






有多条线可以降低绝对误差,但只有一条线可以降低平方误差和
Sum of Squared Errors (SSE)
监督学习
决策树(ID3算法、信息熵[父节点的信息熵=1]、信息增益)
计算信息熵
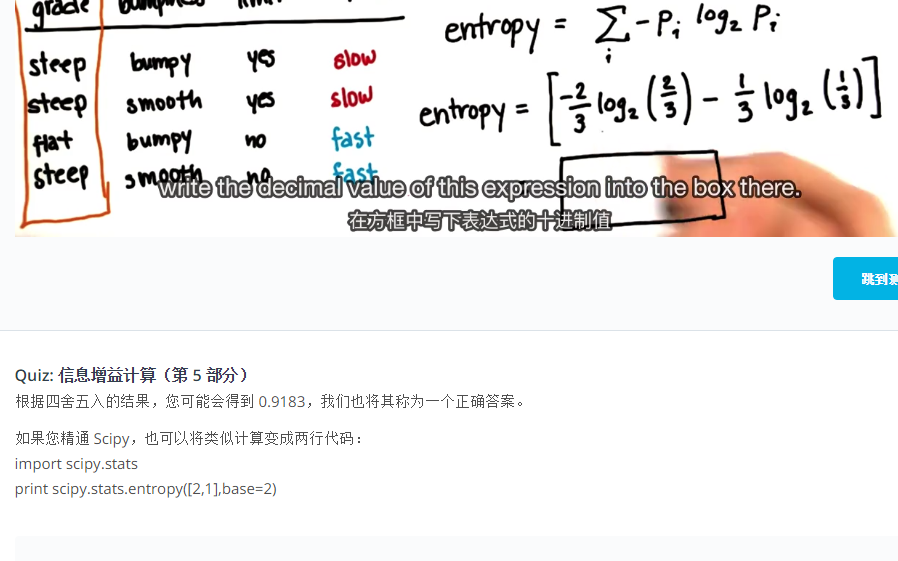
分类和回归
准确率的缺陷:
对于偏斜类(有很多样本点,但属于该类别的数目特别少)
绝不错杀一个
宁可天下人负我(试图找出所有相关人员)
模型可能出现的误差来自两个主要来源:
因模型无法表示基本数据的复杂度而造成的偏差
因模型对训练它所用的有限数据过度敏感而造成的方差
数据预处理五步走:
- 数据摘要 通过变量的特征快速了解数据结构 如变量的类型,非空值数量 简单统计量(均值、方差...)等
- 清洗变量 目的(保留尽量多的有效信息)类别变量-->数值变量,删掉冗余信息,填充NA等
- 拆分训练集合验证集 目的(为训练模型和交叉验证做准备)
- 训练模型
- 预测结果
交叉验证 主要是想通过模型的差异来抵消一部分模型本身的系统性误差,减小过拟合,增加总体稳健性














 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









