







Redis的持久化
我记得读研那会儿,我“老板”让我冒充老师去帮他参加一个本科生的答辩评审,当时有个大四学弟貌似在外实习,把在公司做的一个电商网站的代码改改作为毕设课题,有用到redis。当时我正好看了点redis,于是就问:“redis能做持久化吗?怎么做的?”学弟斩钉截铁的答道:“不可以老师,redis不能持久化,redis只能存内存,要持久化得用mysql”。于是,我心里呵呵,嘴上默许了(旁边还好坐了两个搞人工智能不懂redis的老师,所以我就不搞学弟难看了)。但是,官网上这么大的字啊!!!
https://redis.io/topics/persistence
redis是能够持久化的,你断电之后数据还是能回来,就表明redis通过某种机制实现了数据的持久化。并且,resdis的持久化提供了两种方式:RDB和AOF。
如果非要做个白话的开场白,那就打两个比方吧:
RDB就像巡逻队,每隔一段时间跑过来一下:“现在都有谁啊?“然后咔嚓,拍了个现在时刻的所有人(数据)的照片,走了。并且巡逻队长的巡逻频度,还有特定策略,比如人来往频繁(set数据频繁)他可能会很快回来巡视和拍个快照(这个对应于RDB的快照save策略的配置)。
AOF就是跟踪狂、你GF的私人侦探,你在做什么,他不管结果(数据本身),只全程偷偷记录下你的每个行为(添加和修改数的操作)。“happybks君从某时某刻开始,出门后先上车,再玩手机,再看对面的妹子,之后发呆,再玩手机,再看窗户外,然后下车。。。”AOF全程记录redis的所有行为过程,然后跑到GF面前展现 全过程(操作数据的行为),结果(数据本身)如何让你GF自己看完整个行为过程记录之后再定吧。
区别比较嘛,巡逻队(RDB)是每间断一段时间巡逻一次,所以如果出问题,可能会漏掉最后那一轮巡视之后的情况;跟踪狂(AOF)是全程拿小本子记录,所以可以想象,跟踪狂(AOF)所要消耗的精力(性能、空间等)要更大,当然能够不丢失什么信息。
我们还是看看其官网介绍:我就不翻译了,确实综述的很好。关于如何取舍,我们等到RDB和AOF两篇文章整理介绍完之后再做总结。
| Redis Persistence Redis provides a different range of persistence options:
The most important thing to understand is the different trade-offs between the RDB and AOF persistence.
Ok, so what should I use? The general indication is that you should use both persistence methods if you want a degree of data safety comparable to what PostgreSQL can provide you. If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone. There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine. Note: for all these reasons we'll likely end up unifying AOF and RDB into a single persistence model in the future (long term plan). |
本文我们先介绍RDB。
RDB(Redis DataBase)
官网介绍
| Let's start with RDB: RDB advantages
RDB disadvantages
|
RDB是什么
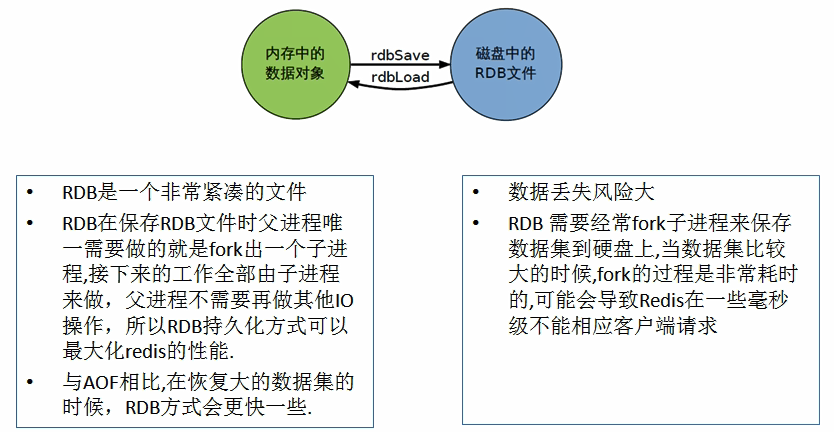
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
(本文出自oschina博主happybks的博文:https://my.oschina.net/happyBKs/blog/1579580)
这里插一句:查看redis进程,或者说任意一个进程有没有启动,有哪三种方法:
[hadoop@localhost ~]$ ps -ef | grep redis
root 7148 1 0 22:46 ? 00:00:00 /usr/local/bin/redis-server 127.0.0.1:6379
hadoop 7152 6399 0 22:46 pts/2 00:00:00 grep --color=auto redis
注意lsof命令这里必须用sudo权限,否则查不到。我们这里启动redis时用的是sudo权限。
[hadoop@localhost ~]$ sudo lsof -i :6379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 7148 root 4u IPv4 72218 0t0 TCP localhost:6379 (LISTEN)
[hadoop@localhost ~]$ netstat -a | grep 6379
tcp 0 0 localhost:6379 0.0.0.0:* LISTEN
Fork
前面提到了fork。
fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
为什么要这么做呢?因为你的redis时时刻刻都有可能在写数据,而如果此时一遍写一遍还在读取数据写到硬盘文件上,非常可能出现问题。毕竟平时我们自己读写个文件还需要加锁呢。redis这种应用高并发场景的东东显然不适合也弄个读写锁吧。所以,解决办法就是fork一个与自己一模一样的子进程,这个fork出来的子进程拥有和自己一模一样的数据,这样,一个进程继续维持服务,一个进程持久化数据到硬盘就不会有问题了。但是这样也带来一个问题,那就是内存的消耗会多出一倍。
RDB持久化的数据载体
rdb 保存的是dump.rdb文件
配置位置
快照save策略配置
配置文件中,有关RDB持久化的
快照策略的配置如下:
通过这样的配置项,配置每隔多少秒,此期间内redis中的数据被写或者修改达到多少次以后,触发一次持久化操作。
save 【每隔多少秒 | 在多少秒以内】 【写或者修改数据多少次】
可以有多个这样的save配置。
在默认配置中,
如果900秒内(15分钟)内如果写或改了1次数据,则生成一次快照;
如果在300秒(5分钟)内如果写或改了10次数据,则生成一次快照;
如果在60秒(1分钟)内如果写或改了10000次数据,则生成一次快照,。
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
下面我们来做个试验:
我们先将以前的dump文件删掉,再重启一下redis(启动了redis删除dump文件,之前的数据还是在的,所以要重启一样,干干净净)
[hadoop@localhost ~]$ sudo kill -9 7148
[sudo] password for hadoop:
[hadoop@localhost ~]$
[hadoop@localhost ~]$
[hadoop@localhost ~]$ ps -ef | grep redis
hadoop 13096 12154 0 22:28 pts/1 00:00:00 grep --color=auto redis
[hadoop@localhost ~]$
之后我们看一下时间,打开客户端,快速的在空空的0号库中输入10个键值对。
[hadoop@localhost ~]$ /usr/local/bin/redis-cli -p 6379
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> set k3 v3
OK
127.0.0.1:6379> set k4 v4
OK
127.0.0.1:6379> set k5 v5
OK
127.0.0.1:6379> set k6 v6
OK
127.0.0.1:6379> set k7 v7
OK
127.0.0.1:6379> set k8 v8
OK
127.0.0.1:6379> set k9 v9
OK
127.0.0.1:6379> set k10 v10
OK
127.0.0.1:6379>
127.0.0.1:6379> exit
[hadoop@localhost ~]$ date
Wed Nov 22 22:31:52 CST 2017
之后我们退出客户端,看看时间,还没到5分钟。
然后我们立即看看我们启动redis-server的所在目录:我是在用户目录下启动的。
[hadoop@localhost ~]$ ll
total 12
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents
drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Music
drwxrwxr-x. 2 hadoop hadoop 23 Nov 22 22:24 myconfig
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Pictures
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Public
drwxrwxr-x. 2 hadoop hadoop 63 May 9 2017 shellspace
drwxrwxr-x. 3 hadoop hadoop 74 Apr 17 2017 software
-rw-r--r--. 1 root root 187 Dec 24 2016 start_hdfs_yarn.sh
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Templates
-rw-r--r--. 1 root root 270 Dec 25 2016 testhdfs.sh
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Videos
我跑去玩玩手机,应该过了5分钟领了,回来再看:
[hadoop@localhost ~]$ ll
total 16
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents
drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads
-rw-r--r--. 1 root root 154 Nov 22 22:34 dump.rdb
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Music
drwxrwxr-x. 2 hadoop hadoop 23 Nov 22 22:24 myconfig
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Pictures
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Public
drwxrwxr-x. 2 hadoop hadoop 63 May 9 2017 shellspace
drwxrwxr-x. 3 hadoop hadoop 74 Apr 17 2017 software
-rw-r--r--. 1 root root 187 Dec 24 2016 start_hdfs_yarn.sh
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Templates
-rw-r--r--. 1 root root 270 Dec 25 2016 testhdfs.sh
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Videos
[hadoop@localhost ~]$
[hadoop@localhost ~]$ date
Wed Nov 22 22:39:25 CST 2017
看到没,已经有了dump.rdb文件了。
这里需要注意的是:
1. 这里需要注意的是,只有只有写、修改数据才会计数,进而判断是否生成快照。频繁的读取数据不会计入save策略。
2. 除了写和修改数据,save命令、flushall命令、shutdown命令等会立即生成快照。
3. 在真实的生产环境,生成的dump.rdb文件虽然备份了redis数据,但是将这个本分文件放在redis运行的主机上“同生共死”是不可想象的,所以,运维的同事一般会写个脚本或者存储过程,将最新生成的dump.rdb文件备份到另一个物理机或者其他更安全的地方。如果redis机器挂了,坏了,地震了,火灾了,只需要在另一个新的正常的环境中安这个dump.rdb文件恢复数据和服务就可以了。
save命令
如果在实际应用中,有些数据非常重要,我想这些数据写入后立即就能持久化备份一下,怎么办?
redis提供了一个save命令,注意是命令,不是刚才说的配置文件中快照save配置项。
127.0.0.1:6379> keys *
1) "k2"
2) "k8"
3) "k1"
4) "k5"
5) "k3"
6) "k4"
7) "k10"
8) "k7"
9) "k9"
10) "k6"
然后我们看看dump.rdb的日期时间:
[hadoop@localhost ~]$ ll
total 16
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents
drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads
-rw-r--r--. 1 root root 154 Nov 23 22:48 dump.rdb
之后我们写入一个键值对,此时dump.rdb并没有变
127.0.0.1:6379> set k3000 v3000
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k8"
3) "k1"
4) "k5"
5) "k3"
6) "k4"
7) "k3000"
8) "k10"
9) "k7"
10) "k9"
11) "k6"
127.0.0.1:6379>
但是我们调用save命令之后:
127.0.0.1:6379> save
OK
127.0.0.1:6379>
发现dump.rdb文件的时间就更新了。
[hadoop@localhost ~]$ ll
total 16
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Desktop
drwxr-xr-x. 2 hadoop hadoop 6 Nov 19 2016 Documents
drwxr-xr-x. 4 hadoop hadoop 4096 Nov 5 16:27 Downloads
-rw-r--r--. 1 root root 167 Nov 23 22:50 dump.rdb
另外,flushall也会立即生成快照,只不过,flushall的执行过程是,先清除所有数据,然后把空空如也的数据库的空数据生成一个快照,更新rdb文件。所以flushall之后,再启动redis服务后,数据仍然是空的,这也是理所当然的。
好,我们上一篇在介绍redis配置的时候列出了rdb快照相关的配置项大纲,我们重新以此为大纲梳理一下剩下的配置项。
SNAPSHOTTING快照
Save
save 秒钟 写操作次数
禁用 save ""
stop-writes-on-bgsave-error
rdbcompression
rdbchecksum
dbfilename
dir
stop-writes-on-bgsave-error
意思是如果生成快照的时候后台发生错误,redis要停止写。
如果配置成no,表示你不在乎数据不一致,或者你有其他的手段来发现和控制
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes
rdbcompression
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LFZ算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
rdbchecksum
在存储快照以后,还可以让redis使用CRC64算法进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望渠道最大的性能提升,可以关闭此功能。(对压缩后的数据做校验)
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
dbfilename
这个取名字的活儿,默认就好
# The filename where to dump the DB
dbfilename dump.rdb
dir
如上篇博文中介绍的,想要获取当前你启动redis服务的目录,也就是你目前每次持久化redis时dump.rdb文件保存的目录,可以通过 config get dir 来获取。
配置中默认配置的是当前相对路径。
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir ./
总结
如何触发RDB快照
配置文件中默认的快照配置
冷拷贝后重新使用(冷拷贝即运维从主机拷贝到备机上)
可以cp dump.rdb dump_new.rdb
命令save或者是bgsave
Save:save时只管保存,其它不管,全部阻塞
BGSAVE:Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave命令获取最后一次成功执行快照的时间
执行flushall命令,也会产生dump.rdb文件,但里面是空的,无意义
如何恢复
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
CONFIG GET dir 获取目录
优势
适合大规模的数据恢复
对数据完整性和一致性要求不高
劣势
在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。(如果你在最后一次dump后,趁下一轮备份还没开始,手贱把redis服务杀了,那么最后一次dump之后的数据修改就会丢失)
fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
如何停止
动态所有停止RDB保存规则的方法:redis-cli config set save "" (一般不这么做,虽然我们以后会用更常用的主从复制的方式来做,但是dump rdb的方式最好也做)
小总结
下一篇,我将整理redis持久化的另一种方式——AOF。















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









