







Sklearn 官网提供了一个流程图,蓝色圆圈内是判断条件,绿色方框内是可以选择的算法:
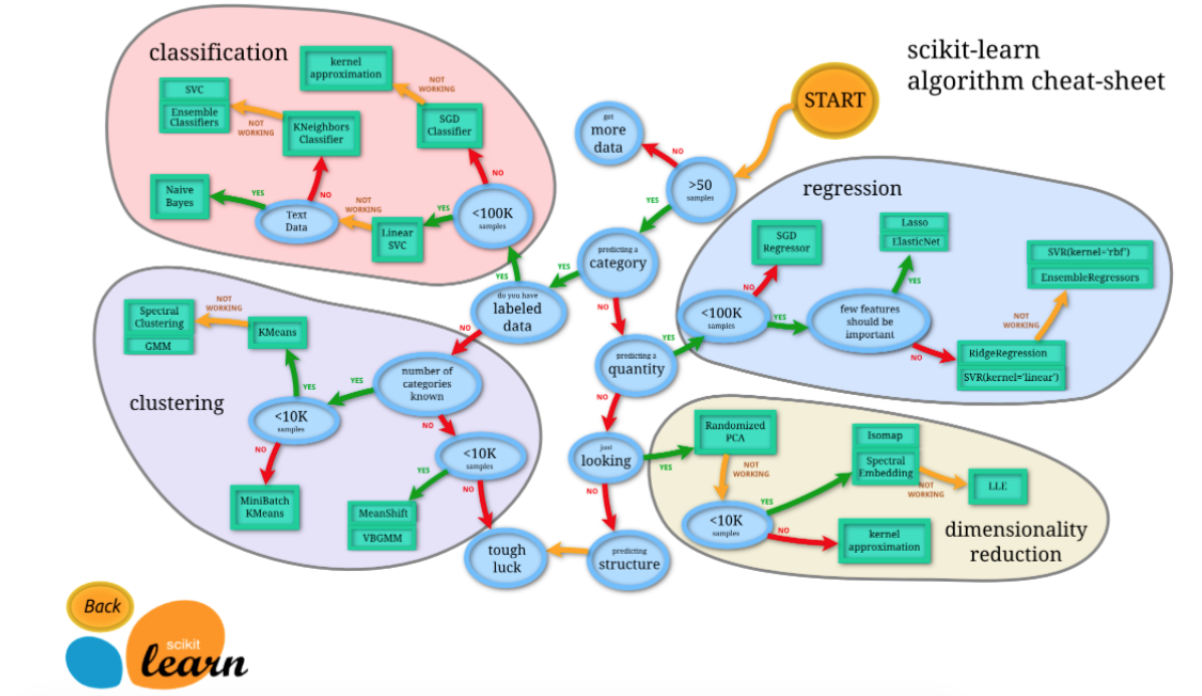
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中,可以看到算法有四类,分类,回归,聚类,降维。
其中 分类和回归是监督式学习,即每个数据对应一个 label。 聚类 是非监督式学习,即没有 label。 另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。
然后看问题属于哪一类问题,是分类还是回归,还是聚类,就选择相应的算法。 当然还要考虑数据的大小,例如 100K 是一个阈值。
下面通过一个列子演示下sklearn
Sklearn 本身就有很多数据库,可以用来练习。 以 Iris 的数据为例,这种花有四个属性,花瓣的长宽,茎的长宽,根据这些属性把花分为三类。
我们要用 分类器 去把四种类型的花分开。

K-近邻算法(KNN)
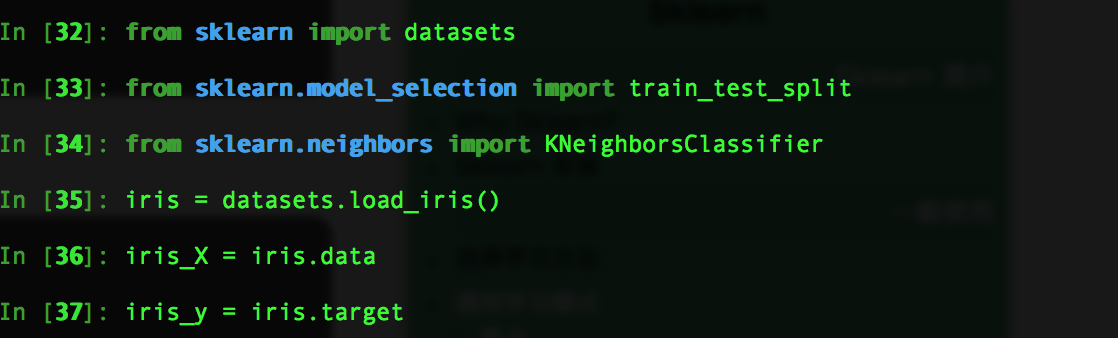
训练集和测试集合分开

使用fit训练样本,和predict 预测

简单的列子结束 下面一章 讲讲正则化,交叉验证















 6553
6553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









