






0. 说明
DataSet 介绍 && Spark SQL 访问 JSON 文件 && Spark SQL 访问 Parquet 文件 && Spark SQL 访问 JDBC 数据库 && Spark SQL 作为分布式查询引擎
1. DataSet 介绍
强类型集合,可以转换成并行计算。
Dataset 上可以执行的操作分为 Transfermation 和 Action ,类似于 RDD。
Transfermation 生成新的 DataSet,Action 执行计算并返回结果。
DataSet 是延迟计算,只有当调用 Action 时才会触发执行。内部表现为逻辑计划。
Action 调用时,Spark 的查询优化器对逻辑计划进行优化,生成物理计划,用于分布式行为下高效的执行。
具体的执行计划可以通过 explain函数 来查看,方式如下:
scala> spark.sql("explain select name,class,score from tb_student").show(1000,false)
结果如图所示,show(1000 , false) 表示显式 1000行数据,结果不截断显式。

2. Spark SQL 访问 JSON 文件
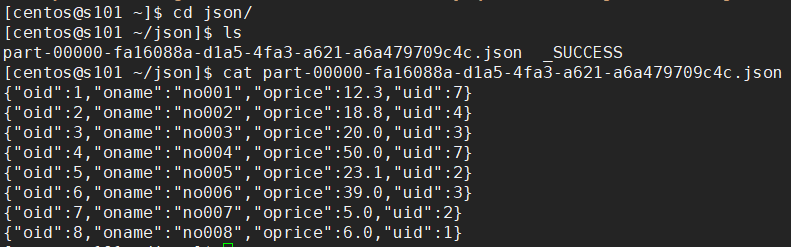
【保存 JSON 文件】
# 创建 DataFrame scala> val df = spark.sql("select * from orders") # 输出 JSON 文件 scala> df.write.json("file:///home/centos/json")
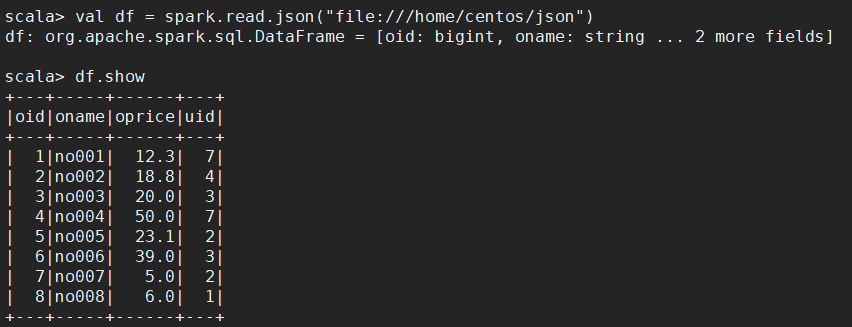
【读取 JSON 文件】
scala> val df = spark.read.json("file:///home/centos/json")
scala> df.show
3. Spark SQL 访问 Parquet 文件
【保存】
# 创建 DataFrame scala> val df = spark.sql("select * from orders") # 保存成 parquet 文件 scala> df.write.parquet("file:///home/centos/par")
【读取】
# 创建 DataFrame scala> val df = spark.read.parquet("file:///home/centos/par") # 读取 Parquet 文件 scala> df.show

4. Spark SQL 访问 JDBC 数据库
【4.1 处理第三方 jar】
spark SQL 是分布式数据库访问,需要将驱动程序分发到所有 worker 节点或者通过 --jars 命令指定附件
分发 jar 到所有节点 ,third.jar 为第三方 jar 包
xsync /soft/spark/jars/third.jar
通过--jars 命令指定
spark-shell --master spark://s101:7077 --jars /soft/spark/jars/third.jar
【4.2 读取 MySQL 数据】
val prop = new java.util.Properties() prop.put("driver" , "com.mysql.jdbc.Driver") prop.put("user" , "root") prop.put("password" , "root") # 读取 val df = spark.read.jdbc("jdbc:mysql://192.168.23.101:3306/big12" , "music" ,prop) ; # 显示 df.show
【4.3 保存数据到 MySQL 表(表不能存在)】
val prop = new java.util.Properties() prop.put("driver" , "com.mysql.jdbc.Driver") prop.put("user" , "root") prop.put("password" , "root") # 保存 dataframe.write.jdbc("jdbc:mysql://192.168.231.1:3306/mydb" , "emp" ,prop ) ;
5. Spark SQL 作为分布式查询引擎
【5.1 说明】
终端用户或应用程序可以直接同 Spark SQL 交互,而不需要写其他代码。

【5.2 启动 Spark的 thrift-server 进程】
在 spark/sbin 目录下执行以下操作
[centos@s101 /soft/spark/sbin]$ start-thriftserver.sh --master spark://s101:7077
【5.3 验证】
查看 Spark WebUI,访问 http://s101:8080
端口检查,检查10000端口是否启动
netstat -anop | grep 10000
【5.4 使用 Spark 的 beeline 程序测试】
在 spark/bin 目录下执行以下操作
# 进入 Spark 的 beeline [centos@s101 /soft/spark/bin]$ ./beeline # 连接 Hive !connect jdbc:hive2://localhost:10000/big12;auth=noSasl # 查看表 0: jdbc:hive2://localhost:10000/big12> show tables;
【5.5 编写客户端 Java 程序与 Spark 分布式查询引擎交互】
[添加依赖]
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.0</version> </dependency>
[代码编写]
package com.share.sparksql; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; /** * 使用 Spark SQL 分布式查询引擎 */ public class ThriftServerDemo { public static void main(String[] args) { try { Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection connection = DriverManager.getConnection("jdbc:hive2://s101:10000/big12;auth=noSasl"); ResultSet rs = connection.createStatement().executeQuery("select * from orders"); while (rs.next()) { System.out.printf("%d / %s\r\n", rs.getInt(1), rs.getString(2)); } rs.close(); } catch (Exception e) { e.printStackTrace(); } } }
[特别说明]
以上黄色部分为 HiveServer2 的验证模式,如果未添加以上黄色部分则会报错,报错如下:
















 1382
1382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









