







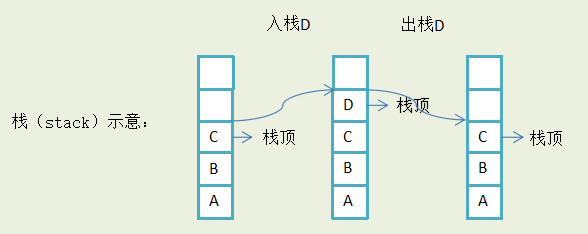
一、栈简介
栈是一种用于存数数据的简单数据结构(与链表类似)。数据入栈的次序是栈的关键。可以把自助残定中的一堆盘子看作一个栈的例子。当盘子洗干净后,他们会添加到栈的顶端。当需要盘子時,也是从栈的顶端拿取。所以第一个放入栈中的盘子最后才能被拿取。
定义:栈(stack)是一个有序线性表,只能在表的一端(称为栈顶,top)执行插入和删除操作。最后插入的元素将第一个被删除。所以,栈也称为后进先出(Last In First Out,LIFO)或先进后出(First In Last Out, FILO)线性表。
两个改变栈操作都有专用名称。一个称为入栈(push),表示在栈中插入一个元素;另一个称为出栈(pop),表示从栈中删除一个元素。试图对一个空栈执行出栈操作称为下一溢;视图对一个满栈执行入栈操作称为溢出。通常,溢出和下溢均认为是异常。
二、源码分析
jdk1.8源码分析栈(stack),图解如下:
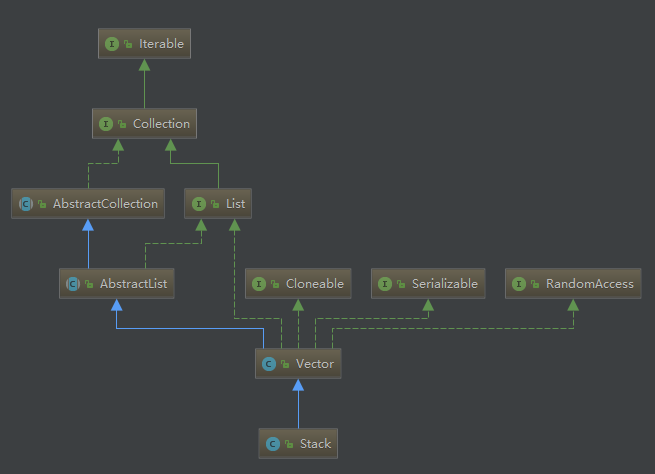
Stack类里的方法:
public Stack() //一个无参构造方法,能直接创建一个Stack
public E push(E var1)//向栈顶压入一个项
public synchronized E pop()//移走栈顶对象,将该对象作为函数值返回
public synchronized E peek()//查找栈顶对象,而不从栈中移走
public boolean empty()//测试栈是否为空
public synchronized int search(Object var1)//返回栈中对象的位置,从1开始其他值的方法是从Vector类继承而来,通过源码可以发现Vector有几个属性值
protected Object[] elementData //用于保存Stack中的每个元素;
protected int elementCount //用于动态的保存元素的个数,即实际元素个数
protected int capacityIncrement //capacityIncrement用来保存Stack的容量(一般情况下应该是大于elementCount)通过这几属性我们可以发现,Stack底层是采用数组来实现的。
1、public E push(E var1)//向栈顶压入一个项
public E push(E var1) {
//调用Vector类的添加元素方法
this.addElement(var1);
return var1;
}
public synchronized void addElement(E var1) {
//通过记录modCount参数来实现Fail-Fast机制
++this.modCount;
//确保栈的容量大小不会使新增的数据溢出
this.ensureCapacityHelper(this.elementCount + 1);
this.elementData[this.elementCount++] = var1;
}
private void ensureCapacityHelper(int var1) {
//防止溢出。超出了数组可容纳的长度,需要进行动态扩展!!
if (var1 - this.elementData.length > 0) {
this.grow(var1);
}
}
private void grow(int var1) {
int var2 = this.elementData.length;
//如果超出数组容量,数组扩展为原来的两倍
int var3 = var2 + (this.capacityIncrement > 0 ? this.capacityIncrement : var2);
if (var3 - var1 < 0) {
var3 = var1;
}
//如果大,则var3 过大,需要判断下
if (var3 - 2147483639 > 0) {
var3 = hugeCapacity(var1);
}
this.elementData = Arrays.copyOf(this.elementData, var3);
}
//检查容量的int值是不是已经溢出
private static int hugeCapacity(int var0) {
if (var0 < 0) {
throw new OutOfMemoryError();
} else {
return var0 > 2147483639 ? 2147483647 : 2147483639;
}
}2、public synchronized E pop()//移走栈顶对象,将该对象作为函数值返回
public synchronized E pop() {
int var2 = this.size();
Object var1 = this.peek();
//len-1的得到值就是数组最后一个数的下标
this.removeElementAt(var2 - 1);
return var1;
}
//Vector里的方法
public synchronized void removeElementAt(int var1) {
++this.modCount;
//数组下标越界异常出现的情况
if (var1 >= this.elementCount) {
throw new ArrayIndexOutOfBoundsException(var1 + " >= " + this.elementCount);
} else if (var1 < 0) {
throw new ArrayIndexOutOfBoundsException(var1);
} else {
//数组中index以后的元素个数,由于Stack调用的该方法,var2始终为0
int var2 = this.elementCount - var1 - 1;
if (var2 > 0) {
// 数组中index以后的元素,整体前移,(这个方法挺有用的!!)
System.arraycopy(this.elementData, var1 + 1, this.elementData, var1, var2);
}
--this.elementCount;
this.elementData[this.elementCount] = null;
}
}3、public synchronized E peek()//查找栈顶对象,而不从栈中移走
public synchronized E peek() {
int var1 = this.size();
if (var1 == 0) {
throw new EmptyStackException();
} else {
return this.elementAt(var1 - 1);
}
}
//Vector里的方法,获取实际栈里的元素个数
public synchronized int size() {
return this.elementCount;
}
public synchronized E elementAt(int var1) {
if (var1 >= this.elementCount) {
//数组下标越界异常
throw new ArrayIndexOutOfBoundsException(var1 + " >= " + this.elementCount);
} else {
//返回数据下标为index的值
return this.elementData(var1);
}
}
E elementData(int var1) {
return this.elementData[var1];
}4、public boolean empty()//测试栈是否为空
public boolean empty() {
return this.size() == 0;
}5、public synchronized int search(Object var1)//返回栈中对象的位置,从1开始
//栈中最顶部的项被认为距离为1
public synchronized int search(Object var1) {
//lastIndexOf返回一个指定的字符串值最后出现的位置,
//在一个字符串中的指定位置从后向前搜索
int var2 = this.lastIndexOf(var1);
//所以离栈顶最近的距离需要相减
return var2 >= 0 ? this.size() - var2 : -1;
}
public synchronized int lastIndexOf(Object var1) {
return this.lastIndexOf(var1, this.elementCount - 1);
}
public synchronized int lastIndexOf(Object var1, int var2) {
if (var2 >= this.elementCount) {
throw new IndexOutOfBoundsException(var2 + " >= " + this.elementCount);
} else {
int var3;
//Vector、Stack里可以放null数据
if (var1 == null) {
for(var3 = var2; var3 >= 0; --var3) {
if (this.elementData[var3] == null) {
return var3;
}
}
} else {
for(var3 = var2; var3 >= 0; --var3) {
if (var1.equals(this.elementData[var3])) {
return var3;
}
}
}
return -1;
}
}三、栈的应用
- 直接应用
- 符号匹配
- 中缀表达式转换为后缀表达式
- 计算后缀表达式
- 实现函数调用(包括递归)
- 求范围误差(极差)
- 网页浏览器中已访问页面的历史记录(后退back按钮)
- 文本编辑器中的撤销序列
- HTML和XML文件中的标签(tag)匹配
- 间接应用
- 算法的辅助数据结构(例如:树遍历算法)
- 其他数据结构的组件(例如:模拟队列)
四、栈的实现
1、简单数据实现
从左至右向数组中添加所有的元素,并定义一个变量用来记录数组当前栈顶(top)元素的下标。
public class stacktest {
private int top;
private int capacity;
private int[] array;
public stacktest(){
capacity = 3;
array = new int[capacity];
top = -1;
}
public boolean isEempty(){
return (top == -1);
}
public boolean isStackFull(){
return (top == capacity - 1);
}
public void push(int data){
if (isStackFull())
System.out.println("stack overflow");
else
array[++top] = data;
}
public int pop(){
if (isEempty()){
System.out.println("Stack is Eempty");
return 0;
}
else return (array[top--]);
}
public void deleteStack(){
top = -1;
}
public int getsize(){
return array.length;
}
public void gettostring(){
for (int i = 0; i < array.length; i++) {
System.out.print(array[i]+",");
}
}
public static void main(String[] args) {
stacktest stacktest = new stacktest();
stacktest.push(5);
stacktest.push(2);
stacktest.push(3);
// System.out.println(stacktest.getsize());
System.out.println("\n");
stacktest.gettostring();
System.out.println(stacktest.isStackFull()+"\n");
stacktest.gettostring();
System.out.println(stacktest.pop()+"\n");
stacktest.gettostring();
System.out.println(stacktest.isEempty());
System.out.println(stacktest.isStackFull());
// stacktest.deleteStack();
System.out.println("\n");
stacktest.gettostring();
}
}性能:假设N为栈中元素的个数。在局域简单数组的栈实现中,各种栈操作的算法复杂度如下所示。
| 空间复杂度(用于n次push操作) | O(n) | isEempty()的时间复杂度 | O(1) |
| push()的时间复杂度 | O(1) | isStackFull()的时间复杂度 | O(1) |
| pop()的时间复杂度 | O(1) | deleteStack()的时间复杂度 | O(1) |
| size()的时间复杂度 | O(1) | O(1) |
局限性:栈的最大空间必须预先声明且不能改变。视图对一个满栈执行入栈操作将产生一个针对简单数组这种特定实现栈方式的异常。
2、动态数组实现
可以使用数组倍增技术来提高性能。如果数组空间已满,新建一个比原数组空间大一倍的新数组,然后复制元素。代码就不提供了,可参考Vector空间扩容。
3、链表实现
了解完顺序栈,我们接着来看看链式栈,所谓的链式栈(Linked Stack),就是采用链式存储结构的栈,由于我们操作的是栈顶一端,因此这里采用单链表(不带头结点)作为基础,直接实现栈的添加,获取,删除等主要操作即可。其操作过程如下图:
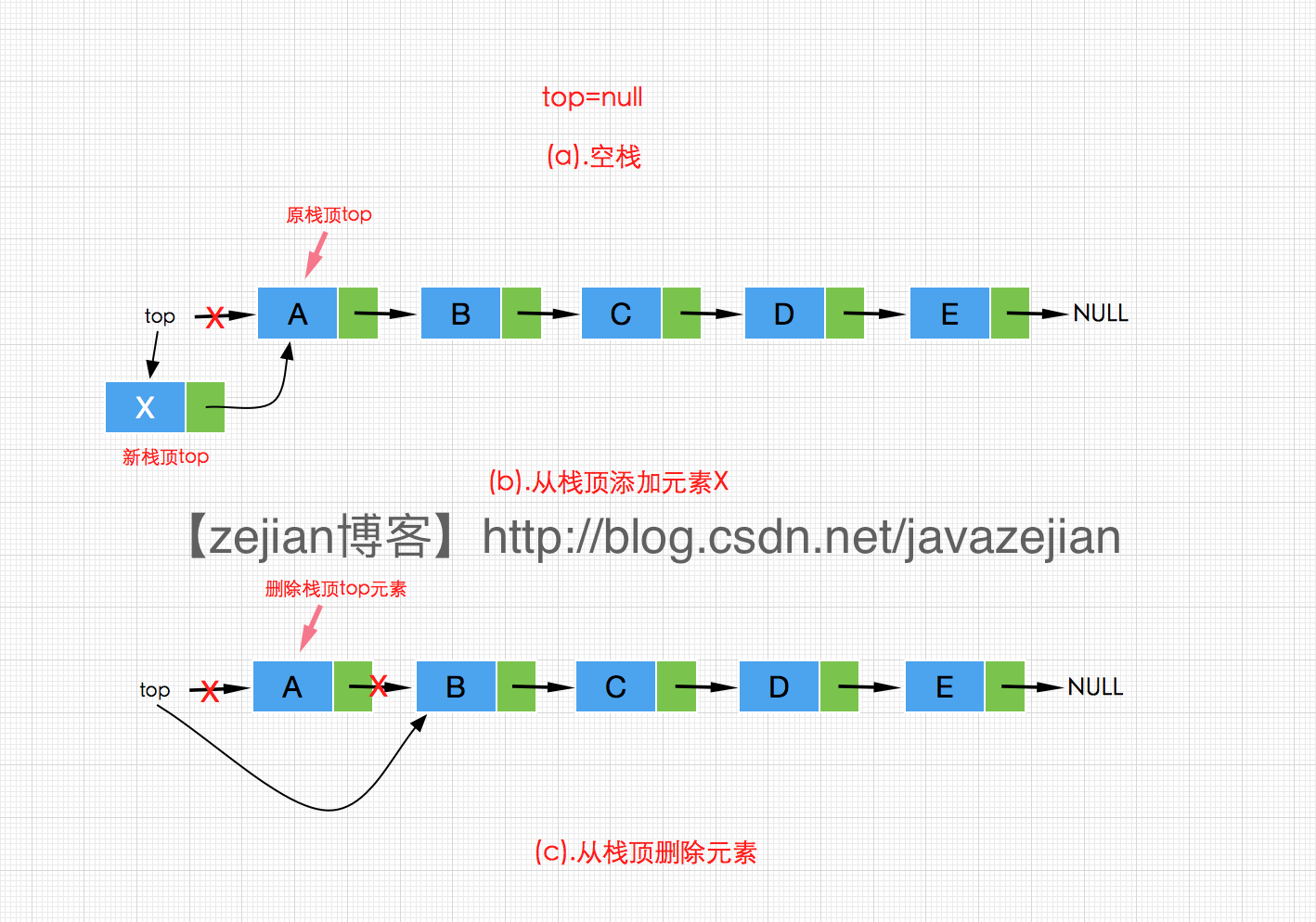
从图可以看出,无论是插入还是删除直接操作的是链表头部也就是栈顶元素,因此我们只需要使用不带头结点的单链表即可。代码实现如下,比较简单,不过多分析了:
package com.zejian.structures.Stack;
import com.zejian.structures.LinkedList.singleLinked.Node;
import java.io.Serializable;
public class LinkedStack<T> implements Stack<T> ,Serializable{
private static final long serialVersionUID = 1911829302658328353L;
private Node<T> top;
private int size;
public LinkedStack(){
this.top=new Node<>();
}
public int size(){
return size;
}
@Override
public boolean isEmpty() {
return top==null || top.data==null;
}
@Override
public void push(T data) {
if (data==null){
throw new StackException("data can\'t be null");
}
if(this.top==null){//调用pop()后top可能为null
this.top=new Node<>(data);
}else if(this.top.data==null){
this.top.data=data;
}else {
Node<T> p=new Node<>(data,this.top);
top=p;//更新栈顶
}
size++;
}
@Override
public T peek() {
if(isEmpty()){
throw new EmptyStackException("Stack empty");
}
return top.data;
}
@Override
public T pop() {
if(isEmpty()){
throw new EmptyStackException("Stack empty");
}
T data=top.data;
top=top.next;
size--;
return data;
}
//测试
public static void main(String[] args){
LinkedStack<String> sl=new LinkedStack<>();
sl.push("A");
sl.push("B");
sl.push("C");
int length=sl.size();
for (int i = 0; i < length; i++) {
System.out.println("sl.pop->"+sl.pop());
}
}
}最后我们来看看顺序栈与链式栈中各个操作的算法复杂度(时间和空间)对比,顺序栈复杂
| 空间复杂度(用于n次push操作) | O(n) | top()的时间复杂度 | O(1) |
| LinkedStack()的时间复杂度(创建栈) | O(1) | isEempty()的时间复杂度 | O(1) |
| push()的时间复杂度 | O(1)(平均) | deleteStack()的时间复杂度 | O(n) |
| pop()的时间复杂度 | O(1) |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









