






lxml 是一种高性能的 Python HTML/XML 解析器,它利用XPath语法来快速定位和提取节点信息,与BeautifulSoup 相比,效率更高。
lxml 用法示例
1) 使用 etree.HTML 解析 html 字符串
示例文档
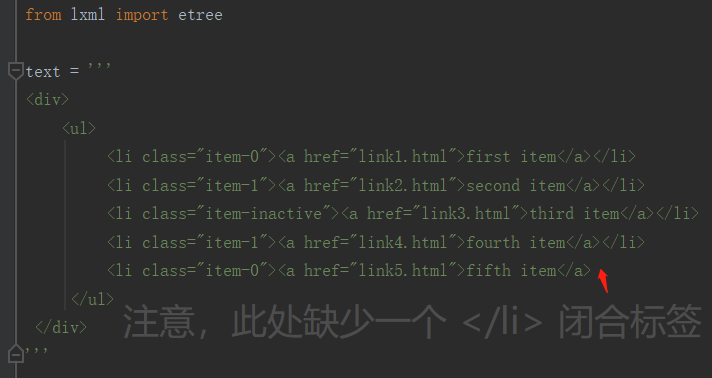
使用 lxml 解析 HTML 文档时,如果代码不规范,lxml 自动修复 HTML 节点:
# 利用 etree.HTML 将字符串解析为 HTML 文档
html = etree.HTML(text)
print(type(html))
# 运行结果:
# 将解析后的 HTML 文档转化为字符串进行查看
result = etree.tostring(html, encoding='utf-8')
print(result.decode('utf-8'))
解析后的结果如下图所示,自动补全了 li 标签,并添加了 html 、body 标签:

2) 使用 etree.parse 读取 html 文件
示例文件 demo.html

# 读取文件 demo.html
html = etree.parse('demo.html')
print(type(html))
# 运行结果:
# 将读取的 HTML 文档转化为字符串进行查看
result = etree.tostring(html, encoding='utf-8')
print(result.decode('utf-8'))
读取结果如下图所示,并没有自动添加 html 、body 标签:

并且,当文档中代码不规范,例如第一个示例文档缺少 li 标签时,运行会产生如下报错:
lxml.etree.XMLSyntaxError:
Opening and ending tag mismatch
# 节点打开标签和关闭标签不匹配
报错原因是,parse 函数默认使用 XML 解析器,XML 的语法规则比 HTML 严格。例如,在 HTML 中,某些元素不必有一个关闭标签,而在 XML 中,省略关闭标签是非法的,所有元素都必须有关闭标签。
在读取代码不规范的 HTML 文件时,可以自己创建 HTML 解析器:
# 通过创建 HTML 解析器读取不规范的文件
parser = etree.HTMLParser(encoding='utf-8')
html =etree.parse(
"demo.html", parser=parser)
result = etree.tostring(html, encoding='utf-8')
print(result.decode('utf-8'))
运行结果如下图所示,读取成功:

3) 利用 XPath 获取节点信息
示例:获取 ul 节点下第二个 li 子节点的 a 节点的 href 属性
html = etree.HTML(text)
demo = html.xpath('//ul/li[2]/a/@href')
print(demo)
# 运行结果:['link2.html']
利用 XPath 提取数据的规则详见另一篇文章:
参考文档
lxml python 官方文档:
http://lxml.de/index.html
lxml库 - 简书:
https://www.jianshu.com/p/a8064ce79e94
python3解析库lxml - 博客园:https://www.cnblogs.com/zhangxinqi/p/9210211.html
https://mp.weixin.qq.com/s/qFHWzM6BTS9XJf26RHc8bw















 5285
5285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









