







DEX简介
Android平台中没有直接使用Class文件格式,因为早期的Anrdroid手机内存,存储都比较小,而Class文件显然有很多可以优化的地方,比如每个Class文件都有一个常量池,里边存储了一些字符串。一串内容完全相同的字符串很有可能在不同的Class文件的常量池中存在,这就是一个可以优化的地方。当然,Dex文件结构和Class文件结构差异的地方还很多,但是从携带的信息上来看,Dex和Class文件是一致的。
另外一提,不管是ART还是Dalvik虚拟机,都是通过解析dex来执行指令的,所以即使在7.0或者更高版本的源代码中,依然存在dalvik的文件夹,并且起着非常重要的作用,编译dex就是其中一项。
DEX 包含的数据格式
在dex文件中,可能存在如下格式的数据字段。
| 类型 | 含义 |
| u1 | 等同于 uint8_t,表示 1 字节的无符号 数 |
| u2 | 等同于 uint16_t,表示 2 字节的无符号数 |
| u4 | 等同于 uint32_t,表示 4 字节的无符号数 |
| u8 | 等同于 uint64_t,表示 8 字节的无符号数 |
| sleb128 | 有符号 LEB128,可变长度 1~5 字节 |
| uleb128 | 无符号 LEB128,可变长度 1~5 字节 |
| uleb128p1 | 无符号 LEB128 值加1,可变长 1~5 字节 |
在程序中,一般使用32位比特位来表示一个整型的数值。不过,一般能够使用到的整数值都不会太大,使用32比特位来表示就有点太浪费了。对于普通计算机来说,这没什么问题,毕竟存储空间那么大。但是,对于移动设备来说,存储空间和内存空间都非常宝贵,不能浪费,能省就省。
uleb128
Android的dex中,就使用了uleb128(Unsigned Little Endian Base 128)、uleb128p1(Unsigned Little Endian Base 128 Plus 1)和sleb128(Signed Little Endian Base 128)编码来解决整形数值占用空间大小浪费的问题。
首先,我们来看看uleb128编码是怎么回事。要了解原理,最简单的方法,还是阅读代码。Dalvik使用readUnsignedLeb128函数来尝试读取一个uleb128编码的数值(代码位于dalvik\libdex\Leb128.h中):
DEX_INLINE int readUnsignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result > 0x7f) {
int cur = *(ptr++);
result = (result & 0x7f) | ((cur & 0x7f) << 7);
if (cur > 0x7f) {
cur = *(ptr++);
result |= (cur & 0x7f) << 14;
if (cur > 0x7f) {
cur = *(ptr++);
result |= (cur & 0x7f) << 21;
if (cur > 0x7f) {
cur = *(ptr++);
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
} 讲真,看看C代码还是很长知识的。先读取第一个字节,并判断其是否大于0x7f(二进制 01111111),如果大于的话,则代表这个字节的最高位是1,而不是0。如果是1的话,则代表还要读下一个字节;如果是0的话,则代表uleb128编码的数值到此为止。而代表原来整型值的32位数据就嵌入在每个字节当中的7比特位中(应为最高位被用来表示编码是否结束了)。所以,如果要表示的整形值非常大的话,就需要5个字节表示了(反而比原来多一个字节)。而其实uleb128可以表示数值的范围其实是要比32位整形值要大的,有三位被浪费掉了。不过,一般程序中使用的整型值都不会太大,经常是小于100的,对于这种情况来说,只需要使用一个字节就可以表示了,比普通32位整形表示法少用了3个字节,节省的空间还是非常可观的。
uleb128编码,是小端结尾的,即第一个字节代表的是整形值的最低7比特位的值,第二个字节代表整型值的次低7比特位的值,以此类推,最后一个字节(最高位为0)代表整形值的最高7比特位的值。所以,代码中每发现要多用一个字节,都要多向左移动7位。
在Android源码提供的文档中,有下面这张图,可以帮助理解:

这张图表示了,只使用两个字节进行编码的情况。可以看到,第一个字节的最高位为1,代表还要用到接着的下一个字节。并且,第一个字节存放的是整型值的最低7位。而第二个字节的最高位为0,代表编码到此结束,剩下的7个比特位存放了整型值的高7位数据。拼接后结果是(bit13 bit12 ....bit7 bit6.....bit0)
sleb128
我们接下来在看看sleb128编码的实现:
DEX_INLINE int readSignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result <= 0x7f) {
result = (result << 25) >> 25;
} else {
int cur = *(ptr++);
result = (result & 0x7f) | ((cur & 0x7f) << 7);
if (cur <= 0x7f) {
result = (result << 18) >> 18;
} else {
cur = *(ptr++);
result |= (cur & 0x7f) << 14;
if (cur <= 0x7f) {
result = (result << 11) >> 11;
} else {
cur = *(ptr++);
result |= (cur & 0x7f) << 21;
if (cur <= 0x7f) {
result = (result << 4) >> 4;
} else {
cur = *(ptr++);
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
} 没区别,区别就是增加了位移操作,实际就是用来高位判别正负的。
uleb128p1
这种编码方式是Dalvik独有的,如果所要表示的整数范围只包含一个负数,也就是-1的话,如果直接用sleb128编码,那就太浪费了,因此Android创造出了这种所谓的uleb128p1的编码方式。实现如下(代码位于libcore\dex\src\main\Java\com\android\dex\Dex.java):
public final class Dex {
...
public final class Section implements ByteInput, ByteOutput {
...
public int readUleb128p1() {
return Leb128.readUnsignedLeb128(this) - 1;
}
...
}
...
} 其实现原理就更简单了,就是将其当做uleb128编码的值进行解码,然后再减一就可以了。因为uleb128能表示范围为0~4,294,967,295的整数,所以uleb128p1就可以表示范围为-1~4,294,967,294的整数。解码时要减一,那么反过来,编码时就需要加一。
DEX数据结构
引用官方文档上的一张表 https://source.android.com/devices/tech/dalvik/dex-format.html
| Name | Format | Description |
|---|---|---|
| header | header_item | 头 |
| string_ids | string_id_item[] | 记录当前文件所有字符串,包括命名. string identifiers list. These are identifiers for all the strings used by this file, either for internal naming (e.g., type descriptors) or as constant objects referred to by code. This list must be sorted by string contents, using UTF-16 code point values (not in a locale-sensitive manner), and it must not contain any duplicate entries. |
| type_ids | type_id_item[] | 当前文件中用到的所有类,根据引用的 struct DexTypeId { u4 descriptorIdx; /* index into stringIds list for type descriptor */ }; type identifiers list. These are identifiers for all types (classes, arrays, or primitive types) referred to by this file, whether defined in the file or not. This list must be sorted by |
| proto_ids | proto_id_item[] | 当前文件方法原型定义的集合,根据returnTypeIdx和parametersOff排序。 struct DexProtoId { u4 shortyIdx; /* index into stringIds for shorty descriptor */ u4 returnTypeIdx; /* index into typeIds list for return type */ u4 parametersOff; /* file offset to type_list for parameter types */ }; method prototype identifiers list. These are identifiers for all prototypes referred to by this file. This list must be sorted in return-type (by |
| field_ids | field_id_item[] | 类内部字段列表,根据classIdx 和 typeIdx 和nameIdx排序。 struct DexFieldId { u2 classIdx; /* index into typeIds list for defining class */ u2 typeIdx; /* index into typeIds for field type */ u4 nameIdx; /* index into stringIds for field name */ }; field identifiers list. These are identifiers for all fields referred to by this file, whether defined in the file or not. This list must be sorted, where the defining type (by |
| method_ids | method_id_item[] | 所有方法的列表 struct DexMethodId { u2 classIdx; /* index into typeIds list for defining class */ u2 protoIdx; /* index into protoIds for method prototype */ u4 nameIdx; /* index into stringIds for method name */ }; method identifiers list. These are identifiers for all methods referred to by this file, whether defined in the file or not. This list must be sorted, where the defining type (by |
| class_defs | class_def_item[] |
struct DexClassDef { u4 classIdx; /* index into typeIds for this class */ u4 accessFlags; /*访问权限*/ u4 superclassIdx; /* index into typeIds for superclass */ u4 interfacesOff; /* file offset to DexTypeList */ u4 sourceFileIdx; /* index into stringIds for source file name */ u4 annotationsOff; /* file offset to annotations_directory_item */ u4 classDataOff; /* file offset to class_data_item */ u4 staticValuesOff; /* file offset to DexEncodedArray */ }; class definitions list. The classes must be ordered such that a given class's superclass and implemented interfaces appear in the list earlier than the referring class. Furthermore, it is invalid for a definition for the same-named class to appear more than once in the list. |
| call_site_ids | call_site_id_item[] | call site identifiers list. These are identifiers for all call sites referred to by this file, whether defined in the file or not. This list must be sorted in ascending order of call_site_off. This list must not contain any duplicate entries. |
| method_handles | method_handle_item[] | method handles list. A list of all method handles referred to by this file, whether defined in the file or not. This list is not sorted and may contain duplicates which will logically correspond to different method handle instances. |
| data | ubyte[] | data area, containing all the support data for the tables listed above. Different items have different alignment requirements, and padding bytes are inserted before each item if necessary to achieve proper alignment. |
| link_data | ubyte[] | data used in statically linked files. The format of the data in this section is left unspecified by this document. This section is empty in unlinked files, and runtime implementations may use it as they see fit. |
主要可以使用一张图来说明:
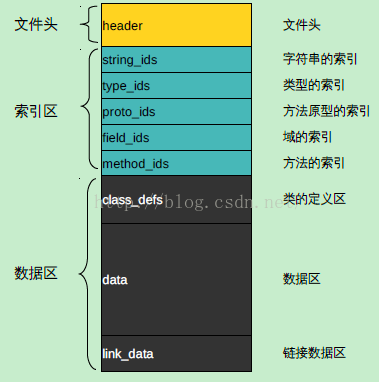
PS call_site_ids 以及 method_handles 在上面的结构中并没有出现,并且在dex结构解析的时候同样没有出现,连源文件上都没有类似字样,知道的朋友麻烦提供下线索学习学习。
header
其中头的结构比较详细
struct DexHeader
{
u1 magic[8]; // dex 版本标识,"dex.035"
u4 checksum; // adler32 检验
u1 signature[kSHA1DigestLen]; // SHA-1 哈希值,20个字节
u4 fileSize; // 整个 dex 文件大小
u4 headerSize; // DexHeader 结构大小,0x70
u4 endianTag; // 字节序标记,小端 "0x12345678",大端"0x78563412"
u4 linkSize; // 链接段大小
u4 linkOff; // 链接段偏移
u4 mapOff; // DexMapList 的偏移 (相当于dex中最后data的地址)
u4 stringIdsSize; // DexStringId 的个数
u4 stringIdsOff; // DexStringId 的偏移 字符串
u4 typeIdsSize; // DexTypeId 的个数
u4 typedeIdsOff; // DexTypeId 的偏移 类型
u4 protoIdsSize; // DexProtoId 的个数
u4 protoIdsOff; // DexProtoId 的偏移 声明
u4 fieldIdsSize; // DexFieldId 的个数
u4 fieldIdsOff; // DexFieldId 的偏移 字段
u4 methodIdsSize; // DexMethodId 的个数
u4 methodIdsOff; // DexMethodId 的偏移 方法
u4 classDefsSize; // DexClassDef 的个数
u4 classDefsOff; // DexClassDef 的偏移 类
u4 dataSize; // 数据段的大小
u4 dataOff; // 数据段的偏移
}data
data使用map_list来表示
/* * Direct-mapped "map_item". */ struct DexMapItem { u2 type; /* type code (see kDexType* above) */ u2 unused; u4 size; /* count of items of the indicated type */ u4 offset; /* file offset to the start of data */ }; /* * Direct-mapped "map_list". */ struct DexMapList { u4 size; /* #of entries in list */ DexMapItem list[1]; /* entries */ };
具体后面章节分析
引用
本文参考引用了如下网络资源:
http://blog.csdn.net/roland_sun/article/details/46708061
http://blog.csdn.net/innost/article/details/50377905
http://blog.csdn.net/anhuizhuanjiao/article/details/49814549
https://source.android.com/devices/tech/dalvik/dex-format.html
http://weixin.niurenqushi.com/article/2017-03-23/4799019.html















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









