







我们解决了从发送端(Producer)向接收端(Consumer)发送“Hello World”的问题。在实际的应用场景中,这是远远不够的。从本篇文章开始,我们将结合更加实际的应用场景来讲解更多的高级用法。
有时Consumer需要大量的运算时,RabbitMQ Server需要一定的分发机制来balance每个Consumer的load。试想一下,对于web application来说,在一个很多的HTTP request里是没有时间来处理复杂的运算的,只能通过后台的多个工作线程来完成,队列中的任务将会被工作线程共享执行,这样的概念在web应用这非常有用。接下来我们分布讲解。
应用场景就是RabbitMQ Server会将queue的Message分发给不同的Consumer以处理计算密集型的任务:
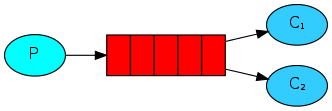
1. 准备
实际应用Consumer可能做的是计算密集型的工作,那就不能简单的字符串了。在现实应用中,Consumer有可能做的是一个图片的resize,或者是pdf文件的渲染或者内容提取。但是作为Demo,还是用字符串模拟吧:通过字符串中的.的数量来决定计算的复杂度,每个.都会消耗1s,即sleep(1)。
发送端:
package com.zhy.rabbitMq._02_workqueue;
import java.io.IOException;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class NewTask{
//队列名称
private final static String QUEUE_NAME = "queue2";
public static void main(String[] args) throws IOException{
//创建连接和频道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//发送10条消息,依次在消息后面附加1-10个点
for (int i = 0; i < 10; i++){
String dots = "";
for (int j = 0; j <= i; j++){
dots += ".";
}
String message = "helloworld" + dots+dots.length();
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
//关闭频道和资源
channel.close();
connection.close();
}
}
接收端:
package com.zhy.rabbitMq._02_workqueue;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.QueueingConsumer;
public class Work{
//队列名称
private final static String QUEUE_NAME = "workqueue";
public static void main(String[] argv) throws java.io.IOException,
java.lang.InterruptedException{
//区分不同工作进程的输出
int hashCode = Work.class.hashCode();
//创建连接和频道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(hashCode
+ " [*] Waiting for messages. To exit press CTRL+C");
QueueingConsumer consumer = new QueueingConsumer(channel);
// 指定消费队列
channel.basicConsume(QUEUE_NAME, true, consumer);
while (true){
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(hashCode + " [x] Received '" + message + "'");
doWork(message);
System.out.println(hashCode + " [x] Done");
}
}
/**
* 每个点耗时1s
* @param task
* @throws InterruptedException
*/
private static void doWork(String task) throws InterruptedException{
for (char ch : task.toCharArray()){
if (ch == '.')
Thread.sleep(1000);
}
}
}
2. Round-robin dispatching 循环分发
RabbitMQ的分发机制非常适合扩展,而且它是专门为并发程序设计的。如果现在load加重,那么只需要创建更多的Consumer来进行任务处理即可。当然了,对于负载还要加大怎么办?我没有遇到过这种情况,那就可以创建多个virtual Host,细化不同的通信类别了。
首先开启个Consumer,即运行两个工作者。
[x] Sent 'helloworld.1'
[x] Sent 'helloworld..2'
[x] Sent 'helloworld...3'
[x] Sent 'helloworld....4'
工作者1:
605645 [*] Waiting for messages. To exit press CTRL+C
605645 [x] Received 'helloworld.1'
605645 [x] Done
605645 [x] Received 'helloworld....3'
605645 [x] Done
工作者2:
18019860 [*] Waiting for messages. To exit press CTRL+C
18019860 [x] Received 'helloworld..2'
18019860 [x] Done
18019860 [x] Received 'helloworld.....4'
18019860 [x] Done
可以看到,默认的,RabbitMQ会一个一个的发送信息给下一个消费者(consumer),而不管每个任务的时长等等,且是一次性分配,并非一个一个分配。平均的每个消费者将会获得相等数量的消息。这样分发消息的方式叫做round-robin。中种分发还有问题,接着了解吧!
3. Message acknowledgment 消息确认
每个Consumer可能需要一段时间才能处理完收到的数据。你可能担心一个工作者(Consumer)在这个过程中出错了,异常退出了,而数据还没有处理完成,那么非常不幸这段数据就丢失了。因为我们采用no-ack的方式进行确认,一旦RabbitMQ交付了一个消息给消费者,会马上从内存中移除这条信息。也就是说,每次Consumer接到数据后,而不管是否处理完成,RabbitMQ Server会立即把这个Message标记为完成,然后从queue中删除了。
上述问题是非常严重的,但是如果一个Consumer异常退出了,它处理的数据能够被另外的Consumer处理,这样数据在这种情况下就不会丢失了(注意是这种情况下)。
为了保证数据不被丢失,RabbitMQ支持消息确认机制,即acknowledgments。为了保证数据能被正确处理而不仅仅是被Consumer收到,那么我们不能采用no-ack。而应该是在处理完数据后发送ack。
在处理数据后发送的ack,就是告诉RabbitMQ数据已经被接收,处理完成,RabbitMQ可以去安全的删除它了。
如果Consumer退出了但是没有发送ack,那么RabbitMQ就会把这个Message发送到下一个Consumer。这样就保证了在Consumer异常退出的情况下数据也不会丢失。
这里并没有用到超时机制。RabbitMQ仅仅通过Consumer的连接中断来确认该Message并没有被正确处理。也就是说,RabbitMQ给了Consumer足够长的时间来做数据处理。
默认情况下,消息确认是打开的(enabled)。上面代码中我们通过autoAsk= True 关闭了ack。重新修改一下callback,以在消息处理完成后发送ack:
boolean ack = false ; //打开应答机制
channel.basicConsume(QUEUE_NAME, ack, consumer);
//另外需要在每次处理完成一个消息后,手动发送一次应答。
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
这样即使你通过Ctr-C中断了Consumer,那么Message也不会丢失了,它会被分发到下一个Consumer。
如果忘记了ack,那么后果很严重。当Consumer退出时,Message会重新分发。然后RabbitMQ会占用越来越多的内存,由于RabbitMQ会长时间运行,因此这个“内存泄漏”是致命的。去调试这种错误,可以通过一下命令打印
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Listing queues ...
hello 0 0
...done.
4. Message durability消息持久化
我们学习了消费者被杀死,Message也不会丢失。但是如果RabbitMQ Server退出呢?软件都有bug,即使RabbitMQ Server是完美毫无bug的,它还是有可能退出的:被其它软件影响,或者系统重启了,系统panic了。。。
为了保证在RabbitMQ退出或者crash了数据仍没有丢失,需要将queue和Message都要持久化。
queue的持久化需要在声明时指定durable=True:
第一, 我们需要确认RabbitMQ永远不会丢失我们的队列。为了这样,我们需要声明它为持久化的。
boolean durable = true;
channel.queueDeclare("task_queue", durable, false, false, null);
注:RabbitMQ不允许使用不同的参数重新定义一个队列,所以已经存在的队列,我们无法修改其属性。
第二, 我们需要标识我们的信息为持久化的。通过设置MessageProperties(implements BasicProperties)值为PERSISTENT_TEXT_PLAIN。
channel.basicPublish("", "task_queue",MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
现在你可以执行一个发送消息的程序,然后关闭服务,再重新启动服务,运行消费者程序做下实验。
5. Fair dispatch 公平分发
你可能也注意到了,分发机制不是那么优雅。默认状态下,RabbitMQ将第n个Message分发给第n个Consumer。当然n是取余后的。它不管Consumer是否还有unacked Message,只是按照这个默认机制进行分发。
那么如果有个Consumer工作比较重,那么就会导致有的Consumer基本没事可做,有的Consumer却是毫无休息的机会。那么,RabbitMQ是如何处理这种问题呢?

通过 basic.qos 方法设置prefetch_count=1 。这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理一个Message。换句话说,在接收到该Consumer的ack前,他它不会将新的Message分发给它。 设置方法如下:
int prefetchCount = 1;
channel.basicQos(prefetchCount);
测试:改变发送消息的代码,将消息末尾点数改为3-2个,然后首先开启两个工作者,接着发送消息:
[x] Sent 'helloworld...3'
[x] Sent 'helloworld..2'
工作者1:
18019860 [*] Waiting for messages. To exit press CTRL+C
18019860 [x] Received 'helloworld...3'
18019860 [x] Done
工作者2:
31054905 [*] Waiting for messages. To exit press CTRL+C
31054905 [x] Received 'helloworld..2'
31054905 [x] Done
可以看出此时并没有按照之前的Round-robin机制进行转发消息,而是当消费者不忙时进行转发。且这种模式下支持动态增加消费者,因为消息并没有发送出去,动态增加了消费者马上投入工作。而默认的转发机制会造成,即使动态增加了消费者,此时的消息已经分配完毕,无法立即加入工作,即使有很多未完成的任务。
6. 最终版本
发送端:
package com.zhy.rabbitMq._02_workqueue;
import java.io.IOException;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.MessageProperties;
public class NewTask
{
// 队列名称
private final static String QUEUE_NAME = "workqueue_persistence";
public static void main(String[] args) throws IOException
{
// 创建连接和频道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列
boolean durable = true;// 1、设置队列持久化
channel.queueDeclare(QUEUE_NAME, durable, false, false, null);
// 发送10条消息,依次在消息后面附加1-10个点
for (int i = 5; i > 0; i--)
{
String dots = "";
for (int j = 0; j <= i; j++)
{
dots += ".";
}
String message = "helloworld" + dots + dots.length();
// MessageProperties 2、设置消息持久化
channel.basicPublish("", QUEUE_NAME,
MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
// 关闭频道和资源
channel.close();
connection.close();
}
}
接收端:
package com.zhy.rabbitMq._02_workqueue;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.QueueingConsumer;
public class Work
{
// 队列名称
private final static String QUEUE_NAME = "workqueue_persistence";
public static void main(String[] argv) throws java.io.IOException,
java.lang.InterruptedException
{
// 区分不同工作进程的输出
int hashCode = Work.class.hashCode();
// 创建连接和频道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列
boolean durable = true;
channel.queueDeclare(QUEUE_NAME, durable, false, false, null);
System.out.println(hashCode
+ " [*] Waiting for messages. To exit press CTRL+C");
//设置最大服务转发消息数量
int prefetchCount = 1;
channel.basicQos(prefetchCount);
QueueingConsumer consumer = new QueueingConsumer(channel);
// 指定消费队列
boolean ack = false; // 打开应答机制
channel.basicConsume(QUEUE_NAME, ack, consumer);
while (true)
{
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(hashCode + " [x] Received '" + message + "'");
doWork(message);
System.out.println(hashCode + " [x] Done");
//channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
}
/**
* 每个点耗时1s
*
* @param task
* @throws InterruptedException
*/
private static void doWork(String task) throws InterruptedException
{
for (char ch : task.toCharArray())
{
if (ch == '.')
Thread.sleep(1000);
}
}
}















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









