







《守望先锋》中的英雄
来自加州大学河滨分校的物理学博士学位的Bowen Yang正在致力于构建一个模型——对游戏中的人物特征进行有意义的学习,来预测电子竞技游戏中的获胜团队。这个方法广泛适用于任何具有结构化数据的业务。
现在,电子竞技游戏是一个有着巨大潜力且不断上升的市场。去年,在英雄联盟的世界冠军赛中,仅仅一场半决赛就吸引了1.06亿观众,甚至超过了2018年的超级碗(美国职业橄榄球大联盟年度冠军赛)。为玩家提供个性化游戏分析的公司Visor,就希望能够有一个可以实时预测团队胜率的模型。
预测比赛
预测模型有很多种用途。比如,它可以向玩家提供有效反馈,帮助他们提高技能;对于玩家,它可以成为一个很好的参与工具,来吸引那些不熟悉游戏规则的潜在玩家;另外,如果一个模型在预测方面能够超越人类,那么它在电子竞技下注方面就会有着前所未有的潜力。

DOTA2国际邀请赛现场
《守望先锋》简介
我们今天建模的对象是《守望先锋》——一款基于团队的多人在线射击游戏。每个队伍有六名玩家,每位玩家从英雄列表(26名英雄)中选择一个英雄(游戏角色,如超级马里奥),与另一队进行战斗,每场游戏都有特定的游戏地图(游戏开始之前就已设定)。
游戏中有很多因素会影响游戏的预测结果,其中大部分是分类特征。举个例子,英雄的选择对于游戏的前期有着很大的作用。因此,我们面临的挑战是:如何处理这些分类特征。如果我只使用一种热编码,那么特征空间可以很轻松地增长到数百个维度。不幸的是,收集足够多的游戏数据来满足这个高纬度特征空间,这几乎是不可能的。
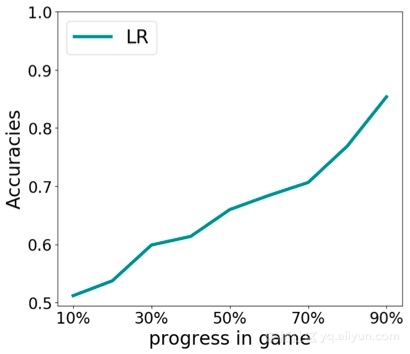
纵轴和横轴分别为预测准确度与游戏进度,使用热编码和特征选择的逻辑回归对预测进行建模。在游戏接近尾声时,预测较为准确;但在游戏开始时,预测几乎是一个随机值(具有0.5的准确性)。
本文将重点介绍如何使用嵌入对这些游戏角色进行建模,以及如何提升预测的准确度。
有关更多细节和实现,请参阅我的Github链接。
多个英雄可以组成一个队伍(“复仇者”)
从《魔兽世界》等角色扮演游戏到Dota 2、LoL和Overwatch等战斗类游戏,团队是现代多人在线视频游戏的核心概念,而英雄则是队伍的基础。
《守望先锋》中的英雄可以分为三类:进攻(DPS)、防御(坦克)和辅助,每个英雄都有自己的强项和弱点。一个团队应该保持英雄成员的平衡(所以没有特定的阵容)、配合(团队配合非常重要),根据当前的作战地图和英雄的技能水平形成团队策略。这和篮球比较比较相似,需要后卫、中锋和前锋合作。因此,团队的组合需要有一定的模式,甚至某个英雄可以在一个团队中共同出现。

典型的均衡团队需要有2名防御(坦克)、2名进攻(DPS)和2名辅助。
多个单词可以组成一个句子
我们可以从英雄和单词的类比中得出某些结论。一个单词本身有自己的含义,如果形成一个句子或一篇文章,那么,它的意义更大。同样地,英雄本身也有自己的“含义”和特征,比如一些英雄攻击力强、一些英雄则擅长防守,如果二者组成一个团队,那么,他们的角色会变得更加复杂。
以前,单词是用一个热编码建模的,这种编码很大程度上受到高纬灾难的影响,因为词汇量太大,以至于特征空间的维度可能很容易就超过数十万。一个热编码简单地假设单词之间彼此独立,即它们的表示(representations)是相互正交的,它并不捕获单词在句子中的含义。另一方面,单词也可以表示为分布式表示。这样,单词的语义可以通过更低维的矢量(嵌入)来捕获。
当用语词的分布式表示的算法是著名的word2vec模型。
超越word2vec
为了利用嵌入的优势,我们应该考虑以下几个事项:
1.相似性:相似性代表了输入之间的“重叠”。例如,“国王”和“女王”代表统治者。输入的重叠越多,它们的嵌入就越密(更小的维度)。换句话说,必须有不同输入到相同输出的映射。如果输入是相互正交的,那么嵌入就没有任何意义了。
2.训练任务:嵌入是从训练任务中(预)学习的。训练任务应该与我们自己的任务相关,因此嵌入的信息是可转移的。例如,word2vec在Google新闻上进行训练,然后用于机器翻译。它们是相关的,因为它们的词语具有相同的语义含义。
3.大量的数据:为了找到输入数据之间的相似性或关系,我们需要大量数据来探索高维度空间。因为有大量的可用于无监督学习的数据,分布式表示可以减少维度背后的“黑魔法”。例如,word2vec模型在数十亿字上进行训练。在一定程度上,嵌入仅仅是独热编码输入和下行任务之间的附加线性层的权重。为了训练包括嵌入层的整个管道,我们仍然需要大量数据来填充高维度输入空间。Continuous bag of heroes模型
考虑完以上几个问题,我们现在开始设计Hero2vec模型。
1.相似性:如前所述,《守望先锋》中的英雄属于某些类别。这种相似性表明它们可以通过分布式表示来描述,而不是一个热正交编码。
2.训练任务:通过对中心词和上下文词的共现进行建模,word2vec试图来捕捉单词的一般语义含义。同样,高协作性的英雄很可能会在一个团队中同时出现,即联合概率P(h0,h1,... h5)很高(h代表英雄)。但是,对这个联合概率进行建模并没有非常简单。或者,我们可以尝试使用最大化条件概率P(h0 | h1,h2,... h5)来建模。由于游戏的预测只是P(结果| h0,h1,... h5,其他因素),因此这两个任务是高度相关。
给定一个团队中的五个英雄,我们就可以预测出生存到最后的的英雄。例如,如果一支球队已经有2名后卫,2名中锋和1名前锋,那么最后一名球员很有可能成为球队的前锋。
3.数据:Visor提供了超过30,000多种团队组合用于预训练嵌入。与数十亿的单词相比,30,000个组合可能看起来很小,同样,输入维度也比词汇表中的单词(例如260,000+)要小的多(26英雄)。考虑到训练数据的需求随维度呈指数增长,实际上,30,000个组合足够进行训练。
4.模型:概率P(h0 | h1,h2,... h5)与word2vec中连续词袋(CBOW)模型中的P(中心词语|上下文词语)完全相同。不同于单词的是,(h1,h2,... h5)之间相互置换,并不会影响概率,因此(h1,h2,... h5)的嵌入总和实际上就是输入总和。在这里,除了P(h0 | h1,h2,... h5)外,我们还可以对P(h1 | h0,h2,... h5)等进行建模,使数据集可以有效的扩展6次。
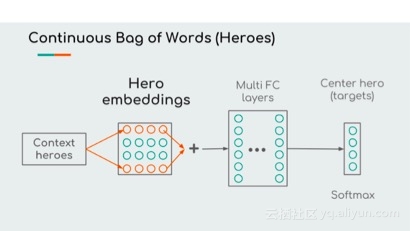
Hero2vec的模型架构,包括嵌入层、全连接神经网络和softmax层。由于softmax层只有26个目标,所以不需要负采样。
英雄的可视化处理
可以将英雄的嵌入(10个维度)投影到二维平面上(使用PCA),实现可视化,如下图所示。
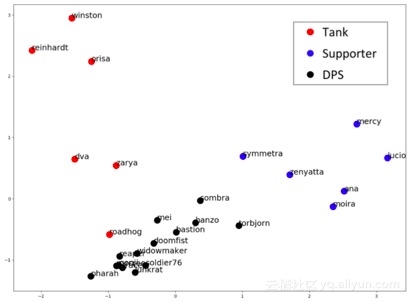
英雄的嵌入(投影到二维平面上)
显然,嵌入成功地捕捉了英雄背后的游戏设计。英雄根据自己的角色或类别进行聚类。更有意思的是,嵌入还可以捕捉英雄超越其类别内其它英雄的更微妙的特征。例如,尽管Roadhog英雄是防御(坦克),玩家仍然把它看作进攻(DPS);虽然Symmetra是辅助,但它并不能治愈队友,所以她更接近进攻(DPS)和防御(坦克)等。玩家并不像游戏设计师所认为的那样,将它们视为两类。对于熟悉《守望先锋》的玩家来说,进攻型DPS和防御性DPS之间的界限非常模糊,也就是说,玩家并没有根据游戏设计的本意,将它们归为两类。
因此,与硬编码类别的英雄(或产品)相比,在捕捉英雄的特征或属性时,嵌入可以更加流畅和准确的对其进行捕捉,即玩家和游戏设计者都能从嵌入中提取更多有用的信息。玩家可以用这个模型来更好地理解或欣赏该游戏,而游戏设计师也可以利用该模型对游戏设计进行验证和改进。
Map2vec
我们已经讨论过了如何在游戏中模拟英雄。在介绍英雄嵌入是如何帮助我们预测游戏胜负之前,我想简单地谈谈如何处理另一个分类特征——地图。
《守望先锋》的每场游戏都是在特定的游戏地图上进行的,而团队的组合取决于地图的布局,即P(团队|地图)。通过贝叶斯规则重写,P(团队|地图)〜P(地图|团队)P(团队)。因此,我们可以用P(地图|团队)来嵌入地图,如下所示。
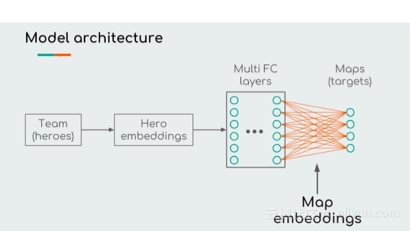
map2vec的模型结构。包括英雄的嵌入层、全连接神经网络和softmax层。softmax层的权重是地图的嵌入。
与上面的Hero2vec模型不同的是:映射的嵌入是从最后一个线性层绘制的,word2vec模型的输入嵌入和输出嵌入都可以用来代表单词。
同样的,地图的嵌入也可以进行可视化。
地图的可视化
通过嵌入,我们可以很好地理解地图背后的游戏设计。对于那些熟悉《守望先锋》的玩家来说,能够看到单个地图的进攻区域和防御区域之间的差异,这比查看地图之间的差异要更有意思。
相同的体系结构可以对任何共同出现的事务进行建模。例如,输入为一堆电影,目标为喜欢这些电影的特定客户。训练这个管道,就可以为我们提供电影和客户的嵌入。
使用英雄嵌入来预测游戏的胜负
使用英雄嵌入,可以提高游戏预测的准确度,如下图所示:
纵轴和横轴分别为预测准确度与游戏进度。用Hero2vec嵌入,该逻辑回归模型可以提高游戏前期的预测准确度。
如上图所示,二者都使用逻辑回归,当输入为英雄嵌入时,预测的准确度要比输入为一个热编码时高。更值得一提的是,英雄嵌入的确可以提升游戏前期或中期的预测准确度。
团队中英雄的组合能够为模型提供很多信息,这其中的一个原因就是,在游戏开始时,数字特征几乎不会有任何变化,因此,在游戏前期,数字特征基本上没有什么用处。随着游戏进入中期,数字特征种会积累更多的信息,这样一来,团队中英雄的组合形式就不再那么重要了。当游戏打到后期时,两个预测结果重叠,因为数值特征中的值足够多,足以来预测游戏结果。
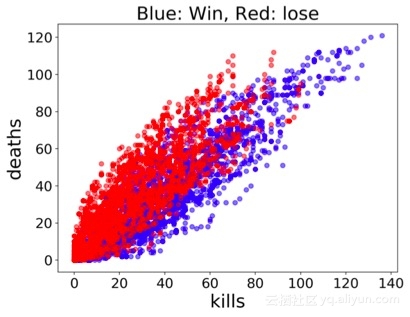
游戏结果与两个重要的数字特征。在游戏前期时(左下角),特征差异不大,结果几乎是重叠的。随着游戏继续进展(朝右上角),方差逐渐变大,预测结果也可以很容易的分开。
总结
本文讨论了如何用低维分布表示来表示高维分类特征,并遵循NLP和word2vec算法的逻辑。
通过对《守望先锋》中的英雄进行预训练,我构建了一个可以预测游戏胜负的可靠模型。并且,该模型在游戏前期的预测准确率更高,更为详细的模型和代码请查看我的Git库。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Predicting e-sports winners with Machine Learning》,译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文。














 3383
3383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









