







网关(Spring Cloud Gateway)
概述
Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
Spring Cloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代 Netflix Zuul,其不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全、监控、埋点和限流等。
Spring Cloud Gateway 的特征:
- 基于 Spring Framework 5,Project Reactor 和 Spring Boot 2.0 动态路由
- Predicates 和 Filters 作用于特定路由
- 集成 Hystrix 断路器
- 集成 Spring Cloud DiscoveryClient
- 易于编写的 Predicates 和 Filters
- 限流
- 路径重写
与 Spring Cloud Netflix Zuul
- Spring Cloud Netflix Zuul 1.x是由Netflix开源的API网关,在微服务架构下,网关作为对外的门户,实现动态路由、监控、授权、安全、调度等功能。 Zuul基于servlet 2.5(使用3.x),使用阻塞API。 它不支持任何长连接,如websockets。Zuul已经发布了Zuul 2.x,基于Netty,也是非阻塞的,支持长连接,但Spring Cloud暂时还没有整合计划。
- Spring Cloud Gateway基于Webflux,建立在Spring Framework 5,Project Reactor和Spring Boot 2之上,使用非阻塞API。 比较完美地支持异步非阻塞编程。Gateway 中Websockets得到支持,并且由于它与Spring紧密集成,所以将会是一个更好的开发体验。在Gateway中定义了丰富的路由断言和过滤器,通过配置文件或者Fluent API可以直接调用和使用,非常方便。在性能上,也是胜于之前的Zuul网关。
术语
- Route(路由):这是网关的基本构建块。它由一个 ID,一个目标 URI,一组断言和一组过滤器定义。如果断言为真,则路由匹配。
- Predicate(断言):这是一个 Java 8 的 Predicate。输入类型是一个 ServerWebExchange。我们可以使用它来匹配来自 HTTP 请求的任何内容,例如 headers 或参数。
- Filter(过滤器):这是org.springframework.cloud.gateway.filter.GatewayFilter的实例,我们可以使用它修改请求和响应。
流程
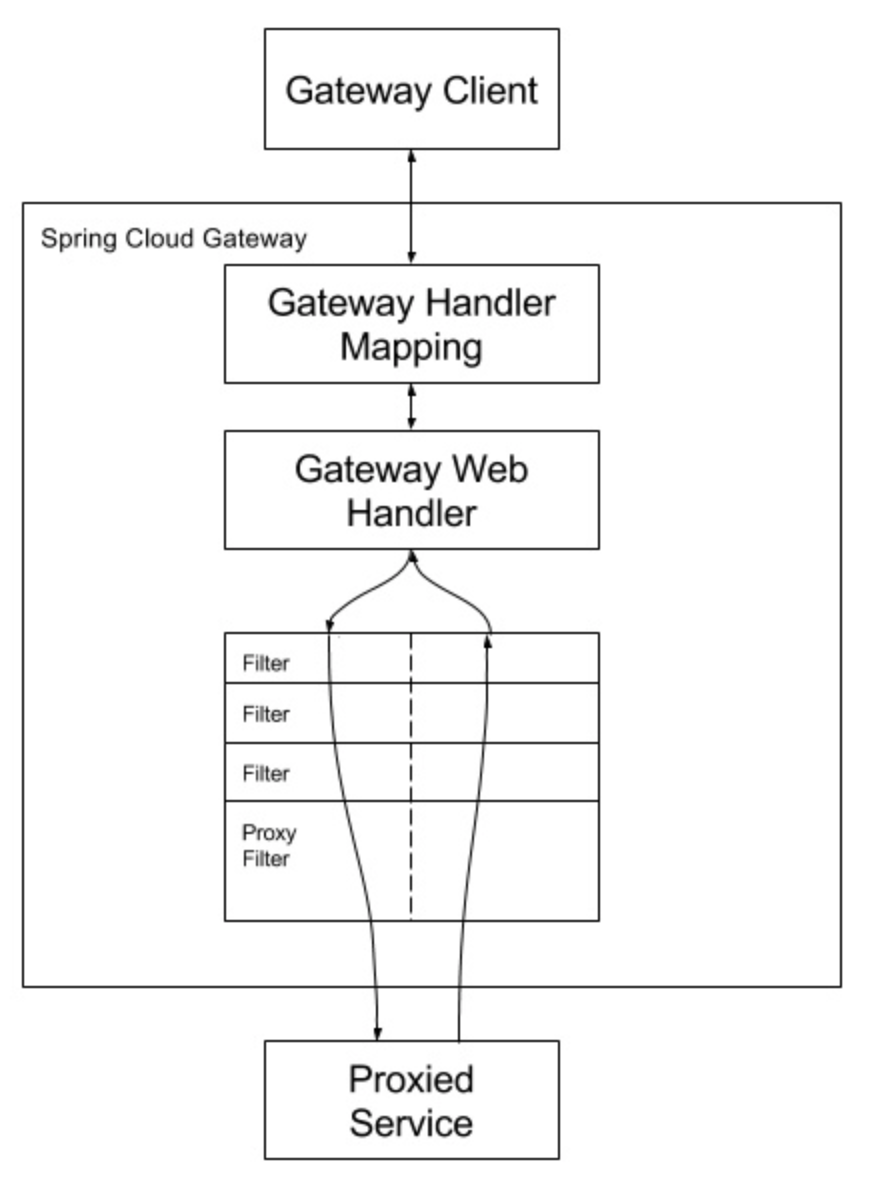
客户端向 Spring Cloud Gateway 发出请求。然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。Handler 再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。 过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑。
实战
路由
新建一个标准的 Spring Boot 工程,命名为 gateway-woqu,然后编辑 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>common-server-woqu</artifactId>
<groupId>com.orrin</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>gateway-woqu</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.jolokia</groupId>
<artifactId>jolokia-core</artifactId>
</dependency>
<dependency>
<groupId>com.orrin</groupId>
<artifactId>model-woqu</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
application.yml 配置文件内容如下
spring:
application:
name: common-server-gateway
cloud:
consul:
host: woqu.consul
port: 8500
discovery:
instance-id: ${spring.application.name}
instance-group: ${spring.application.name}
register: true
service-name: ${spring.application.name}
gateway:
discovery:
locator:
enabled: true
routes:
- id: business-a-woqu
uri: lb://business-a-woqu
order: 10000
predicates:
- Path=/api/a/**
- StripPrefix=2
server:
port: 7001
logging:
level:
org.springframework.cloud.gateway: debug
配置说明:
- spring.cloud.gateway.discovery.locator.enabled:是否与服务注册于发现组件进行结合,通过 serviceId 转发到具体的服务实例。默认为false,设为true便开启通过服务中心的自动根据 serviceId 创建路由的功能。
- spring.cloud.gateway.routes用于配合具体的路由规则,是一个数组。这里我创建了一个 id 为business-a-woqu的路由,其中的配置是将匹配/api/a/**的请求转发到lb://business-a-woqu,实际上开启了服务发现后,将请求转发到业务系统A。StripPrefix=2表示 比如请求/api/a/foo,去除掉前面两个前缀之后,最后转发到目标服务的路径为/foo,对应StripPrefixGatewayFilterFactory类
- 网关服务监听7001端口
- 指定注册中心的地址,以便使用服务发现功能
新建启动类GatewayApp.java
/**
* @author orrin
*/
@SpringBootApplication
@EnableDiscoveryClient
@ComponentScan(value = "com.woqu")
public class GatewayApp {
public static void main(String[] args) {
SpringApplication.run(GatewayApp.class, args);
}
}
启动 consul服务、GatewayApp、BusinessAApp ,可以在consul界面看到启动的服务。 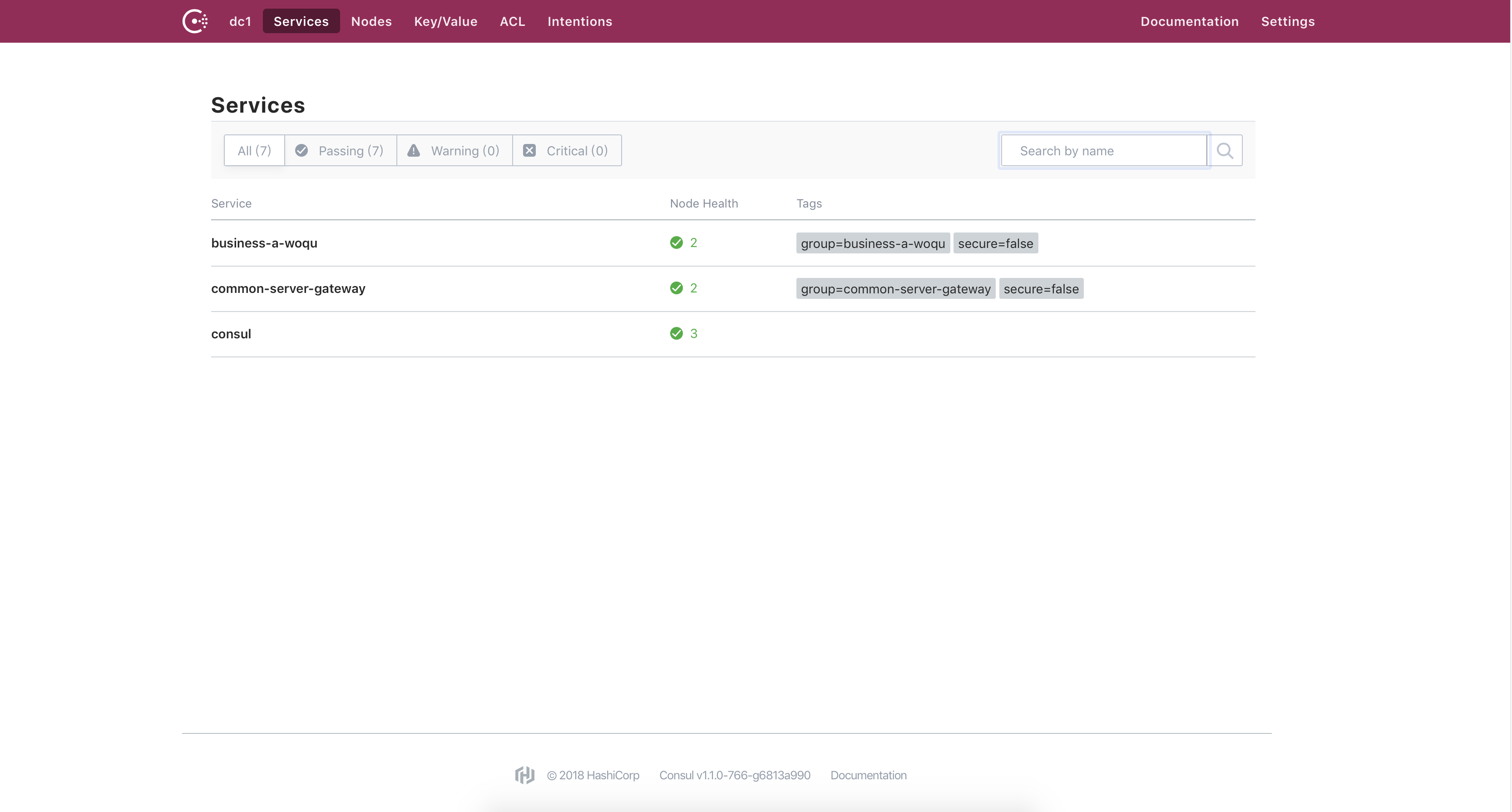
访问端点,测试路由情况
GET http://127.0.0.1:7001/api/a/add?x=2&y=3
HTTP/1.1 200 OK
transfer-encoding: chunked
X-RateLimit-Remaining: -1
X-RateLimit-Burst-Capacity: 5
X-RateLimit-Replenish-Rate: 1
Content-Type: application/json;charset=UTF-8
Date: Mon, 19 Nov 2018 03:09:18 GMT
5
Response code: 200 (OK); Time: 1205ms; Content length: 1 bytes
Spring Cloud Gateway 也支持通过 Java 的流式 API 进行路由的定义,如下就是一个和上边通过配置文件配置的等效的路由,并且可以和配置文件搭配使用。通过这种方式,我们可以实现动态路由。
@Bean
public RouteLocator customerRouteLocator(RouteLocatorBuilder builder) {
// @formatter:off
return builder.routes()
.route(r -> r.path("/api/a/**")
.filters(f -> f.stripPrefix(2)
.addResponseHeader("X-Response-Default-Foo", "Default-Bar"))
.uri("lb://business-a-woqu")
.order(0)
.id("business-a-woqu")
)
.build();
// @formatter:on
}
过滤器
Spring Cloud Gateway 已经内置了很多实用的过滤器,但并不能完全满足我们的需求。本文我们就来实现自定义过滤器。虽然现在 Spring Cloud Gateway 的文档还不完善,但可以大概画出如下类图。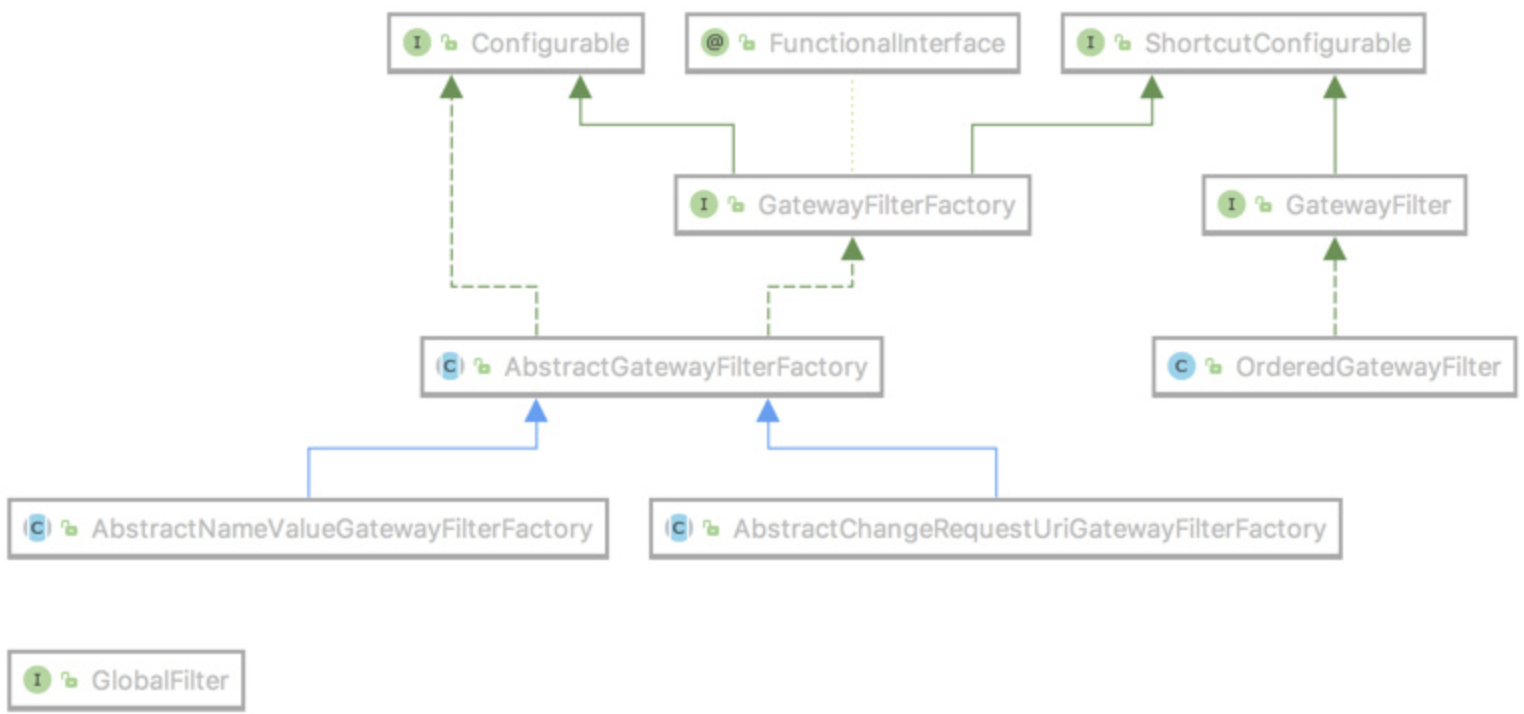
Filter 的生命周期
Spring Cloud Gateway 的 Filter 的生命周期不像 Zuul 的那么丰富,它只有两个:“pre” 和 “post”。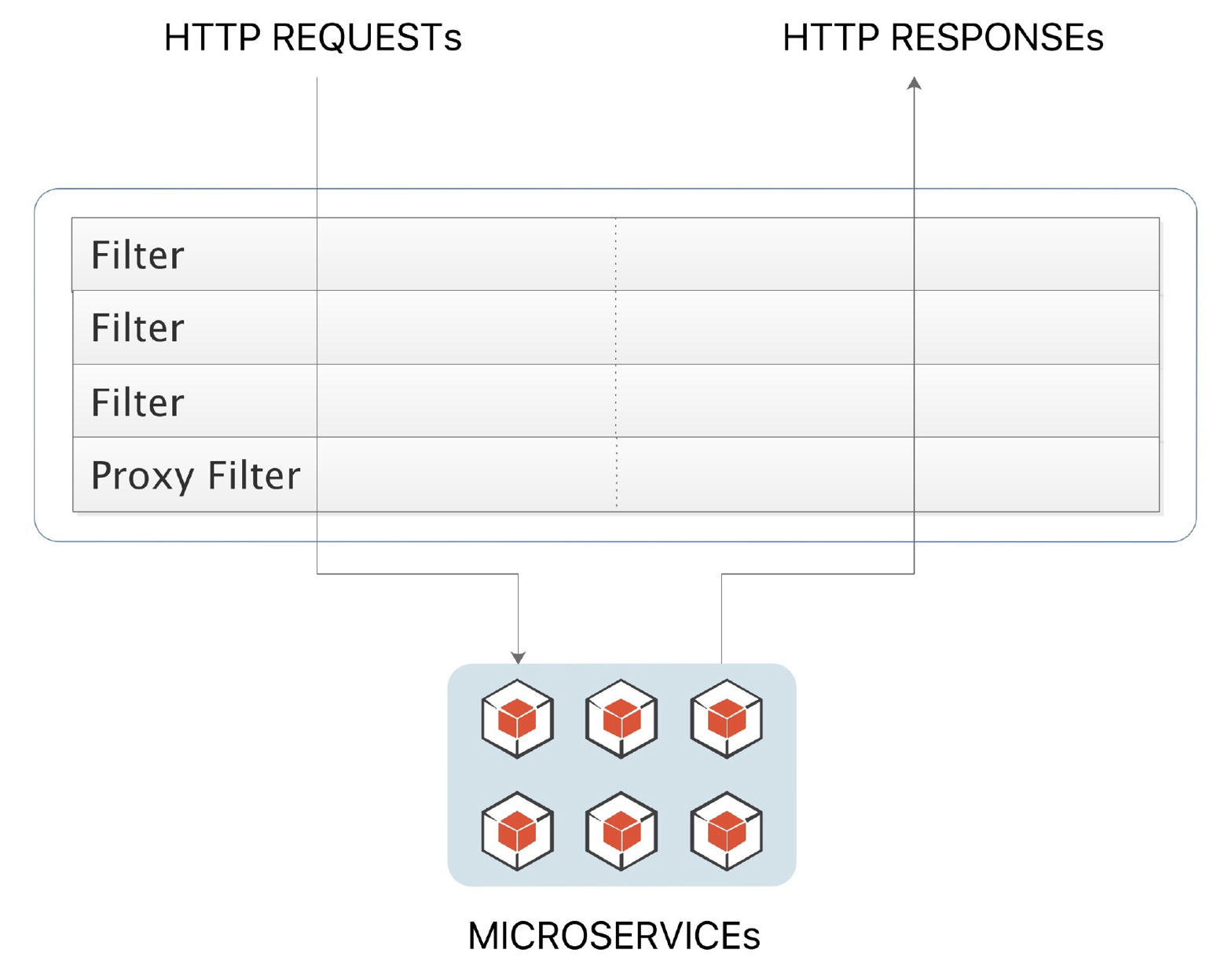
“pre”和 “post” 分别会在请求被执行前调用和被执行后调用,和 Zuul Filter 或 Spring Interceptor 中相关生命周期类似,但在形式上有些不同。
Zuul 的 Filter 是通过filterType()方法来指定,一个 Filter 只能对应一种类型,要么是 “pre” 要么是“post”。Spring Interceptor 是通过重写HandlerInterceptor中的三个方法来实现的。而 Spring Cloud Gateway 基于 Project Reactor 和 WebFlux,采用响应式编程风格,打开它的 Filter 的接口GatewayFilter你会发现它只有一个方法filter。
仅通过这一个方法,怎么来区分是 “pre” 还是 “post” 呢?我们下边就通过自定义过滤器来看看。
自定义过滤器
现在假设我们要统计gateway后每个服务的响应时间,我们不可能在每个方法的代码中加入耗时的计算。Spring 告诉我们有个东西叫 AOP。但是我们是微服务啊,在每个服务里都写也很烦。这时候就用到网关的过滤器了。
自定义过滤器需要实现GatewayFilter和Ordered。其中GatewayFilter中的这个方法就是用来实现你的自定义的逻辑的。
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.cloud.gateway.filter.GatewayFilter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.core.Ordered;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
public class ElapsedFilter implements GatewayFilter, Ordered {
private static final Log log = LogFactory.getLog(GatewayFilter.class);
private static final String ELAPSED_TIME_BEGIN = "elapsedTimeBegin";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
exchange.getAttributes().put(ELAPSED_TIME_BEGIN, System.currentTimeMillis());
return chain.filter(exchange).then(
Mono.fromRunnable(() -> {
Long startTime = exchange.getAttribute(ELAPSED_TIME_BEGIN);
if (startTime != null) {
log.info(exchange.getRequest().getURI().getRawPath() + ": " + (System.currentTimeMillis() - startTime) + "ms");
}
})
);
}
@Override
public int getOrder() {
return Ordered.LOWEST_PRECEDENCE;
}
}
我们在请求刚刚到达时,往ServerWebExchange中放入了一个属性elapsedTimeBegin,属性值为当时的毫秒级时间戳。然后在请求执行结束后,又从中取出我们之前放进去的那个时间戳,与当前时间的差值即为该请求的耗时。因为这是与业务无关的日志所以将Ordered设为Integer.MAX_VALUE以降低优先级。
现在再来看我们之前的问题:怎么来区分是 “pre” 还是 “post” 呢?其实就是chain.filter(exchange)之前的就是 “pre” 部分,之后的也就是then里边的是 “post” 部分。
创建好 Filter 之后我们将它添加到我们的 Filter Chain 里边
@Bean
public RouteLocator customerRouteLocator(RouteLocatorBuilder builder) {
// @formatter:off
return builder.routes()
.route(r -> r.path("/api/a/**")
.filters(f -> f.stripPrefix(2)
.filter(new ElapsedFilter()) .addResponseHeader("X-Response-Default-Foo", "Default-Bar"))
.uri("lb://business-a-woqu")
.order(0)
.id("business-a-woqu")
)
.build();
// @formatter:on
}
实际在使用 Spring Cloud 的过程中,我们会使用 Sleuth+Zipkin 来进行耗时等性能分析。
自定义全局过滤器
前边讲了自定义的过滤器,那个过滤器只是局部的,如果我们有多个路由就需要一个一个来配置,这显然是不符合实际的,因此我们需要用全局过滤器来实现。
全局过滤器只需要把实现的接口GatewayFilter换成GlobalFilter,就完事大吉了。比如我们需要在每个请求中获取header里的token来做用户权限娇艳,下面的 Demo 就是从请求header中获取Authentication字段,如果能获取到就 pass,获取不到就直接返回401错误,虽然简单,但足以说明问题了。
/**
* @author orrin on 2018/11/19
*/
@Configuration
public class TokenFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
List<String> tokens = exchange.getRequest().getHeaders().get("Authentication");
if (tokens != null && !tokens.isEmpty()) {
String token = tokens.get(0);
RequestPath requestPath = exchange.getRequest().getPath();
// todo 权限校验
}else {
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return -100;
}
}
官方说,未来的版本将对这个接口作出一些调整: This interface and usage are subject to change in future milestones. from Spring Cloud Gateway - Global Filters
自定义过滤器工厂
上一部分路由的文章中,我们在配置中有这么一段
filters:
- StripPrefix=1
StripPrefix实际上是个过滤器工厂(GatewayFilterFactory),用这种配置的方式更灵活方便。
我们就将之前的那个ElapsedFilter改造一下,让它能接收一个boolean类型的参数,来决定是否将请求参数也打印出来。
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.cloud.gateway.filter.GatewayFilter;
import org.springframework.cloud.gateway.filter.factory.AbstractGatewayFilterFactory;
import reactor.core.publisher.Mono;
import java.util.Arrays;
import java.util.List;
@Configuration
public class ElapsedGatewayFilterFactory extends AbstractGatewayFilterFactory<ElapsedGatewayFilterFactory.Config> {
private static final Log log = LogFactory.getLog(GatewayFilter.class);
private static final String ELAPSED_TIME_BEGIN = "elapsedTimeBegin";
private static final String KEY = "withParams";
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList(KEY);
}
public ElapsedGatewayFilterFactory() {
super(Config.class);
}
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
exchange.getAttributes().put(ELAPSED_TIME_BEGIN, System.currentTimeMillis());
return chain.filter(exchange).then(
Mono.fromRunnable(() -> {
Long startTime = exchange.getAttribute(ELAPSED_TIME_BEGIN);
if (startTime != null) {
StringBuilder sb = new StringBuilder(exchange.getRequest().getURI().getRawPath())
.append(": ")
.append(System.currentTimeMillis() - startTime)
.append("ms");
if (config.isWithParams()) {
sb.append(" params:").append(exchange.getRequest().getQueryParams());
}
log.info(sb.toString());
}
})
);
};
}
public static class Config {
private boolean withParams;
public boolean isWithParams() {
return withParams;
}
public void setWithParams(boolean withParams) {
this.withParams = withParams;
}
}
}
过滤器工厂的顶级接口是GatewayFilterFactory,我们可以直接继承它的两个抽象类来简化开发AbstractGatewayFilterFactory和AbstractNameValueGatewayFilterFactory,这两个抽象类的区别就是前者接收一个参数(像StripPrefix和我们创建的这种),后者接收两个参数(像AddResponseHeader)。 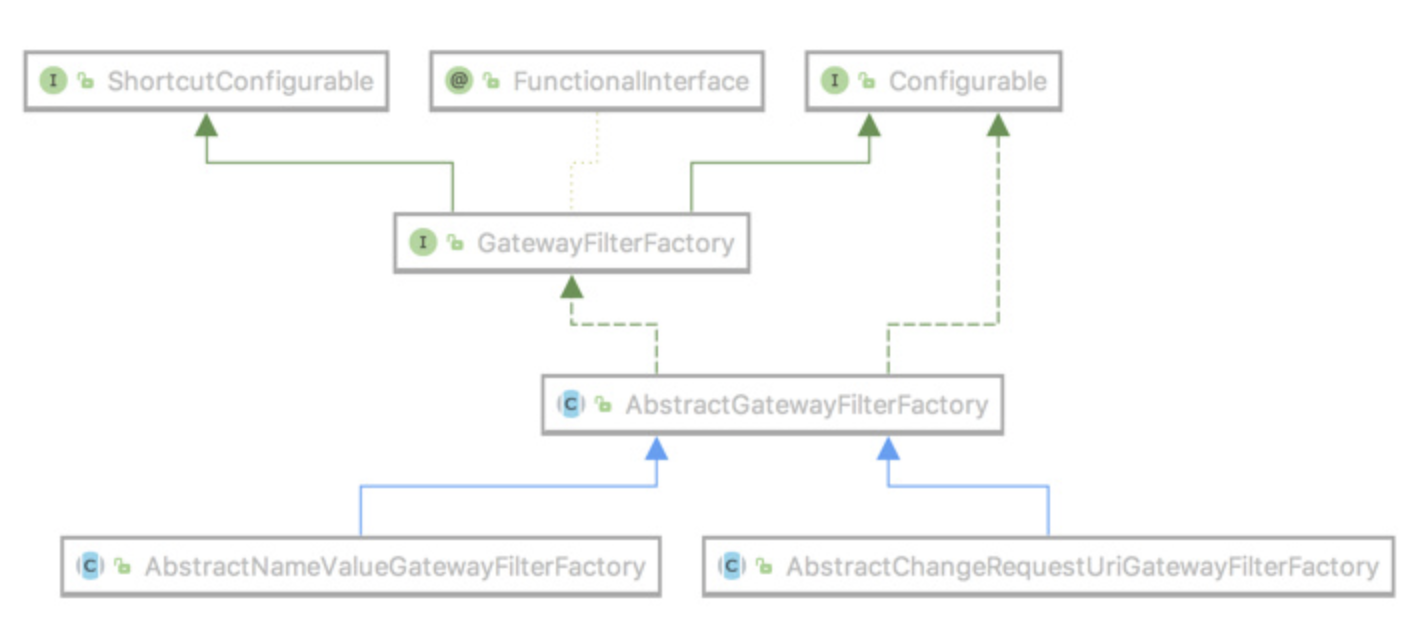
GatewayFilter apply(Config config)方法内部实际上是创建了一个GatewayFilter的匿名类,具体实现和之前的几乎一样
静态内部类Config就是为了接收那个boolean类型的参数服务的,里边的变量名可以随意写,但是要重写List<String> shortcutFieldOrder()这个方法。
这里注意一下,一定要调用一下父类的构造器把Config类型传过去,否则会报ClassCastException
public ElapsedGatewayFilterFactory() {
super(Config.class);
}
修改application.yml 配置文件内容如下
spring:
application:
name: common-server-gateway
cloud:
consul:
host: woqu.consul
port: 8500
discovery:
instance-id: ${spring.application.name}
instance-group: ${spring.application.name}
register: true
service-name: ${spring.application.name}
gateway:
discovery:
locator:
enabled: true
default-filters:
- Elapsed=true
routes:
- id: business-a-woqu
uri: lb://business-a-woqu
order: 10000
predicates:
- Path=/api/a/**
- StripPrefix=2
server:
port: 7001
logging:
level:
org.springframework.cloud.gateway: debug
限流
在高并发的应用中,限流是一个绕不开的话题。限流可以保障我们的 API 服务对所有用户的可用性,也可以防止网络攻击。
一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池、线程池)、限制瞬时并发数(如 nginx 的 limit_conn 模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如 Guava 的 RateLimiter、nginx 的 limit_req 模块,限制每秒的平均速率);其他还有如限制远程接口调用速率、限制 MQ 的消费速率。另外还可以根据网络连接数、网络流量、CPU 或内存负载等来限流。
限流算法
做限流 (Rate Limiting/Throttling) 的时候,除了简单的控制并发,如果要准确的控制 TPS,简单的做法是维护一个单位时间内的 Counter,如判断单位时间已经过去,则将 Counter 重置零。此做法被认为没有很好的处理单位时间的边界,比如在前一秒的最后一毫秒里和下一秒的第一毫秒都触发了最大的请求数,也就是在两毫秒内发生了两倍的 TPS。
常用的更平滑的限流算法有两种:漏桶算法和令牌桶算法。
-
漏桶算法
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。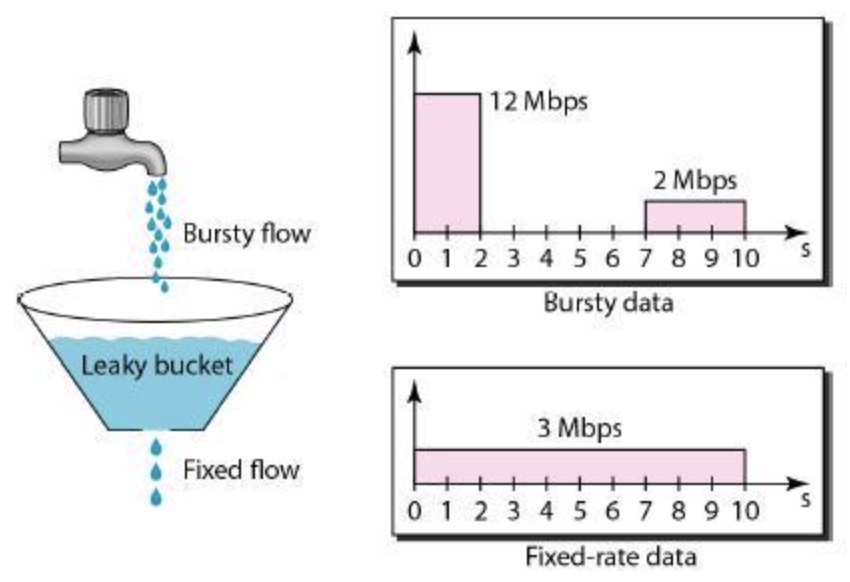
可见这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。 -
令牌桶算法
令牌桶算法(Token Bucket)和 Leaky Bucket 效果一样但方向相反的算法,更加容易理解。随着时间流逝,系统会按恒定 1/QPS 时间间隔(如果 QPS=100,则间隔是 10ms)往桶里加入 Token(想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了。新请求来临时,会各自拿走一个 Token,如果没有 Token 可拿了就阻塞或者拒绝服务。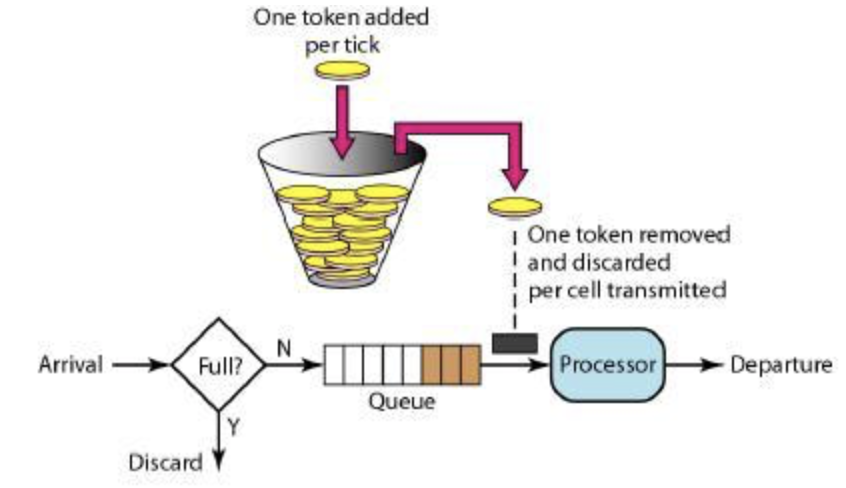
令牌桶的另外一个好处是可以方便的改变速度。一旦需要提高速率,则按需提高放入桶中的令牌的速率。一般会定时(比如 100 毫秒)往桶中增加一定数量的令牌,有些变种算法则实时的计算应该增加的令牌的数量。
Leakly Bucket vs Token Bucket
| 对比项 | Leakly bucket | Token bucket | Token bucket 的备注 |
|---|---|---|---|
| 依赖 token | 否 | 是 | |
| 立即执行 | 是 | 否 | 有足够的 token 才能执行 |
| 堆积 token | 否 | 是 | |
| 速率恒定 | 是 | 否 | 可以大于设定的 QPS |
限流实现
在 Gateway 上实现限流是个不错的选择,只需要编写一个过滤器就可以了。有了前边过滤器的基础,写起来很轻松。
我们这里采用令牌桶算法,Google Guava 的RateLimiter、Bucket4j、RateLimitJ 都是一些基于此算法的实现,只是他们支持的 back-ends(JCache、Hazelcast、Redis 等)不同罢了,你可以根据自己的技术栈选择相应的实现。
这里我们使用 Bucket4j,引入它的依赖坐标,为了方便顺便引入 Lombok
<dependency>
<groupId>com.github.vladimir-bukhtoyarov</groupId>
<artifactId>bucket4j-core</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
<scope>provided</scope>
</dependency>
@CommonsLog
@Builder
@Data
@AllArgsConstructor
@NoArgsConstructor
public class RateLimitByIpGatewayFilter implements GatewayFilter,Ordered {
int capacity;
int refillTokens;
Duration refillDuration;
private static final Map<String,Bucket> CACHE = new ConcurrentHashMap<>();
private Bucket createNewBucket() {
Refill refill = Refill.of(refillTokens,refillDuration);
Bandwidth limit = Bandwidth.classic(capacity,refill);
return Bucket4j.builder().addLimit(limit).build();
}
@Override
public Mono<Void> filter(ServerWebExchange exchange,GatewayFilterChain chain) {
// if (!enableRateLimit){
// return chain.filter(exchange);
// }
String ip = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress();
Bucket bucket = CACHE.computeIfAbsent(ip,k -> createNewBucket());
log.debug("IP: " + ip + ",TokenBucket Available Tokens: " + bucket.getAvailableTokens());
if (bucket.tryConsume(1)) {
return chain.filter(exchange);
} else {
exchange.getResponse().setStatusCode(HttpStatus.TOO_MANY_REQUESTS);
return exchange.getResponse().setComplete();
}
}
@Override
public int getOrder() {
return -1000;
}
}
通过对令牌桶算法的了解,需要定义三个变量:
- capacity:桶的最大容量,即能装载 Token 的最大数量
- refillTokens:每次 Token 补充量
- refillDuration:补充 Token 的时间间隔
在这个实现中,我们使用了 IP 来进行限制,当达到最大流量就返回429错误。这里我们简单使用一个 Map 来存储 bucket,所以也决定了它只能单点使用,如果是分布式的话,可以采用 Hazelcast 或 Redis 等解决方案。
在 Route 中我们添加这个过滤器,这里指定了 bucket 的容量为 10 且每一秒会补充 1 个 Token。
@Bean
public RouteLocator customerRouteLocator(RouteLocatorBuilder builder) {
// @formatter:off
return builder.routes()
.route(r -> r.path("/api/a/**")
.filters(f -> f.stripPrefix(2)
.filter(new RateLimitByIpGatewayFilter(10,1,Duration.ofSeconds(1)))) .addResponseHeader("X-Response-Default-Foo", "Default-Bar"))
.uri("lb://business-a-woqu")
.order(0)
.id("business-a-woqu")
)
.build();
// @formatter:on
}
RequestRateLimiter
刚刚我们通过过滤器实现了限流的功能,你可能在想为什么不直接创建一个过滤器工厂呢,那样多方便。这是因为 Spring Cloud Gateway 已经内置了一个RequestRateLimiterGatewayFilterFactory,我们可以直接使用(这里有坑,后边详说)。
目前RequestRateLimiterGatewayFilterFactory的实现依赖于 Redis,所以我们还要引入spring-boot-starter-data-redis-reactive
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
修改application.yml 配置文件内容如下,新增的部分我已经用# ---标出来了
spring:
application:
name: common-server-gateway
cloud:
consul:
host: woqu.consul
port: 8500
discovery:
instance-id: ${spring.application.name}
instance-group: ${spring.application.name}
register: true
service-name: ${spring.application.name}
gateway:
discovery:
locator:
enabled: true
default-filters:
- Elapsed=true
routes:
- id: business-a-woqu
uri: lb://business-a-woqu
order: 10000
predicates:
- Path=/api/a/**
- StripPrefix=2
# -------
- name: RequestRateLimiter
args:
key-resolver: '#{@remoteAddrKeyResolver}'
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 5
# -------
# -------
redis:
host: localhost
port: 6379
database: 0
# -------
server:
port: 7001
logging:
level:
org.springframework.cloud.gateway: debug
com.windmt.filter: debug
默认情况下,是基于令牌桶算法实现的限流,有个三个参数需要配置:
- burstCapacity,令牌桶容量。
- replenishRate,令牌桶每秒填充平均速率。
- key-resolver,用于限流的键的解析器的 Bean 对象名字(有些绕,看代码吧)。它使用 SpEL 表达式根据#{@beanName}从 Spring 容器中获取 Bean 对象。默认情况下,使用PrincipalNameKeyResolver,以请求认证的java.security.Principal作为限流键。
我们实现一个使用请求 IP 作为限流键的KeyResolver
public class RemoteAddrKeyResolver implements KeyResolver {
public static final String BEAN_NAME = "remoteAddrKeyResolver";
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
return Mono.just(exchange.getRequest().getRemoteAddress().getAddress().getHostAddress());
}
}
配置RemoteAddrKeyResolver Bean 对象
@Bean(name = RemoteAddrKeyResolver.BEAN_NAME)
public RemoteAddrKeyResolver remoteAddrKeyResolver() {
return new RemoteAddrKeyResolver();
}
可以正常启动测试了
基于系统负载的动态限流
在实际工作中,我们可能还需要根据网络连接数、网络流量、CPU 或内存负载等来进行动态限流。在这里我们以 CPU利用率 为例子。
我们需要借助 Spring Boot Actuator 提供的 Metrics 能力进行实现基于 CPU 的限流——当 CPU 使用率高于某个阈值就开启限流,否则不开启限流。
我们在项目中引入 Actuator 的依赖坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
Spring Boot 2.x 之后,Actuator 被重新设计了,和 1.x 的区别还是挺大的(参考这里)。我们先在配置中设置management.endpoints.web.exposure.include=*来观察一下新的 Metrics 的能力
http://localhost:7001/actuator/metrics
{
"names": [
"jvm.buffer.memory.used",
"jvm.memory.used",
"jvm.buffer.count",
"jvm.gc.memory.allocated",
"logback.events",
"process.uptime",
"jvm.memory.committed",
"system.load.average.1m",
"jvm.gc.pause",
"jvm.gc.max.data.size",
"jvm.buffer.total.capacity",
"jvm.memory.max",
"system.cpu.count",
"system.cpu.usage",
"process.files.max",
"jvm.threads.daemon",
"http.server.requests",
"jvm.threads.live",
"process.start.time",
"jvm.classes.loaded",
"jvm.classes.unloaded",
"jvm.threads.peak",
"jvm.gc.live.data.size",
"jvm.gc.memory.promoted",
"process.files.open",
"process.cpu.usage"
]
}
我们可以利用里边的系统 CPU 使用率system.cpu.usage
http://localhost:7001/actuator/metrics/system.cpu.usage
{
"name": "system.cpu.usage",
"measurements": [
{
"statistic": "VALUE",
"value": 0.5189003436426117
}
],
"availableTags": []
}
最近一分钟内的平均负载system.load.average.1m也是一样的
http://localhost:7001/actuator/metrics/system.load.average.1m
{
"name": "system.load.average.1m",
"measurements": [
{
"statistic": "VALUE",
"value": 5.33203125
}
],
"availableTags": []
}
知道了 Metrics 提供的指标,我们就来看在代码里具体怎么实现吧。Actuator 2.x 里边已经没有了之前 1.x 里边提供的SystemPublicMetrics,但是经过阅读源码可以发现MetricsEndpoint这个类可以提供类似的功能。
@CommonsLog
@Component
public class RateLimitByCpuGatewayFilter implements GatewayFilter, Ordered {
@Autowired
private MetricsEndpoint metricsEndpoint;
private static final String METRIC_NAME = "system.cpu.usage";
private static final double MAX_USAGE = 0.50D;
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// if (!enableRateLimit){
// return chain.filter(exchange);
// }
Double systemCpuUsage = metricsEndpoint.metric(METRIC_NAME, null)
.getMeasurements()
.stream()
.filter(Objects::nonNull)
.findFirst()
.map(MetricsEndpoint.Sample::getValue)
.filter(Double::isFinite)
.orElse(0.0D);
boolean ok = systemCpuUsage < MAX_USAGE;
log.debug("system.cpu.usage: " + systemCpuUsage + " ok: " + ok);
if (!ok) {
exchange.getResponse().setStatusCode(HttpStatus.TOO_MANY_REQUESTS);
return exchange.getResponse().setComplete();
} else {
return chain.filter(exchange);
}
}
@Override
public int getOrder() {
return 0;
}
}
配置 Route
@Autowired
private RateLimitByCpuGatewayFilter rateLimitByCpuGatewayFilter;
@Bean
public RouteLocator customerRouteLocator(RouteLocatorBuilder builder) {
// @formatter:off
return builder.routes()
.route(r -> r.path("/api/a/**")
.filters(f -> f.stripPrefix(2)
.filter(rateLimitByCpuGatewayFilter) .addResponseHeader("X-Response-Default-Foo", "Default-Bar"))
.uri("lb://business-a-woqu")
.order(0)
.id("business-a-woqu")
)
.build();
// @formatter:on
}
因为 CPU 的使用率一般波动较大,测试效果还是挺明显的,实际使用就得慎重了,可以使用内存使用率来代替。
高可用
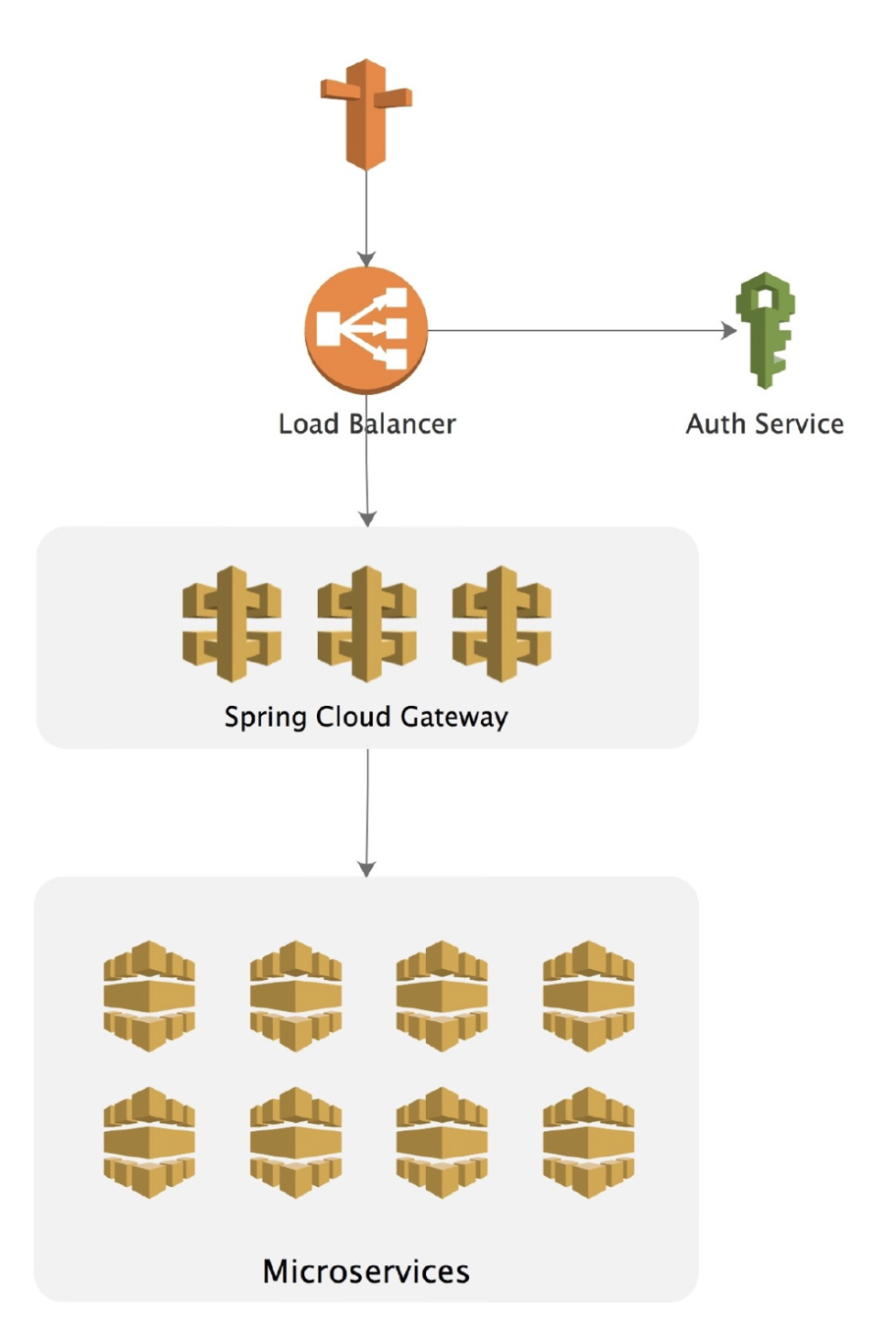
我们实际使用 Spring Cloud Gateway 的方式如上图,不同的客户端使用不同的负载将请求分发到后端的 Gateway,Gateway 再通过Consul调用后端服务,最后对外输出。因此为了保证 Gateway 的高可用性,前端可以同时启动多个 Gateway 实例进行负载,在 Gateway 的前端使用 Nginx 或者 F5 进行负载转发以达到高可用性。















 5074
5074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









