







链表的数据是存在节点中的,而一个节点里面有:数据,下一个节点的地址,而单向链表可以看成如下结构:

必须要由一个指针变量来存储第一个节点的地址。
链表和数组不同,数组里面的内存都是连续的,数组只需要知道第一个内存的地址就能推算出接下来的所以内存地址,而链表并不是。
一、创建一个链表
#include <stdio.h>
#include <stdlib.h>
typedef int DataType;
typedef struct node{
DataType data;
struct node * next;
}Node;
//以上也可写成 typedef struct node Node;
int main(int argc, const char * argv[]) {
Node node1,node2,node3;
node1.data = 1;
node2.data = 2;
node3.data = 3;
//node.next就是个指针变量
node1.next = &node2;
node2.next = &node3;
node3.next = NULL;
Node * head = &node1;
return 0;
}也可以把节点创建封装起来,会减少代码量。
typedef int DataType;
typedef struct node{
DataType data;
struct node * next;
}Node,*Pnode;
//创建节点
Pnode createNode(DataType data)
{
Pnode node = (Pnode)malloc(sizeof(Node));
if (node != NULL) {
node->data = data;
node->next = NULL;
}
return node;
}
int main(int argc, const char * argv[]) {
Pnode p1 = createNode(1);
Pnode p2 = createNode(2);
Pnode p3 = createNode(3);
p1->next = p2;
p2->next = p3;
Node * head = p1;
while (head != NULL) {
printf("%d ",head->data);
head = head->next;
}
return 0;
}
//可以在每次使用的时候直接调用封装好的即可。二、遍历链表
Node *p = head;
while (p != NULL) {
printf("%d ",p->data);
p = p->next;
}定义的指针变量p先拿到了第一个的地址,打印出第一个的数据,然后再把第一个里面存的地址赋给p,这样就完成了一个链表的遍历。
但是以上方法创建的链表是在栈区的,加入写成这样
#include <stdio.h>
#include <stdlib.h>
typedef int DataType;
typedef struct node{
DataType data;
struct node * next;
}Node;
//以上也可写成 typedef struct node Node;
Node * creatList {
Node node1,node2,node3;
node1.data = 1;
node2.data = 2;
node3.data = 3;
//node.next就是个指针变量
node1.next = &node2;
node2.next = &node3;
node3.next = NULL;
Node * head = &node1;
return head;
}
int main(){
Node * head = creatList();
head->data
}
//这样是不行的,因为创建的链表是在栈区,所当调用完之后就会被释放,所需要想要用的话就要让内存是在堆区,由程序员自己来申请,也就是malloc。三、申请在堆区的链表
#include <stdio.h>
#include <stdlib.h>
typedef int DataType;
typedef struct node{
DataType data;
struct node * next;
}Node,*Pnode;
Pnode creatList()
{
Pnode pn1 = (Pnode)malloc(sizeof(Node));
Pnode pn2 = (Pnode)malloc(sizeof(Node));
Pnode pn3 = (Pnode)malloc(sizeof(Node));
//用完malloc记得要free
if (pn1 == NULL) {
return NULL;
}
if (pn2 == NULL) {
free(pn1);
return NULL;
}
if (pn3 == NULL) {
free(pn1);
free(pn2);
return NULL;
}
pn1->data = 1;
pn2->data = 2;
pn3->data = 3;
pn1->next = pn2;
pn2->next = pn3;
pn3->next = NULL;
return pn1;
}
void printList(Pnode head)
{
Pnode p = head;
while (p != NULL) {
printf("%d ",p->data);
p = p->next;
}
}
int main(int argc, const char * argv[]) {
Node *head = creatList();
printList(head);
return 0;
}四、插入节点
插入节点要考虑一个问题,要判断节点是不是最后一个节点
int inserNextList(Pnode p1,Pnode p2)
{
if (p1 == NULL || p2 == NULL) {
return -1;
}
/*
//等于NULL说明后面就没有节点了
if (p1->next == NULL) {
p1->next = p2;
return 0;
}else{
Pnode pTemporary = p1->next;
p2->next = pTemporary;
p1->next = p2;
}
简化后可以写成下面的模式
*/
//简化后
if (p1->next != NULL) {
p2->next = p1->next;
}
p1->next = p2;
//简化后
return 0;
}流程演示:



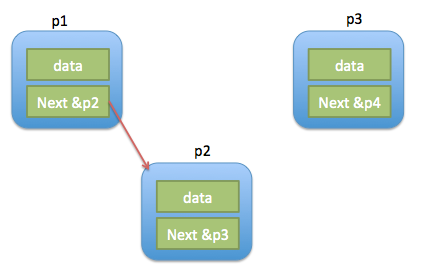

五、链表内按顺序插入节点。
#include <stdio.h>
#include <stdlib.h>
typedef int DataType;
typedef struct node{
DataType data;
struct node * next;
}Node,*Pnode;
//创建节点
Pnode createNode(DataType data)
{
Pnode node = (Pnode)malloc(sizeof(Node));
if (node != NULL) {
node->data = data;
node->next = NULL;
}
return node;
}
//加入节点操作
int inserNextNode(Pnode p1,Pnode p2)
{
if (p1 == NULL || p2 == NULL) {
return -1;
}
if (p1->next != NULL) {
p2->next = p1->next;
}
p1->next = p2;
//简化后
return 0;
}
//找到应该插入的节点的位置
int insertList(Pnode head, DataType data)
{
if (head == NULL) {
return -1;
}
Pnode p = head;
//这里为什么还要在创建一个指针变量?
//拿到前一个节点的信息
Pnode pRcord = NULL;
while (p != NULL) {
if (p->data > data) {
break;
}
pRcord = p;
p = p->next;
}
Pnode pNew = createNode(data);
if (pNew == NULL) {
return -1;
}
//分两种情况考虑 如果是插入的节点是最小的那就会被放置在第一个,如果不是就用另外一种
if (pRcord == NULL) {
pNew->next = head;
head = pNew;
}else{
//需要传入前一个节点,和插入节点信息
inserNextNode(pRcord, pNew);
}
return 0;
}
int main(int argc, const char * argv[]) {
Pnode p1 = createNode(1);
Pnode p2 = createNode(3);
Pnode p3 = createNode(4);
p1->next = p2;
p2->next = p3;
insertList(p1, 5);
Pnode pp = p1;
while (pp != NULL) {
printf("%d ",pp->data);
pp = pp->next;
}
return 0;
}六、链表排序
先回忆起数组的冒泡排序,冒泡排序是一种稳定的排序,每次都会挑出最大的数放在最右边。
#include <stdio.h>
void array_sort(int a[],int n)
{
int i,j;
for (i = 0; i<n; i++) {
for (j = 0; i + j < n-1; j++) {
if (a[j]>a[j+1]) {
int temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
for (int t = 0; t < n; t++) {
printf("%d ",a[t]);
}
}
int main(int argc, const char * argv[]) {
int a[] = {6,3,7,9,0};
array_sort(a,5);
return 0;
}怎么把他运用到链表上















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









