







数据收集服务平均1小时OOM(java.lang.OutOfMemoryError: GC overhead limit exceeded)一次,发现都是在下载处理 JSON Atom Feed时OOM。怀疑是处理feed内存峰值消耗过大导致频繁Full GC。如下图: 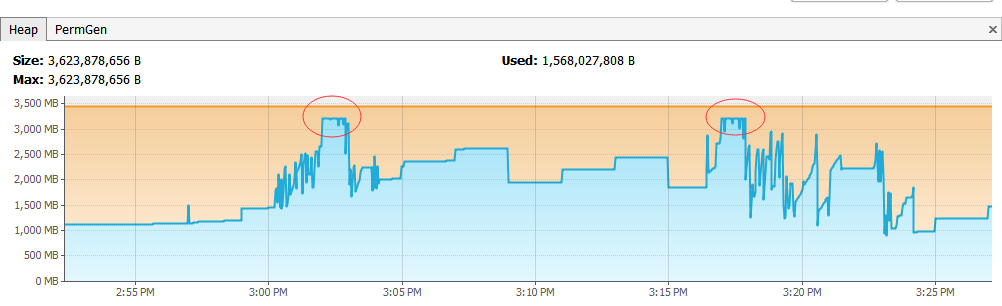
分析过程
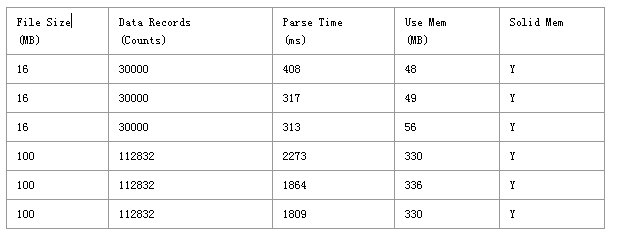
服务每15分钟会从Feed Server下载36个数据文件,包括12个17M,12个18M和12个100多M的文件。数据格式为JSON。由于服务是一次性加载整个JSON文件,然后转换成java对象。这个地方内存消耗可能会比较大,通过下面一组测试可以发现一些情况:
测试准备:
- 1个16M的JSON数据文件和1个100M的JSON数据文件。
- jackson2.3.4.Final (JSON 解析库)
- jdk1.6.0u30
测试方法:
- 通过Document Model API 来解析JSON文件,统计处理时间及新增内存大小
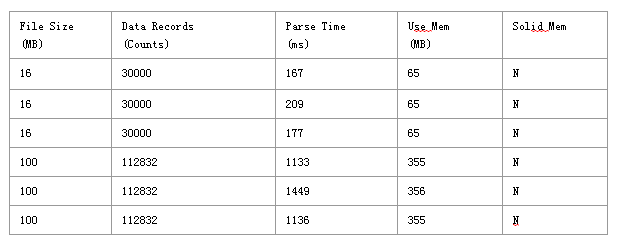
- 通过streaming API来解析JSON文件,统计处理时间及新增内存大小
测试结果:
- Document Model
- Streaming API
- Mem Usage Chart for Document Model (17M JSON file) - 39 Minor GC take 3.024s, 62 Full GC take 5.244s
- Mem Usage Chart for Streaming API(17M JSON file) - 394 Minor GC take 78ms, 30 Full GC take 557ms
结论:
- 下载是由5个线程并发下载,假设文件都是100M左右,那么在同一时刻的内存峰值有可能达到330Mx5,大概1.5G。基本上已经占掉了分配给整个进程的1/2。
- 每次OOM都发生在14分-20分左右,这个时候正是数据收集服务处理数据的时候,单个进程需要处理的设备数量是18万个,如果这个时候再开始下载feed,就一定会出现OOM。
修复和改进
仔细审查feed下载和解析的流程,发现使用的是一次加载整个文件的方式,根据前面表格的数据可以得知这种方式会长期占据内存,而且源文件中有一半的字段是后期不需要的。所以决定采用新方案如下:
- 减少并发下载feed的线程,由于前的5个改成2个。因为feed的下载和预处理并不是瓶颈,没必要在这开太多线程处理feed而导致处理是内存急剧上升。
- 采取streaming的方式处理JSON,预先把后面不需要的数据丢弃然后保存剩余数据至缓存共后期数据处理使用。
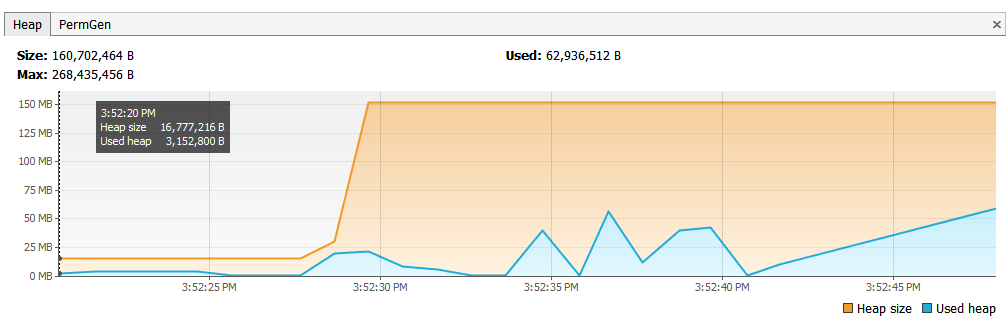
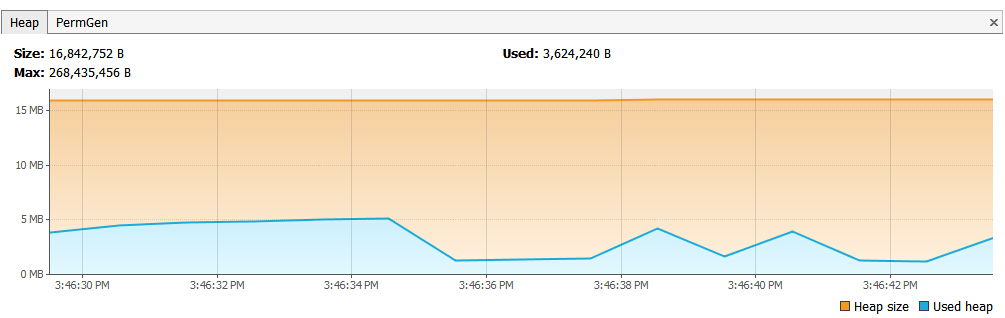
更改后的内存占用如下图: 
对比改进之前的内存分析图(文章首部第一副图),可以看到改进后的总占用量有所下降,而且内存可以快速回收。

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









