







常用的流操作
在stream使用之前,我们看下经常使用到的stream中的相关的操作。

在上表中,Stream的操作可以分为两大类:中间操作和结束操作,中间操作只是对操作进行了记录,只有结束操作才会真正的触发计算(惰性计算),这也是Stream在迭代大集合时高效的原因之一。这边和hadoop中mapreduce中的map/reduce思想有异曲同工的意思。
中间操作又可以分为无状态(stateless)操作和有状态操作(stateful),前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。结束操作又可以分为短路操作和非短路操作,这个很好理解,短路操作指的是找到符合条件的元素就结束本次迭代,非短路操作则是需要完全迭代结束才行。
原理探秘
在探究Stream的执行原理之前,我们先看以下两段代码。
代码1:
public static void main(String[] args) {
List<String> list = Lists.newArrayList(
"bcd", "cde", "def", "abc");
List<String> result = list.stream()
.filter(e -> e.length() >= 3)
.map(e -> e.charAt(0))
.map(e -> String.valueOf(e))
.collect(Collectors.toList());
System.out.println("----------------------------");
System.out.println(result);
}代码2:
public void targetMethod() {
List<String> list = Lists.newArrayList(
"bcd", "cde", "def", "abc");
List<String> result = Lists.newArrayListWithCapacity(list.size());
for (String str : list) {
if (str.length() >= 3) {
char e = str.charAt(0);
String tempStr = String.valueOf(e);
result.add(tempStr);
}
}
System.out.println("----------------------------");
System.out.println(result);
}我们可以看到,代码1和代码2的结果是一致的。那么Stream中是怎么处理的呢?我们观察一下代码2中的一些问题: 中间临时变量,不利于并行。
但是按照代码2的思路我们知道有以下几个问题需要解决:
1、如何记录每次操作
2、操作如何叠加
3、叠加后的操作如何执行
4、最后的结果如何存储
那么Stream中是如何解决以上的几个问题的呢?我们来看Stream中相关的代码:
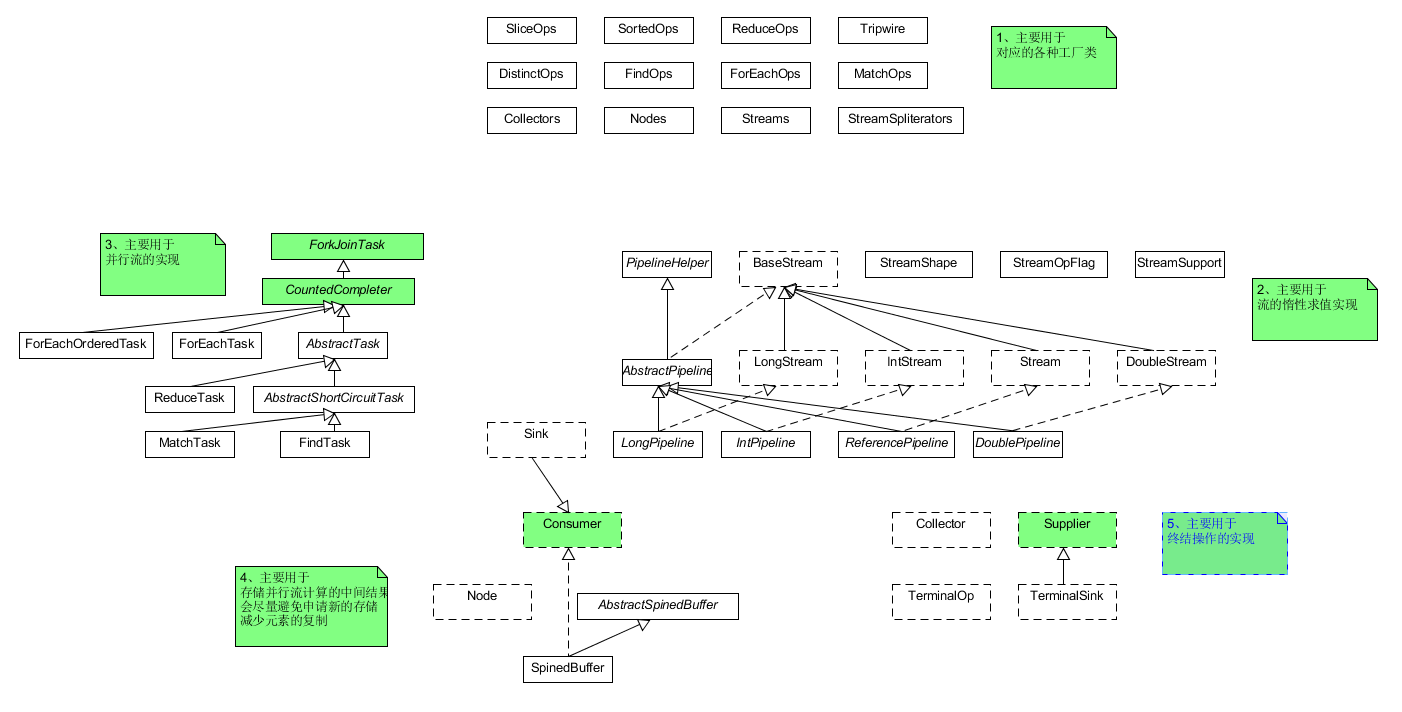
图1Stream包的结构示意图
其中各个部门的主要功能为:
1、主要是各个操作的工厂类、数据的存储结构以及收集器的工厂类等
2、主要用于Stream的惰性求值实现
3、Stream的并行计算框架
4、存储并行流的中间结果
5、终结操作的定义
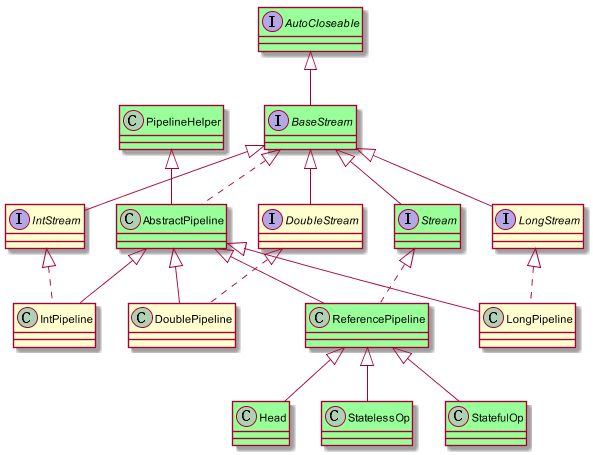
我们来看第二部分,Stream的惰性求值的实现。如下图所示:
1、BaseStream规定了流的基本接口,比如iterator,splitertor,isparallel等
2、Stream中定义了map,filter,flitermap等用户关注的常用操作
3、PiplineHelper主要用于Stream执行过程中相关结构的构建
4、Head、StatelessOp、StatefulOp为ReferencePipline中的内部类
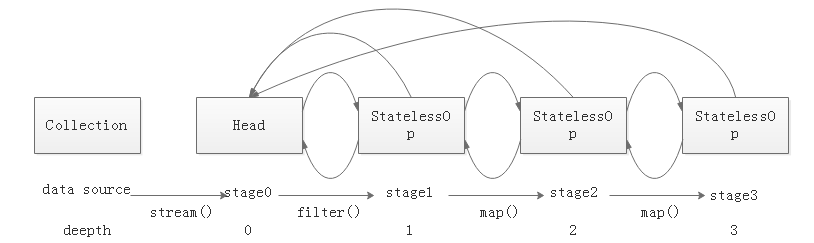
操作如何记录
在jdk中使用Stage来表示用户的一次操作,而通常情况下Stream的操作又需要一个回调函数,所以一个完整的操作由数据来源、操作、回调函数组成的三元组来表示。
我们来看Stream.map()方法的实现,Stream的map()的实现为RefrencePipline,我们来看代码的实现。
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}AbstractPipeline.AbstractPipeline()
/**
* Constructor for appending an intermediate operation stage onto an
* existing pipeline.
*
* @param previousStage the upstream pipeline stage
* @param opFlags the operation flags for the new stage, described in
* {@link StreamOpFlag}
*/
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage; //这里形成链表的数据结构
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}因此每调用一次中间操作,即往双向链表中增加一个尾节点。这里我们Stream就解决了记录每次操作的问题。
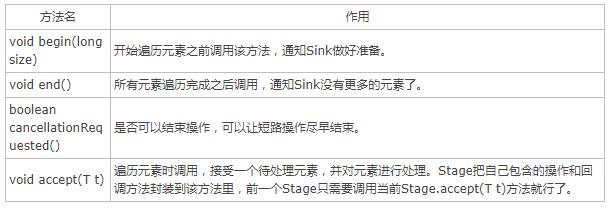
这里没有指明数据的来源,以及何时执行,如何执行的问题,JDK为此定义了一个Sink接口,其中有begin(),end(),cancellationRequested(),accept()四个方法
在stage中,每一步都包含了opWrapSink()的操作,形成了一个递归的调用。当调用终结操作的时候,将会从最后一个stage开始,递归调用。
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}这里需要注意下:Stage是从头到尾形成的双向链表结构,而Sink则是反过来,从终结操作开始,形成的递归的结构,从后向前,包装成一个大的Sink,最里面DownStream则是终结操作的Sink。如下图所示:

如何执行
当以上的数据结构都形成了之后,接下来便是终结操作触发数据的执行流转。
AbstractPipeline.copyInto()
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);//foreach调用sink中的accept的方法
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}由此我们可以了解了整个Stream的执行流程。
总结
Stream的数据流转主要由两部分组成,Stage标记每次的操作,Sink来真正传递数据,Sink附属在Stage对象中。Stream对象的触发,是终结操作的调用,其他中间操作只是创建stage对象。
PS:中间操作,有状态操作和无状态操作的区别:
eg:有状态的中间操作 distinct(),返回的是statefulOp,而不是之前的stateless
static <T> ReferencePipeline<T, T> makeRef(AbstractPipeline<?, T, ?> upstream) {
return new ReferencePipeline.StatefulOp<T, T>(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_DISTINCT | StreamOpFlag.NOT_SIZED) {
<P_IN> Node<T> reduce(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
// If the stream is SORTED then it should also be ORDERED so the following will also
// preserve the sort order
TerminalOp<T, LinkedHashSet<T>> reduceOp
= ReduceOps.<T, LinkedHashSet<T>>makeRef(LinkedHashSet::new, LinkedHashSet::add,
LinkedHashSet::addAll);
return Nodes.node(reduceOp.evaluateParallel(helper, spliterator));
}
@Override
<P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator,
IntFunction<T[]> generator) {
if (StreamOpFlag.DISTINCT.isKnown(helper.getStreamAndOpFlags())) {
// No-op
return helper.evaluate(spliterator, false, generator);
}
else if (StreamOpFlag.ORDERED.isKnown(helper.getStreamAndOpFlags())) {
return reduce(helper, spliterator);
}
else {
// Holder of null state since ConcurrentHashMap does not support null values
AtomicBoolean seenNull = new AtomicBoolean(false);
ConcurrentHashMap<T, Boolean> map = new ConcurrentHashMap<>();
TerminalOp<T, Void> forEachOp = ForEachOps.makeRef(t -> {
if (t == null)
seenNull.set(true);
else
map.putIfAbsent(t, Boolean.TRUE);
}, false);
forEachOp.evaluateParallel(helper, spliterator);
// If null has been seen then copy the key set into a HashSet that supports null values
// and add null
Set<T> keys = map.keySet();
if (seenNull.get()) {
// TODO Implement a more efficient set-union view, rather than copying
keys = new HashSet<>(keys);
keys.add(null);
}
return Nodes.node(keys);
}
}
//此处特意复写了次方法,是因为有状态的中间操作在并行处理的时候,需要进行特殊处理
@Override
<P_IN> Spliterator<T> opEvaluateParallelLazy(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
if (StreamOpFlag.DISTINCT.isKnown(helper.getStreamAndOpFlags())) {
// No-op
return helper.wrapSpliterator(spliterator);
}
else if (StreamOpFlag.ORDERED.isKnown(helper.getStreamAndOpFlags())) {
// Not lazy, barrier required to preserve order
return reduce(helper, spliterator).spliterator();
}
else {
// Lazy
return new StreamSpliterators.DistinctSpliterator<>(helper.wrapSpliterator(spliterator));
}
}
@Override
Sink<T> opWrapSink(int flags, Sink<T> sink) {
Objects.requireNonNull(sink);
if (StreamOpFlag.DISTINCT.isKnown(flags)) {
return sink;
} else if (StreamOpFlag.SORTED.isKnown(flags)) {
return new Sink.ChainedReference<T, T>(sink) {
boolean seenNull;
T lastSeen;
.........
在进行action触发的时候对于sourceSplitor会进行切分sourceSplitor,例如limit就会对sourceSplitor进行
AbstractPipeline.sourceSpliterator()
/**
* Get the source spliterator for this pipeline stage. For a sequential or
* stateless parallel pipeline, this is the source spliterator. For a
* stateful parallel pipeline, this is a spliterator describing the results
* of all computations up to and including the most recent stateful
* operation.
*/
@SuppressWarnings("unchecked")
private Spliterator<?> sourceSpliterator(int terminalFlags) {
// Get the source spliterator of the pipeline
Spliterator<?> spliterator = null;
if (isParallel() && sourceStage.sourceAnyStateful) {
// Adapt the source spliterator, evaluating each stateful op
// in the pipeline up to and including this pipeline stage.
// The depth and flags of each pipeline stage are adjusted accordingly.
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;
u != e;
u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
// Clear the short circuit flag for next pipeline stage
// This stage encapsulates short-circuiting, the next
// stage may not have any short-circuit operations, and
// if so spliterator.forEachRemaining should be used
// for traversal
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
spliterator = p.opEvaluateParallelLazy(u, spliterator);
................................
}















 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









