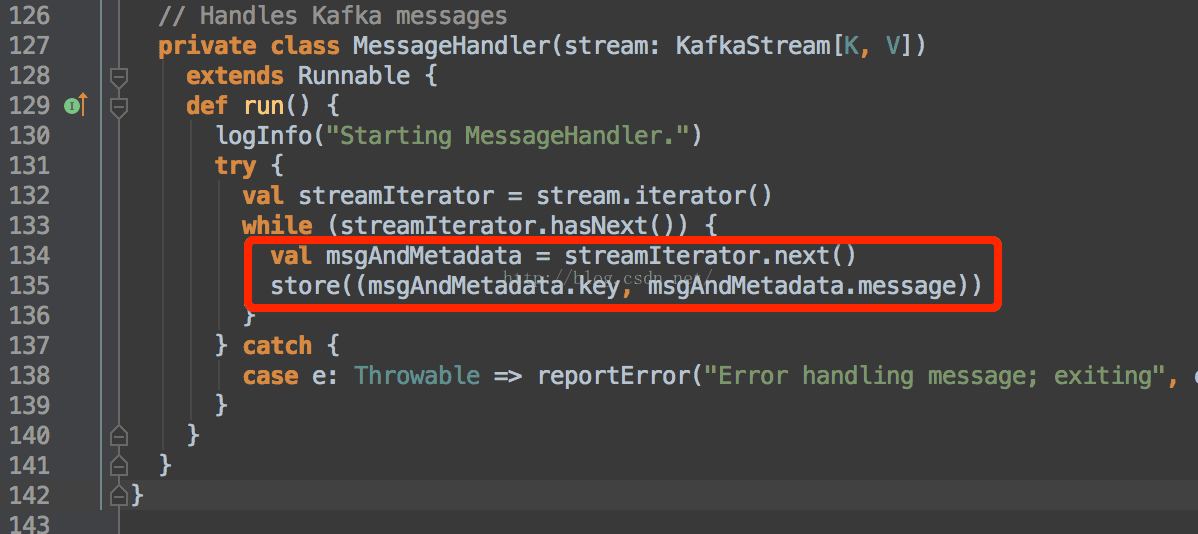
至此,完成了数据获取。
http://blog.csdn.net/andyshar/article/details/52143821















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









