






Python爬虫获取招聘网站职位信息
摘要
本文介绍使用Python编写爬虫,获取招聘网站中感兴趣的职位信息。
好的开始,成功一半。另一半呢?知己知彼,百战百胜。
0. 环境
0.1 Python解释器安装
推荐使用Anaconda发行版,其包含了多个科学包及其依赖项。官网为:https://www.anaconda.com/
可以从官网下载安装包,在本地安装,将安装之后的位置作为环境变量加入到系统环境变量的PATH中。
Anaconda一般安装之后的位置为:C:\ProgramData\Anaconda3
0.2 集成开发环境
IDE(集成开发环境,Integrated Development Environment ):这一类开发环境一般包括代码编辑器、编译器、调试器和图形用户界面等工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套件。
推荐使用PyCharm的社区版,官网为:https://www.jetbrains.com/pycharm

1. 确定目标
这里的目标就是指要爬取的内容,打开招聘网站:https://www.51job.com:在搜索框中输入python,并点击搜索,会得到下面的结果,一共63页,3000余条职位信息:
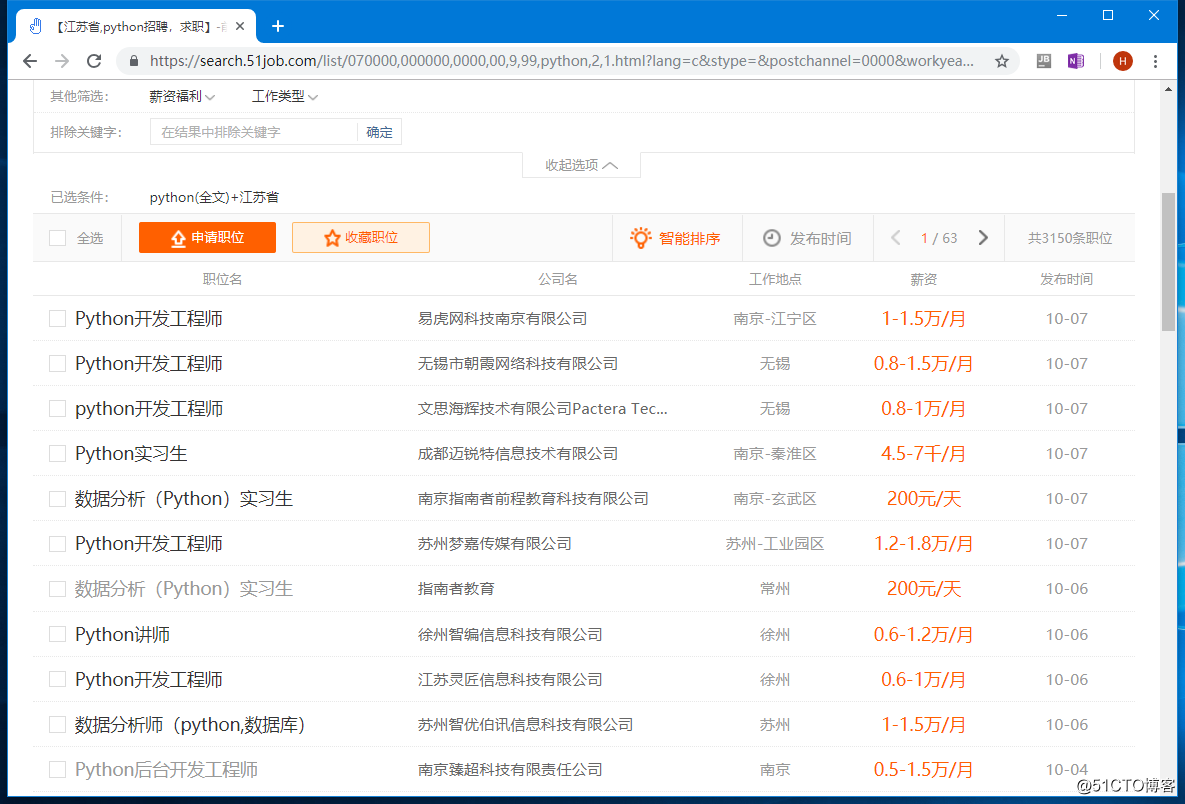
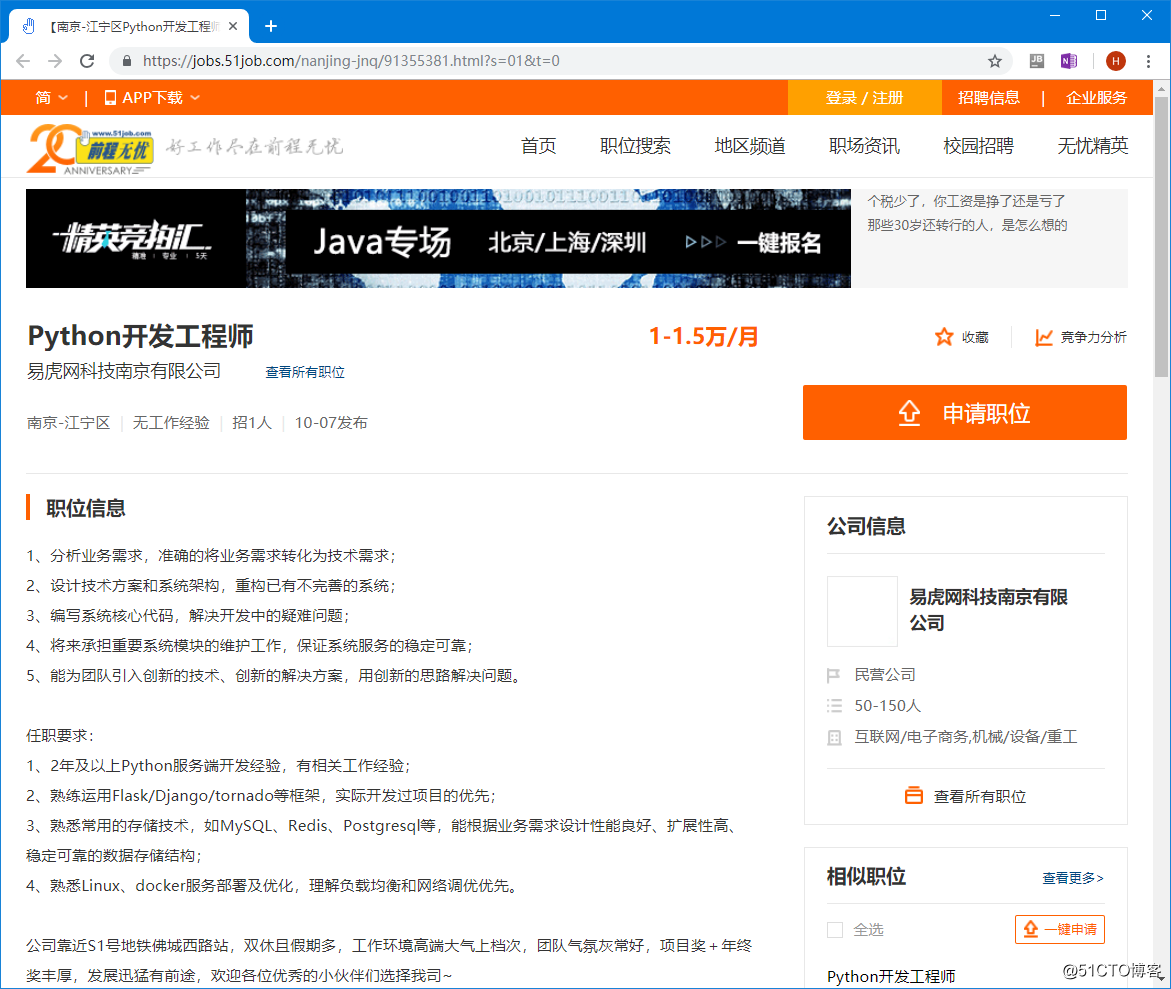
里面的每一个职位点开之后的页面包含职位的相关信息,我们的目标就是将这些信息爬取并保存到本地。
2. 请求
所有的职位信息页面的网址类似于如下形式:
https://jobs.51job.com/nanjing-jnq/91355381.html?s=01&t=0
https://jobs.51job.com/wuxi/97144561.html?s=01&t=0
https://jobs.51job.com/nanjing-qhq/106264137.html?s=01&t=0
。。。这些页面网址没有多少规律可循,但是可以从职位搜索结果页面中获取到:
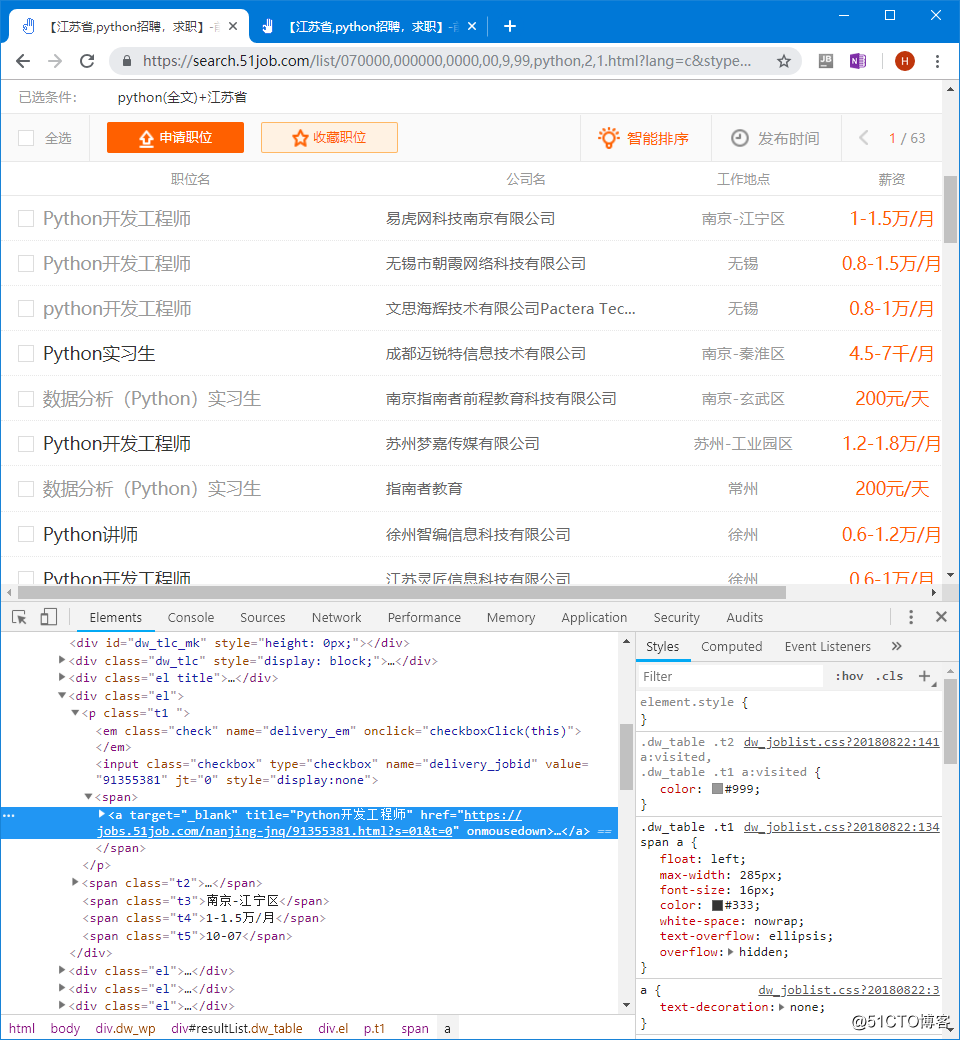
通过获取任意页数的职位名这一位置的链接,就能够获取这些职位信息的链接页面。
https://search.51job.com/list/070000,000000,0000,00,9,99,Python,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
https://search.51job.com/list/070000,000000,0000,00,9,99,Python,2,2.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=搜索结果地址中的python是查询的关键字,两个链接的差异之处,就是查询结果的第几页,所以可以根据这一点构建所有的搜索结果页面。
KEYWORD = 'python'
MAX_PAGE = 10
for i in range(MAX_PAGE + 1):
temp_url = 'https://search.51job.com/list/070000,000000,0000,00,9,99,' + KEYWORD + ',2,' + str(
i) + '.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='通过requests包的的请求功能,获取到页面:
r = requests.get('https://jobs.51job.com/nanjing-jnq/91355381.html?s=01&t=0')
r.encoding = 'gbk'
print(r.text)3. 解析
在搜索结果页面中需要解析出每一个职位的链接,同时在职位详细信息页面,要解析出职位名称,公司名称,工资,所在城市,职位信息等内容。
解析可以使用python中的lxml库进行解析,最常用的解析方式为xpath方式,通过Chrome中的F12开发者工具来获取xpath并调试。
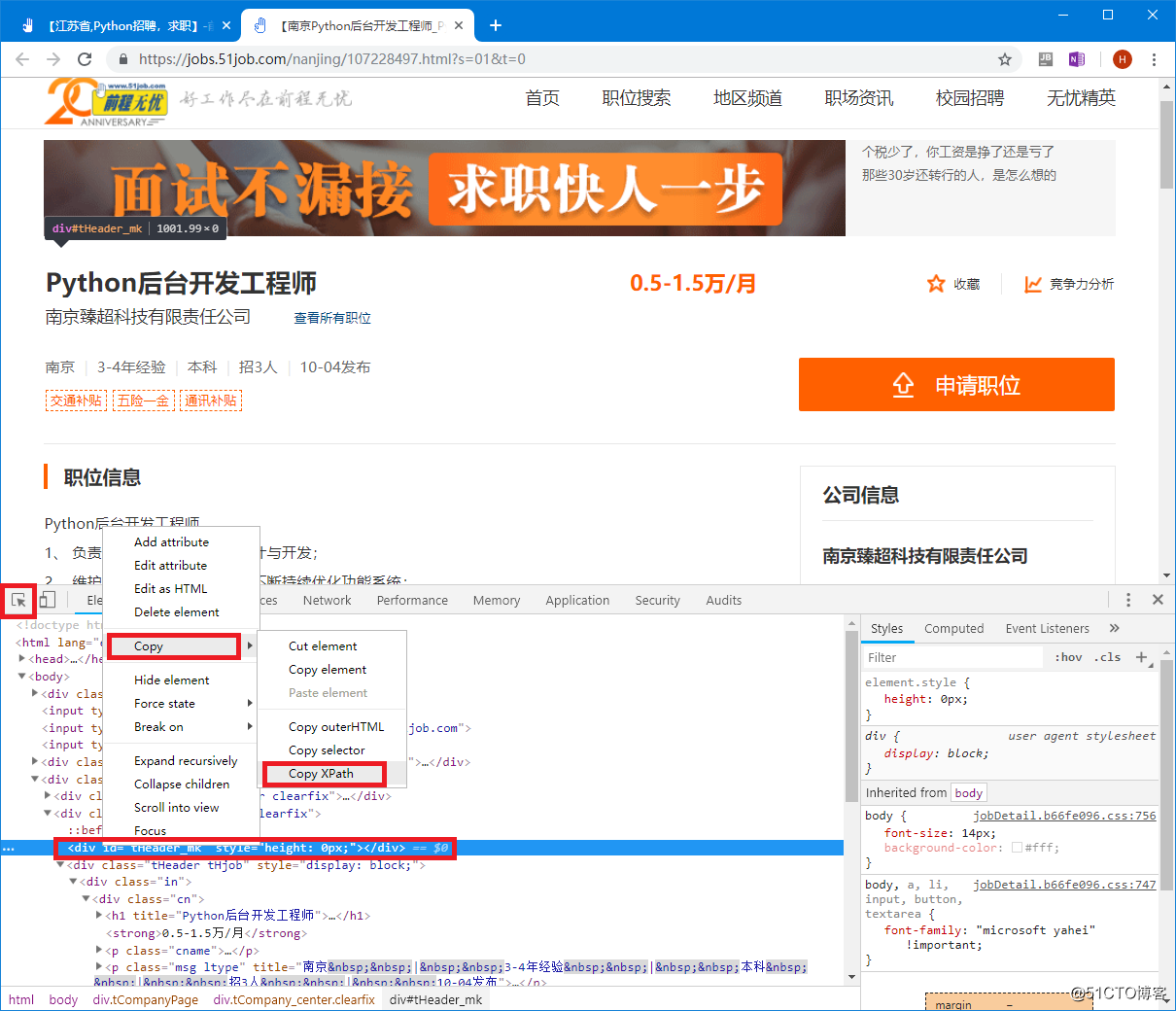
在F12开发者工具中,左上角的选择按钮可以在页面上选取感兴趣的元素,然后下面的元素窗口将高亮显示选中的元素。
在高亮显示的元素上,右键单击,在弹出的菜单中选择Copy -> Copy XPath,即可获得此元素的XPath。
然后在此元素基础之上,可以通过@属性的方式获取元素的属性值,例如获得职位的链接地址:
//*[@id="resultList"]/div[4]/p/span/a/@href
结果为:
https://jobs.51job.com/nanjing/107228497.html?s=01&t=0或通过text()方式获取元素的显示内容,例如职位详细信息里面的各项值:
/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()
结果为:
0.5-1.5万/月4. 存储
为方便后续的数据分析和绘图,我们将结果存储在excel表中,通过openpyxl库来实现。
在openpyxl中,主要用到三个概念:Workbooks,Sheets,Cells。Workbook就是一个excel工作表;Sheet是工作表中的一张表页;Cell就是一个单元格。
首先引入库:
from openpyxl import Workbook然后创建xlsx文件:
wb = Workbook()获取激活的sheet:
sheet = wb.active在其中编辑单元格的内容,将前面获取的职位信息写入到表格中:
sheet.append(list(temp_info.values()))最后将wb保存成一个文件:
wb.save('result.xlsx')5. 代码
完整代码参见附件。
点击链接可索取完整代码哦~
验证:星空
转载于:https://blog.51cto.com/13477015/2314470














 2957
2957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









