






http://blog.csdn.net/luc9910/article/details/54377626
1. 全概率公式
在讲全概率公式之前,首先要理解什么是“完备事件群”。
我们将满足
这样的一组事件称为一个“完备事件群”。简而言之,就是事件之间两两互斥,所有事件的并集是整个样本空间(必然事件)。
假设我们要研究事件A。我们希望能够求出P(A),但是经过一番探索,却发现P(A)本身很难直接求出,不过却能够比较容易地求出各个P(Bi),以及相应的条件概率P(A|Bi)。
能不能根据这些信息,间接地求出P(A)呢?
这当然是可以的。
我们不要忘记,Bi是两两互斥的。
显然,AB1,AB2,AB3,⋯也是两两互斥的。1
一说到两两互斥,我们就想到了概率的加法定理:2
再根据条件概率的定义,我们得到了教科书上的全概率公式:
这样费了一番周折,我们总算得到了所求的P(A)。可以发现,虽然P(A)本身不好求,但我们可以根据它散落的“碎片”间接地将其求出。但不是所有情况都是能这样求出的——我们必须保证B1,B2,B3,⋯是一个完备事件群。这个其实也很好理解,假如你想将一个碎掉的花瓶重新还原,碎片如果不全,或者碎片之间出现了多余的“重叠”,还原工作都将以失败告终。
全概率公式可以从另一个角度去理解,把Bi看作是事件A发生的一种“可能途径”,若采用了不同的途径,A发生的概率,也就是相应的条件概率P(A|Bi)也会不同。但是,我们事先却并不知道将会走哪条途径,换言之,途径的选择是随机的3,这样就导致了不同途径被选中的可能性也许也会存在差异,这就是P(Bi)所表达的含义。这样一来,我们最终所要求的P(A),实际上就是一个不同路径概率的加权平均。
下面我们来举一个例子。
某地盗窃风气盛行,且偷窃者屡教不改。我们根据过往的案件记录,推断A今晚作案的概率是0.8,B今晚作案的概率是0.1,C今晚作案的概率是0.5,除此之外,还推断出A的得手率是0.1,B的得手率是1.0,C的得手率是0.5。那么,今晚村里有东西被偷的概率是多少?
通过阅读上述文字,我们大概对A、B、C三人有了一个初步的印象。首先,A的脑子可能有些问题,特别喜欢偷,但是技术相当烂。B看来是个江湖高手,一般不出手,一出手就绝不失手。C大概是追求中庸,各方面都很普通。
我们将文字描述转换为数学语言,根据作案频率可知
将“村里有东西被偷”记为S,根据得手率可以得到
很简单,所求得的就是
祝这个村晚上好运吧。
2. 贝叶斯公式
有了前面的基础,我们现在先直接抛出贝叶斯公式:
这个公式本身平平无奇,无非就是条件概率的定义加上全概率公式一起作出的一个推导而已。但它所表达的意义却非常深刻。
在全概率公式中,如果将A看成是“结果”,Bi看成是导致结果发生的诸多“原因”之一,那么全概率公式就是一个“原因推结果”的过程。但贝叶斯公式却恰恰相反。贝叶斯公式中,我们是知道结果A已经发生了,所要做的是反过来研究造成结果发生的原因,是XX原因造成的可能性有多大,即“结果推原因”。
举个例子:
假设某种病菌在人口中的带菌率为0.03,由于技术落后等等原因,使得带菌者有时也未被检出阳性反应(假阴性),不带菌者也可能会被检出阳性反应(假阳性)。有如下数据:
假如一个人被检出阳性,那么这个人带菌的概率是多少?
如果不用概率的思维,光凭感觉去想这个问题……误检率那么低,那这个带菌的可能性大概会很高吧?
我们用贝叶斯公式去实际计算一下。
结果竟然连40%都没到。
问题出在哪里?我们没有注意到,带菌率低到只有0.03,甚至比误检率还要低。也就是说,在一大批人里可以检查出一堆阳性的,而这堆阳性的人里面真正带菌的,也只是一小部分而已。
贝叶斯公式与机器学习
在机器学习中,我们经常遇到的一个问题就是分类。
我们看看维基百科上的“性别分类”问题(维基百科-朴素贝叶斯分类器)。
我们想要实现的是,通过知道一个人的身高、体重以及脚的尺寸,去判断这个人是男是女。
为了能够判断,我们当然需要一些参考数据,或者说,训练数据:
| 性别 | 身高(英尺) | 体重(磅) | 脚的尺寸(英寸) |
|---|---|---|---|
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
问题来了:
现有一身高6英尺,体重130磅,脚尺寸为8英寸的人,这个人是男是女呢?
这个表格看起来不够直观,我们先做一点微小的数据可视化工作:
#!/usr/bin/python3
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111, projection='3d') # 身高、体重、脚尺寸数据 x = [6, 5.92, 5.58, 5.92, 5, 5.5, 5.42, 5.75] y = [180, 190, 170, 165, 100, 150, 130, 150] z = [12, 11, 12, 10, 6, 8, 7, 9] # 男性用红色园圈表示 ax.scatter(x[:4], y[:4], z[:4], c='r', marker='o', s=100) # 女性用蓝色三角表示 ax.scatter(x[4:], y[4:], z[4:], c='b', marker='^', s=100) ax.set_xlabel('Height (feet)') ax.set_ylabel('Weight (lbs)') ax.set_zlabel('Foot size (inches)') # 显示散点图 plt.show()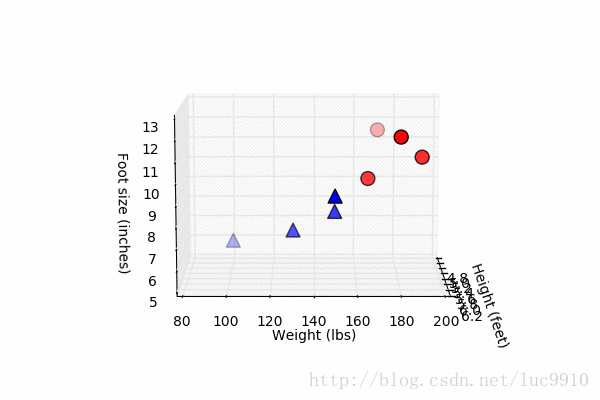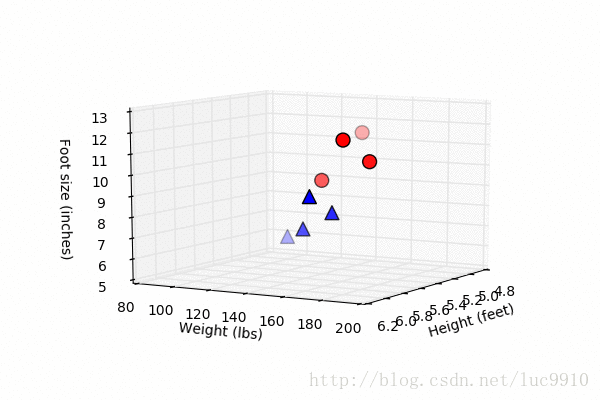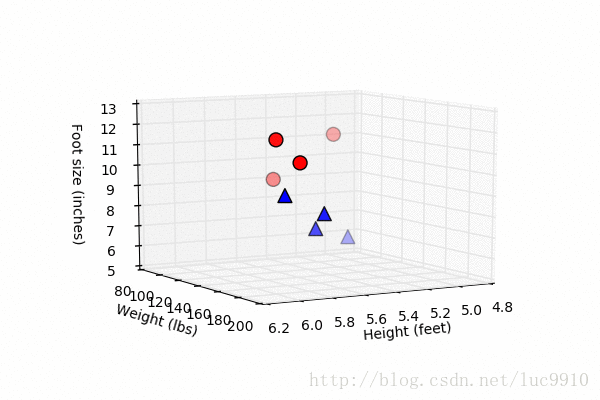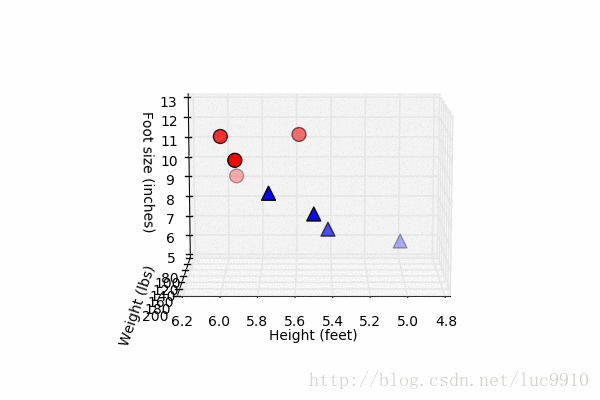
尽管只有8组数据,但我们在图中也大概看了出来,似乎男女的数据点都有种“聚成一团”的感觉,这似乎是一种启示。
但是这个和贝叶斯能有什么关系呢?
我们先对前面的贝叶斯公式做一些“扩展”:
我们记F1、F2、F3分别为身高、体重、脚尺寸的随机变量,取值当然是各自坐标轴上的值。再记C为分类结果的随机变量,取值为“男”或“女”。
不要忘了我们要解决的问题是什么。我们所要解决的问题的本质,就是在已知F1、F2、F3的时候,判断p(男|F1,F2,F3)与p(女|F1,F2,F3)究竟哪个更加大,换言之,这个人是更像男还是更像女,写成数学语言就是:
根据贝叶斯公式,得
我们的任务只是比较大小,而上式右边的分母是一个常数,不妨将其忽略掉以简化计算。这时候我们的问题就剩下如何求p(F1,F2,F3|C)P(C)了。
我们认定F1、F2、F3是彼此独立的特征4,那么有
于是我们的问题就化简为了
这样就够了么?当然没有。我们还有一个严重的问题没有解决——连续随机变量。我们不能想离散随机变量那样计算p(Fi|C)。
然而我们可以假设,身高、体重、脚尺寸都是正态分布。
我们分析一下样本数据的数字特征:
| 性别 | 均值(身高) | 方差(身高) | 均值(体重) | 方差(体重) | 均值(脚的尺寸) | 方差(脚的尺寸) |
|---|---|---|---|---|---|---|
| 男性 | 5.855 | 3.5033e-02 | 176.25 | 1.2292e+02 | 11.25 | 9.1667e-01 |
| 女性 | 5.4175 | 9.7225e-02 | 132.5 | 5.5833e+02 | 7.5 | 1.6667e+00 |
得到了均值与方差,也就得到了正态分布的μ与σ2参数。
如此,p(F1|C)p(F2|C)p(F3|C)就能顺利求出了。
比如,
值得注意的是,这里求的是连续随机变量的概率密度,所以求出比1大的值也是正常的5。
剩下的P(C)可以用样本中男女的出现频率来估计,估算出都是0.5。
综上,我们计算可得:
从计算结果可以看出,这个人是女性的可能性远大于是男性的可能性。
如果要通过编程实现这一过程,还要考虑平滑处理,这里不再赘述。
-
- 如果没有想明白这一步,可以利用Venn图来帮助理解。 ↩
- 若干个两两互斥的事件之和的概率,等于各事件的概率之和,即
P(A1+A2+⋯)=P(A1)+P(A2)+⋯↩ - 随机事件的意思就是,在试验之前你并不知道该事件是否会在试验中发生,发生与否取决于机遇。 ↩
- 假设不同特征彼此独立,即,当有
P(y|x1,⋯,xn)=P(y)P(x1,⋯,xn|y)P(x1,⋯,xn)
我们假设
P(xi|y,x1,⋯,xi−1,xi+1,⋯,xn)=P(xi|y)
所以才称作“朴素”贝叶斯(Naive Bayes)。 ↩ - 概率密度可以理解为“瞬时”的概率。对于概率密度函数,必须要满足两条性质:
(1)f(x)≥0;(2)∫∞−∞f(x)dx=1
所以只要f(x)整体的积分为1就可以了,并不要求局部的每个值都比1小。就像δ函数(维基百科-delta函数),虽然在0上的函数值可以大于1,但整体的积分却永远是1。 ↩















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









