







1. 如果kernel版本<2.6.33,且将journal存储于一块单独的硬盘上,需要关闭写缓存:
sudo hdparm -W 0 /dev/hda 02. osd daemon依赖Extended Attributes (XATTRs)存储内部对象状态和元数据,
You should always add the following line to the[osd]section of yourceph.conffile for ext4 file systems; you can optionally use it for btrfs and XFS.:
filestore xattr use omap = true[global]
Description: Settings under [global] affect all daemons in a Ceph Storage Cluster.
Example: auth supported = cephx
[osd]
Description: Settings under [osd] affect all ceph-osd daemons in the Ceph Storage Cluster, and override the same setting in [global].
Example: osd journal size = 1000
[mon]
Description: Settings under [mon] affect all ceph-mon daemons in the Ceph Storage Cluster, and override the same setting in [global].
Example: mon addr = 10.0.0.101:6789
[mds]
Description: Settings under [mds] affect all ceph-mds daemons in the Ceph Storage Cluster, and override the same setting in [global].
Example: host = myserver01
[client]
Description: Settings under [client] affect all Ceph Clients (e.g., mounted Ceph Filesystems, mounted Ceph Block Devices, etc.).
Example: log file = /var/log/ceph/radosgw.log[global]
#Enable authentication between hosts within the cluster.
#v 0.54 and earlier
auth supported = cephx
#v 0.55 and after
auth cluster required = cephx
auth service required = cephx
auth client required = cephx[global]
auth cluster required = none
auth service required = none
auth client required = none
auth supported = none/var/run/ceph/$cluster-$name.asokceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show | less 1. a public (front-side) network and a cluster (back-side) networ:

2. osd至少需要3个端口
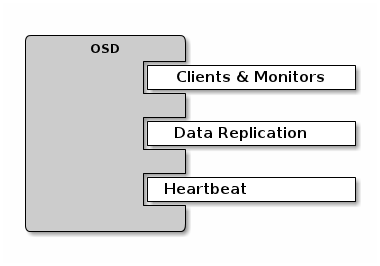
3. 内外网配置
外网:
[global]
...
public network = {public-network/netmask}[global]
...
cluster network = {cluster-network/netmask}4. 每个daemon必须设置主机名
[mon.a]
host = {hostname}
mon addr = {ip-address}:6789
[osd.0]
host = {hostname}
[osd.0]
public addr = {host-public-ip-address}
cluster addr = {host-cluster-ip-address}1. Ceph Monitors maintain a “master copy” of the cluster map, which means a Ceph Client can determine the location of all Ceph Monitors, Ceph OSD Daemons, and Ceph Metadata Servers just by connecting to one Ceph Monitor and retrieving a current cluster map.
ceph客户端首先会链接ceph monitor,拷贝一份cluster map and the CRUSH algorithm,然后在本地就可以计算出每一个object的位置了,这也是ceph的可扩展性和高效的体现。
The primary role of the Ceph Monitor is to maintain a master copy of the cluster map. Ceph Monitors also provide authentication and logging services. Ceph Monitors write all changes in the monitor services to a single Paxos instance, and Paxos writes the changes to a key/value store for strong consistency. Ceph Monitors can query the most recent version of the cluster map during sync operations. Ceph Monitors leverage the key/value store’s snapshots and iterators (using leveldb) to perform store-wide synchronization.
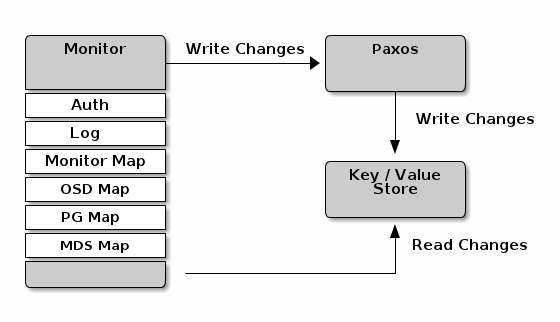
2. Cluster Maps
The cluster map is a composite of maps, including the monitor map, the OSD map, the placement group map and the metadata server map.
[global] [mon] [mon.a] [mon.b] [mon.c][mon] mon host = hostname1,hostname2,hostname3 mon addr = 10.0.0.10:6789,10.0.0.11:6789,10.0.0.12:6789[mon.a] host = hostname1 mon addr = 10.0.0.10:6789我们建议在生产环境下最少部署 3 个监视器,以确保高可用性。运行多个监视器时,你可以指定为形成法定人数成员所需的初始监视器,这能减小集群上线时间。
[mon] mon initial members = a,b,c 利用ceph-deploy安装后已经被设置好:
[root@mon0 ceph]# ceph --admin-daemon /var/run/ceph/ceph-mon.mon0.asok config show|grep mon_initial_members
"mon_initial_members": "mon0, osd1, osd2",
ceph 集群利用率接近最大容量时(如 mon osd full ratio),作为防止数据丢失的安全措施,它会阻止你读写OSD。因此,让生产集群用满可不是好事,因为牺牲了高可用性。full ratio 默认值是.95 或容量的 95%。对小
型测试集群来说这是非常激进的设置。
[global] mon osd full ratio = .80 mon osd nearfull ratio = .70
leader 可以给 provider 委派同步任务,这会避免同步请求压垮 leader、影响性能。在下面的图示中,requester 已经知道它落后于其它监视器,然后向 leader 请求同步,leader 让它去和 provider 同步。

新监视器加入集群时总要同步。在运行中,监视器会不定时收到集群运行图的更新,这就意味着 leader 和provider 角色可能在监视器间漂移。如果这事发生在同步期间(如 provider 落后于 leader),provider 能终结
和 requester 间的同步。
各 OSD 每 6 秒会与其他 OSD 进行心跳检查,用[osd]下的 osd heartbeat interval 可更改此间隔、或运行时更改。如果一个 OSD 20 秒都没有心跳,集群就认为它 down 了,用[osd]下的 osd heartbeat grace 可更改宽限期、或者运行时更改。

默认情况下,一个 OSD 必须向监视器报告三次另一个 OSD down 的消息,监视器才会认为那个被报告的 OSDdown 了;配置文件里[mon]段下的 mon osd min down reports 选项(v0.62 之前是 osd min down reports)可更改这个最少 osd down 消息次数,或者运行时设置。默认情况下,只要有一个 OSD 报告另一个 OSD 挂的消息即可,配置文件里[mon]段下的 mon osd min down reporters 可用来更改必需 OSD 数(v0.62 之前的 osd min downreporters),或者运行时更改。
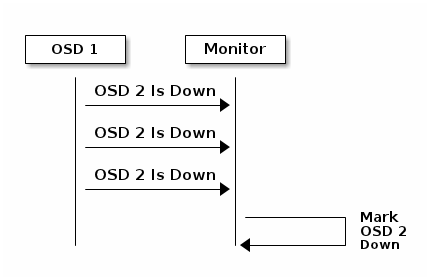
实际环境中我配置了mon osd down out interval = 1800(在osd停止响应多少秒后把它标记为down,默认300),手动停止一个osd,等待了1802秒后,ceph开始迁移数据。
如果一 OSD 至少 120 秒没向监视器报告过,监视器就认为它 down 了,你可以设置[osd]下的 osd mon reportinterval max 来更改此报告间隔,或者运行时更改。OSD 每 30 秒会报告它自己的状态,在[osd]段下设置 osd mon report interval min 可更改 OSD 报告间隔,或运行时更改。

OSD Settings
可以在配置文件里配置 OSD,但它可以用默认值和最小化配置。最简 OSD 配置需设置 osd journal size 和osd host,其他几乎都能用默认值。
osd journal size 默认值是 0,所以你得在 ceph.conf 里设置。此值应该是 filestore max sync interval 和期望吞吐量的乘积再乘以 2.
osd journal size = {2 * (expected throughput * filestore max sync interval)}[root@osd1 ceph]# ceph --admin-daemon /var/run/ceph/ceph-mon.osd1.asok config show|grep filestore_max_sync_interval
"filestore_max_sync_interval": "5", 除了为对象保存多个副本外,ceph 还靠洗刷归置组来保证数据完整性。这种洗刷类似对象存储层的 fsck,对每个归置组,ceph 生成一个所有对象的目录,并比对每个主对象及其副本以确保没有对象丢失或错配。轻微
洗刷(每天)检查对象尺寸和属性,深层洗刷(每周)会读出数据并用校验和保证数据完整性。
osd op threads=4
osd disk threads=2
当你增加或移除 OSD 时,CRUSH 算法将要求重新均衡集群,它会把一些归置组移出或移入多个 OSD 以回到均衡状态。归置组和对象的迁移过程会明显降低集群运营性能,为维持运营性能,ceph 用 backfilling 来执行此迁移,它可以使得 ceph 的回填操作优先级低于用户读写请求。(通过优先级来区分读写请求,这个做法很好!)
如果某 OSD 崩溃并重生,通常和其他 OSD 不同步,没有同归置组内最新版本的对象。这时,OSD 进入恢复模式并且搜索最新数据副本,并更新运行图。根据 OSD 挂的时间长短,OSD 的对象和归置组可能明显过期,另外,如果一个失效域挂了(如一个机柜),多个 OSD 会同时重生,这样恢复时间更长、更耗资源。
ceph 扩展属性用底层文件系统(如果没有尺寸限制)的 XATTR 存储为 inline xattr。
| | |
|---|















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









