









- 建树过程中如何选择使用哪个特征哪个值来进行分裂?
- 什么时候停止分裂?
- 如何计算叶节点的权值?
- 建完了第一棵树之后如何建第二棵树?
- 为防止过拟合,XGB做了哪些改进
树的集成
 本文主要针对xgboost的论文原文中的公式细节做了详细的推导,对建树过程进行详细分析。
对于样本个数为n特征个数为m的数据集
本文主要针对xgboost的论文原文中的公式细节做了详细的推导,对建树过程进行详细分析。
对于样本个数为n特征个数为m的数据集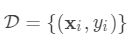 ,其中
,其中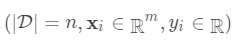 。
树的集成学习方法使用K个增量函数来预测输出:
。
树的集成学习方法使用K个增量函数来预测输出:
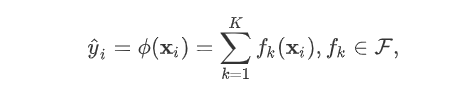
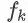 为子模型的预测函数,每个即是一棵树。
为子模型的预测函数,每个即是一棵树。
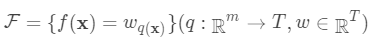 即树的搜索空间。其中q为每棵树的结构,q将
即树的搜索空间。其中q为每棵树的结构,q将
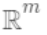 域
中每个样本对应到唯一的叶节点上,最终产生T个叶节点,
域
中每个样本对应到唯一的叶节点上,最终产生T个叶节点,
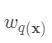 则是该叶节点对应的权重,w即从节点到权重的映射(权重即叶节点的值)。
每个
则是该叶节点对应的权重,w即从节点到权重的映射(权重即叶节点的值)。
每个
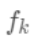 对应一个独立的树结构q和该树每个叶节点的权重w。
(这里树结构是指每个分裂点和对应的分裂值)。
对应一个独立的树结构q和该树每个叶节点的权重w。
(这里树结构是指每个分裂点和对应的分裂值)。
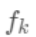 可以看做一个分段函数,q对应的不同的分段,w对应的为该分段的值,即分段到值的映射。
对我们的预测函数
可以看做一个分段函数,q对应的不同的分段,w对应的为该分段的值,即分段到值的映射。
对我们的预测函数
 ,目标函数为:
,目标函数为:
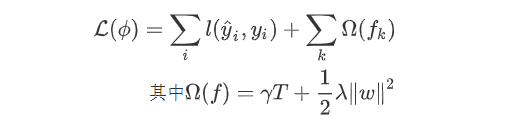 从公式1中可以看出,对于最终的预测函数
从公式1中可以看出,对于最终的预测函数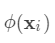 ,其参数为一个个的函数
,其参数为一个个的函数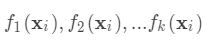 ,因为参数为函数,所以无法使用传统的优化方法在欧氏空间中进行优化,而是采用了加法模型来进行训练。
boost的思想是将一系列弱分类器串行的组合起来,在前面的分类器的基础上迭代的优化新的分类器。
,因为参数为函数,所以无法使用传统的优化方法在欧氏空间中进行优化,而是采用了加法模型来进行训练。
boost的思想是将一系列弱分类器串行的组合起来,在前面的分类器的基础上迭代的优化新的分类器。
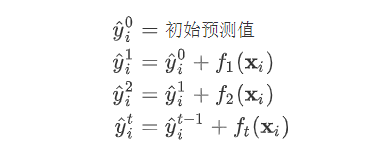 首先我们对所有的数据默认预测一个固定值
首先我们对所有的数据默认预测一个固定值
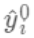 (对应xgboost中参数base_score,注意并不等于base_score,而是经过Sigmoid函数映射后的值),在此基础上根据该预测值与真实y值的损失 ,建立第一棵树
(对应xgboost中参数base_score,注意并不等于base_score,而是经过Sigmoid函数映射后的值),在此基础上根据该预测值与真实y值的损失 ,建立第一棵树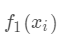 ,之后每次迭代时都是根据
其之前所有树做出的预测之和与真实y值的损失来建立新树。
也就是每次迭代建树时用新树来优化前一个树的损失 。
,之后每次迭代时都是根据
其之前所有树做出的预测之和与真实y值的损失来建立新树。
也就是每次迭代建树时用新树来优化前一个树的损失 。
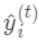 为第t棵树对第i个样本做出的预测。我们每次添加新树的时候,要优化的目标函数为上一个树产生的损失。
为第t棵树对第i个样本做出的预测。我们每次添加新树的时候,要优化的目标函数为上一个树产生的损失。
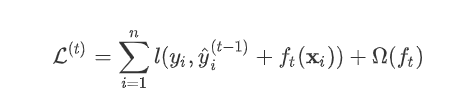
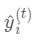 为新建的这棵树做出的预测,
为新建的这棵树做出的预测,
 为之前所有的树预测值之和,
为之前所有的树预测值之和,
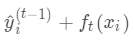 即是新建了当前这棵树后模型做出的预测值,求其与真实值
即是新建了当前这棵树后模型做出的预测值,求其与真实值
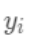 之间的损失(注意这里是损失不是残差,这里的
之间的损失(注意这里是损失不是残差,这里的
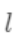 可以是log_loss, mse等)。
泰勒展开
可以是log_loss, mse等)。
泰勒展开
 gbdt的目标函数与xgboost区别就是带不带正则项,也就是上面式子中的
gbdt的目标函数与xgboost区别就是带不带正则项,也就是上面式子中的
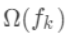 。
gbdt对损失函数的优化是直接使用了损失函数的负梯度,沿着梯度下降的方向来减小损失,其是也就是一阶泰勒展开。
而xgboost在这里使用了二阶泰勒展开,因为包含了损失函数的二阶信息,其优化的速度大大加快。
。
gbdt对损失函数的优化是直接使用了损失函数的负梯度,沿着梯度下降的方向来减小损失,其是也就是一阶泰勒展开。
而xgboost在这里使用了二阶泰勒展开,因为包含了损失函数的二阶信息,其优化的速度大大加快。
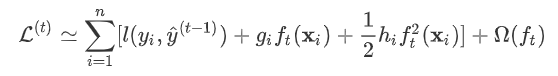 下面来看一下泰勒展开的推导。首先我们来复习一下泰勒定理:
设n是一个正整数。如果定义在一个包含a的区间上的函数f在a点处n+1次可导,那么对于这个区间上的任意x,则有:
下面来看一下泰勒展开的推导。首先我们来复习一下泰勒定理:
设n是一个正整数。如果定义在一个包含a的区间上的函数f在a点处n+1次可导,那么对于这个区间上的任意x,则有: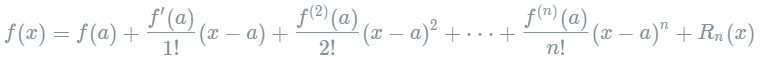 其中的多项式称为函数在a处的泰勒展开式,剩余的
其中的多项式称为函数在a处的泰勒展开式,剩余的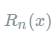 是泰勒公式的余项,是
是泰勒公式的余项,是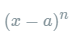 的高阶无穷小。
该公式经过变换
的高阶无穷小。
该公式经过变换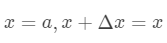 可以得到二阶展开式:
可以得到二阶展开式:
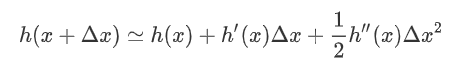 对于式子:
对于式子:
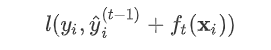 可以这样分析,
可以这样分析,
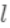 为预测值
为预测值
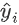 和真实值
和真实值
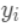 之间的损失,
为常量,因此是以预测值为自变量的函数,当建立新树给出新的预测
之间的损失,
为常量,因此是以预测值为自变量的函数,当建立新树给出新的预测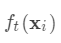 后,相当于在上一次的预测
后,相当于在上一次的预测
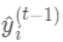 上增加了一个无穷小量
令
上增加了一个无穷小量
令
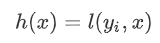 则有
则有
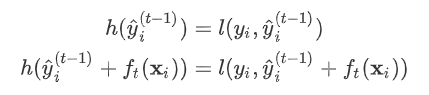 其中真实标签是常数,
其中真实标签是常数,
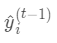 是上次迭代求出的值即这里的
是上次迭代求出的值即这里的
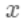 ,
为无穷小量
,
为无穷小量
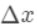 。
有了这个对应之后。
。
有了这个对应之后。
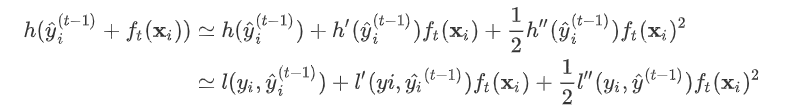 因此我们建立第t棵树时有损失函数:
因此我们建立第t棵树时有损失函数:
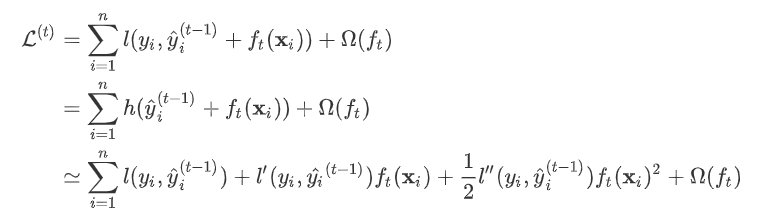 令损失函数的一阶、二阶偏导分别为
令损失函数的一阶、二阶偏导分别为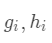 ,其中
,其中
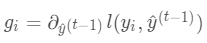 ,
,
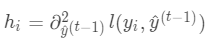
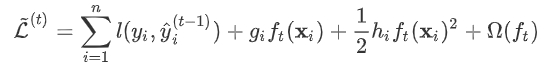 式中
式中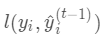 为常量,优化的是损失函数的最小值,因此常量值可以从损失函数中去掉。上式可简化为:
为常量,优化的是损失函数的最小值,因此常量值可以从损失函数中去掉。上式可简化为:
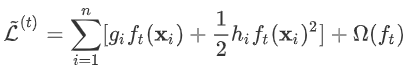
叶节点权重
 式中正则项
式中正则项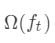 进行展开,得:
进行展开,得:
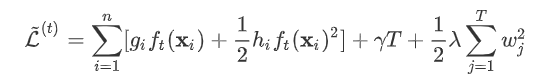 其中是新建的树的值,对于每个样本来说,就是对应的叶节点的权重
其中是新建的树的值,对于每个样本来说,就是对应的叶节点的权重
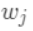 。定义
。定义
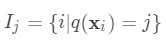 为分到叶节点
为分到叶节点
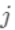 的样本(叶节点
总数为T,样本总数为n)
上式是对本次建树时n个样本的损失求和,下面分两步:先对每个叶节点的样本损失求和,再对所有叶节点求和,两者结果一样。
的样本(叶节点
总数为T,样本总数为n)
上式是对本次建树时n个样本的损失求和,下面分两步:先对每个叶节点的样本损失求和,再对所有叶节点求和,两者结果一样。
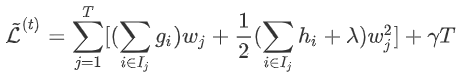 对于叶节点上的损失:
对于叶节点上的损失:
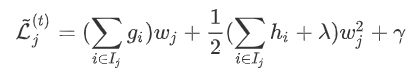 对于当前的树结构求
对于当前的树结构求
 使
使
 最小,显然这是
个一元二次方程求最小值问题。
最小,显然这是
个一元二次方程求最小值问题。
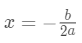 可以得到叶节点权重的最优值:
可以得到叶节点权重的最优值:
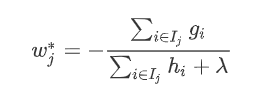
分裂准则
 上
面是对
单个叶节点计算出
了最优权重,对于新建的这树(树结构
上
面是对
单个叶节点计算出
了最优权重,对于新建的这树(树结构
 )在此权重下对应的的最小损失为每个叶节点上样本最小损失之和(将上式中的
)在此权重下对应的的最小损失为每个叶节点上样本最小损失之和(将上式中的
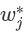 代入):
代入):
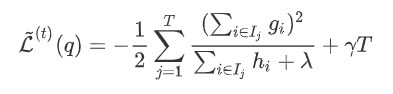 在树结构下产生的最优损失
在树结构下产生的最优损失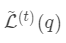 可以做为树结构的评价函数,也就是作为树分裂时候的评价指标。
令
可以做为树结构的评价函数,也就是作为树分裂时候的评价指标。
令
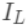 为每次分裂时分到左子树上的样本,
为每次分裂时分到左子树上的样本,
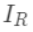 为每次分裂时分到右子树上的样本,有
为每次分裂时分到右子树上的样本,有
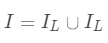 。
则在该次分裂后损失的减小量为:
。
则在该次分裂后损失的减小量为:
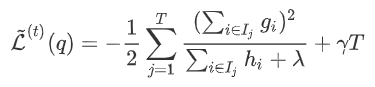 因此将分裂时增益定义为:
因此将分裂时增益定义为:
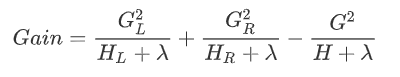 我们在建树的过程(也就是求分段函数的过程)包括两步:一是选择分裂依据的特征和特征值(将自变量分段),二是确定叶节点的权重(确定每段对应的函数值)。划分的依据准则是Gain,其实也就是损失函数的解析解,划分后叶节点的权重是使函数达到解析解的权重。
从最优化的角度来看:GBDT采用的是数值优化的思维, 用的最速下降法去求解Loss Function的最优解, 其中用CART决策树去拟合负梯度, 用牛顿法求步长。XGboost用的解析的思维, 对Loss Function展开到二阶近似, 求得解析解, 用解析解作为Gain来建立决策树, 使得Loss Function最优.
我们在建树的过程(也就是求分段函数的过程)包括两步:一是选择分裂依据的特征和特征值(将自变量分段),二是确定叶节点的权重(确定每段对应的函数值)。划分的依据准则是Gain,其实也就是损失函数的解析解,划分后叶节点的权重是使函数达到解析解的权重。
从最优化的角度来看:GBDT采用的是数值优化的思维, 用的最速下降法去求解Loss Function的最优解, 其中用CART决策树去拟合负梯度, 用牛顿法求步长。XGboost用的解析的思维, 对Loss Function展开到二阶近似, 求得解析解, 用解析解作为Gain来建立决策树, 使得Loss Function最优.

除了对目标函数添加正则项外,为了减小过拟合,xgboost还使用了列采样和缩减方法(Shrinkage,即Learning rate)。
损失函数计算
 对于二分类问题常使用负log损失作为损失函数,下面推导一下log loss的一阶梯度G和海森矩阵H。
对于二分类问题常使用负log损失作为损失函数,下面推导一下log loss的一阶梯度G和海森矩阵H。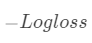 :
:
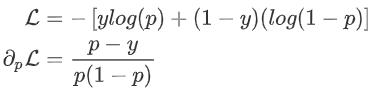 其中p为预测概率。
若
其中p为预测概率。
若
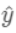 为预测值,则有:
为预测值,则有:
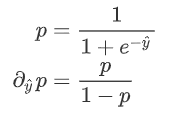 因此:
因此:
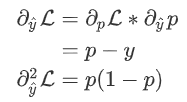 即:
即:
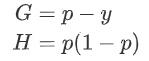

网络人工智能园地,力求打造网络领域第一的人工智能交流平台,促进华为iMaster NAIE理念在业界(尤其通信行业)形成影响力!

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









