






PE文件是Win32的原生文件格式.每一个Win32可执行文件都遵循PE文件格式.对PE文件格式的了解可以加深你对Win32系统的深入理解.
一、 基本结构。

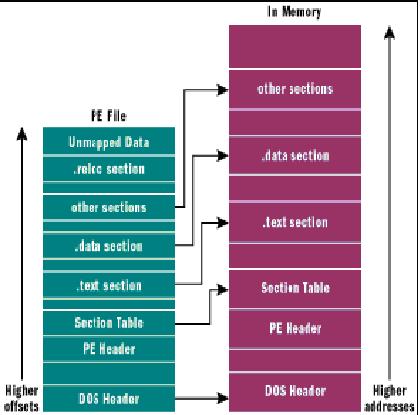
上图便是PE文件的基本结构。(注意:DOS MZ Header和部分PE header的大小是不变的;DOS stub部分的大小是可变的。)
一个PE文件至少需要两个Section,一个是存放代码,一个存放数据。NT上的PE文件基本上有9个预定义的Section。分别是:.text, .bss, .rdata, .data, .rsrc, .edata, .idata, .pdata, 和 .debug。一些PE文件中只需要其中的一部分Section.以下是通常的分类:
l 执行代码Section , 通常命名为: .text (MS) or CODE (Borland)
l 数据Section, 通常命名为:.data, .rdata, 或 .bss(MS) 或 DATA(Borland).
l 资源Section, 通常命名为:.edata
l 输入数据Section, 通常命名为:.idata
l 调试信息Section,通常命名为:.debug
这些只是命名方式,便于识别。通常与系统并无直接关系。通常,一个PE文件在磁盘上的映像跟内存中的基本一致。但并不是完全的拷贝。Windows加载器会决定加载哪些部分,哪些部分不需要加载。而且由于磁盘对齐与内存对齐的不一致,加载到内存的PE文件与磁盘上的PE文件各个部分的分布都会有差异。
当一个PE文件被加载到内存后,便是我们常说的模块(Module),其起始地址就是所谓的HModule.
二、 DOS头结构。
所有的PE文件都是以一个64字节的DOS头开始。这个DOS头只是为了兼容早期的DOS操作系统。这里不做详细讲解。只需要了解一下其中几个有用的数据。
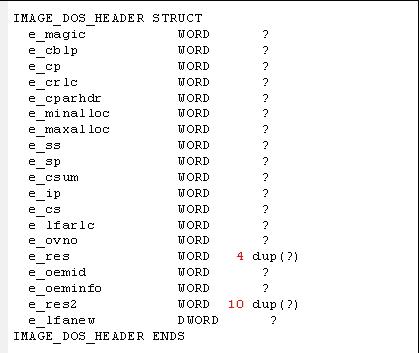
1. e_magic:DOS头的标识,为4Dh和5Ah。分别为字母MZ。
2. e_lfanew:一个双字数据,为PE头的离文件头部的偏移量。Windows加载器通过它可以跳过DOS Stub部分直接找到PE头。
3. DOS头后跟一个DOS Stub数据,是链接器链接执行文件的时候加入的部分数据,一般是“This program must be run under Microsoft Windows”。这个可以通过修改链接器的设置来修改成自己定义的数据。
三、 PE头结构。
PE头的数据结构被定义为IMAGE_NT_HEADERS。包含三部分:
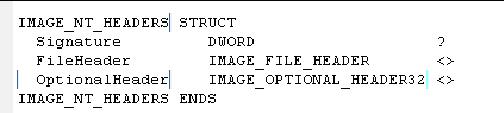
1. Signature:PE头的标识。双字结构。为50h, 45h, 00h, 00h. 即“PE”。
2. FileHeader:20字节的数据。包含了文件的物理层信息及文件属性。

这里主要注意三项。
l NumberOfSections:定义PE文件Section的个数。如果对PE文件新增或删除Section的话,一定要记的修改此域。
l SizeOfOptionalHeader:定义OptionHeader结构的大小。
l Characteristics:主要用来标识当前的PE文件是执行文件还是DLL。其各位都有具体的含义。
数据位
Windows.inc的预定义
为1时的含义
0
IMAGE_FILE_RELOCS_STRIPPED
文件中不存在重定位信息
1
IMAGE_FILE_EXECUTABLE_IMAGE
文件是可执行的
2
IMAGE_FILE_LINE_NUMS_STRIPPED
不存在行信息
3
IMAGE_FILE_LOCAL_SYMS_STRIPPED
不存在符号信息
7
IMAGE_FILE_BYTES_REVERSED_LO
小尾方式
8
IMAGE_FILE_32BIT_MACHINE
只在32位平台运行
9
IMAGE_FILE_DEBUG_STRIPPED
不包含调试信息
10
IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP
不能从可移动盘运行
11
IMAGE_FILE_NET_RUN_FROM_SWAP
不能从网络运行
12
IMAGE_FILE_SYSTEM
系统文件。不能直接运行
13
IMAGE_FILE_DLL
DLL文件
14
IMAGE_FILE_UP_SYSTEM_ONLY
文件不能在多处理器上运行
15
IMAGE_FILE_BYTES_REVERSED_HI
大尾方式
3. OptionalHeader:总共224个字节。最后128个字节为数据目录(Data Directory)。

以下是字段的说明:
l AddressOfEntryPoint:程序入口点地址。但加载器要运行加载的PE文件时要执行的第一个指令的地址。它是一个RVA(相对虚拟地址)地址。一些对PE文件插入代码的程序就是修改此处的地址为要运行的代码,然后再跳转回此处原来的地址。
l ImageBase:PE文件被加载到内存的期望的基地址。对于EXE文件,通常加载后的地址就期望的地址。但是DLL却可能是其他的。因为如果这个地址被占,系统就会重新分配一块新的内存,同时会修改此处加载后的地址。EXE文件通常是400000h.
l SectionAlignment:每一个Section的内存对齐粒度。比如:此值为4096(1000h),那么每一个Section的起始地址都应该是4096(1000h)的整数倍。如果第一个Section的地址是401000h,大小为100个字节。那么下一个Section的起始地址为402000h.。两个Section之间的空间大部分是空的,未用的。
l FileAlignment:每一个Section的磁盘对齐粒度。比如,此值为512(200h),那么每一个Section在文件内的偏移位置都是512(200h)的整数倍。与SectionAlignment同理。
l SizeOfImage:PE文件在内存空间整个映像的大小。包含所有的头及按SectinAlignment对齐的所有的Section。
l SizeOfHeaders:所有的头加上Section表的大小。也就是文件大小减去文件中所有Section的大小。可以用这个值获取PE文件中第一Section的位置。
l DataDiretory:16个IMAGE_DATA_DIRECTORY结构的数组。每一个成员都对应一个重要的数据结构,比如输入表,输出表等。
有两个地方需要注意:
l 如果PE header里的最后两个字段被赋予一个伪造的值的话,比如:
n LoaderFlags = ABDBFFFFh (其默认值为0)
n NumberOfRvaAndSizes = DFFDEEEEh (其默认值为10h)
一些调试工具或反编译工具会认为这个PE文件是损坏的。有的会直接执行,如果是病毒的话,就会被直接感染;有的则会重启工具。所以最好在查看调试一个PE文件前,先看一下这里的取值是否被人赋予一个伪造的很大的值。如果是的话,先修改成默认的值。
l 有人可能注意到在一些PE文件(MS的链接器链接的PE文件)的DOS Stub部分跟PE header部分之间存在一部分垃圾数据。标识为其倒数第二非0的双字节是一个“Rich ”。这部分数据包含了一些加密数据,来标识编译这个PE文件的组件。可用来检举某些病毒程序所编译的程序来自哪台机器。

四、 数据目录结构(Data Directory)。
DataDirectory是OptionalHeader的最后128个字节,也是IMAGE_NT_HEADERS的最后一部分数据。它由16个IMAGE_DATA_DIRECTORY结构组成的数组构成。IMAGE_DATA_DIRECTORY的结构如下:

每一个IMAGE_DATA_DIRECTORY都是对应一个PE文件重要的数据结构。他们分别如下:
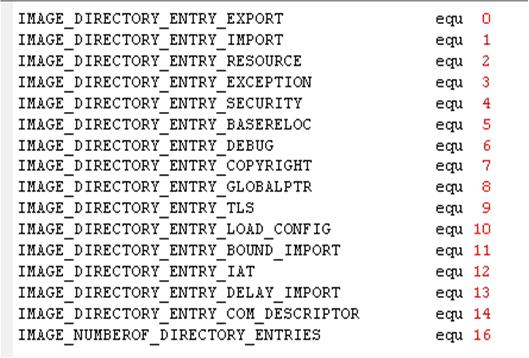
VirtualAddress指的是对应数据结构的RVA地址;iSize指的是对应数据结构的大小(字节单位)。一个PE文件一般只包含其中的一部分,也就是其中一部分数据结构是有数据的;另一部分则都是0。比如,EXE文件一般都存在IMAGE_DIRECTORY_ENTRY_IMPORT(输入表),而不存在IMAGE_DIRECTORY_ENTRY_EXPORT(输出表)。而DLL则两者都包含。下图就是某一个PE文件的数据目录:
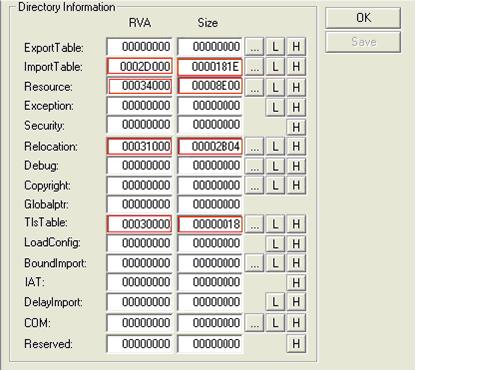
五、 Section表。
Section表紧跟在PE header后面。由IMAGE_SECTION_HEADER数据结构组成的数组。每一个包含了对应Section在PE文件中的属性和偏移位置。
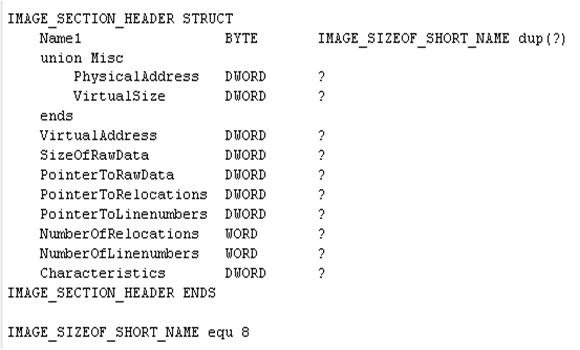
这里不是所有的成员都是有用的。
l Name1: 块名,这是一个8位ASCII码名,用来定义块名。多数块名以一个"."开始(如.text),尽管许多PE文档都认为这个"."实际上并不是必须的。值得注意的是,如果块名超过8位,则最后的NULL不存在。带有一个"$"的区块名字会从链接器那里得到特殊的对待,前面带"$"的相同名字的区块被合并,在合并后的区块中它们是按"$"后面的字符字母顺序进行合并的。
l Misc.VirtualSize : 指出实际的、被使用的区块大小。如果VirtualSize大于SizeOfRawData,那么SizeOfRawData来自于可执行文件初始化数据的大小,与VirtualSize相差的字节用0填充。这个字段在OBJ文件中设为0。
l VirtualAddress : 该块装载到内存中的RVA。这个地址是按照内存页对齐的,它的数值总是SectionAlignment的整数倍。在MS工具中,第一块的默认RVA为1000H.在OBJ中,该字段没意义。如果该值为1000H, PE文件被加载到400000H,那么该Section的起始地址为401000H。
l SizeOfRawData : 该块在磁盘文件中所占的大小。在可执行文件中,这个值必须是PE头部指定的文件对齐大小的倍数。如果是0,则说明区块中的数据是未初始化的。该块在磁盘文件中所占的大小,这个数值等于VirtualSize字段的值按照FileAlignment的值对齐以后的大小。例如,FileAlignment的大小为1000H,如果VirtualSize中的块长度为2911,则SizeOfRawData为3000H}
l PointerToRawData : 该块在磁盘文件中的偏移。对于可执行文件,这个值必须是PE头部指定的文件对齐大小的倍数。
l PointerToRelocations : 这部分在EXE文件中无意义。在OBJ文件中,表示本块重定位信息的偏移量。在OBJ文件中如果不是零,则会指向一个IMAGE_RELOCATION的数据结构。
l NumberOfRelocations : 由PointerToRelocations指向的重定位的数目。
l NumberOfLinenumbers : 由NumberOfRelocations指向的行号的数目,只在COFF样式的行号被指定时使用。
l Characteristics : 块属性,该字段是一组指出块属性(如代码/数据/可读/可写等)的标志。多个标志值通过OR操作形成Characteristics的值。这些标志很多都可以通过链接器/SECTION选项设置。
位
数据位在Windows.inc中的预定义
为1时的含义
5
IMAGE_SCN_CNT_CODE (00000020H)
节中包含代码
6
IMAGE_SCN_CNT_INITIALIZED_DATA (00000040H)
节中包含已初始化数据
7
IMAGE_SCN_CNT_UNINITIALIZED_DATA (00000080H)
节中包含未初始化数据
25
IMAGE_SCN_MEM_DISCARDABLE (02000000H)
节中的数据在进程开始后将被丢弃
26
IMAGE_SCN_MEM_NOT_CACHED (04000000H)
节中的数据不会经过缓存
27
IMAGE_SCN_MEM_NOT_PAGED (08000000H)
节中的数据不会被交换到磁盘
28
IMAGE_SCN_MEM_SHARED (10000000H)
节中的数据将被不同的进程所共享
29
IMAGE_SCN_MEM_EXECUTE (20000000H)
映射到内存后的页面包含可执行属性
30
IMAGE_SCN_MEM_READ (40000000H)
映射到内存后的页面包含可读属性
31
IMAGE_SCN_MEM_WRITE (80000000H)
映射到内存后的页面包含可写属性
六、 PE文件各个Section。
PE文件的Sections部分包含了文件的内容。包括代码,数据,资源和其他可执行信息。每一个Section由一个头部和一个数据部分组成。所有的头部都存放在紧跟PE header后的Section表内。
1. 执行代码。
在NT Windows系统内,所有的PE文件的代码段都存放在一个Section内,通常命名为.text(MS)或CODE(Borland)。这一段包含了早先提起的AddressOfEntryPoint多指地址的指令及输入表中的jump thunk table。
2. 数据。
l .bss段存放未初始化的数据,包括函数内或源模块内声明的静态变量。
l .rdata段存放只读数据,比如常字符串,常量,调试指示信息。
l .data 段存放其他所有的数据(除了自动化变量,其存放在栈中)。比如程序的全局变量。
3. 资源。
.rsrc段包含了一个模块的资源信息。以资源树的结构存放数据。需要用工具来查看。
4. 输出数据。
.edata段包含了PE文件的输出目录(Export Directory)。
5. 输入数据。
.idata包含了PE文件的输入目录和输入地址表。
6. 调试信息。
调试信息存放在.debug段。PE文件也支持单独的调试文件。Debug段包含调试信息,但是调试目录却存放在.rdata内。
7. 线程局部存储。(TLS)
Windows支持每一个进程包含多个线程。每一个线程有其私有的存储空间(TLS)去存放线程自身的数据。链接器都会为进程创建一个.tls段来存放TLS模板。当进程创建一个线程时,系统就会按照这个模板创建一个线程私有的局部存储空间。
8. 基重定位。
当加载器加载PE文件到内存的时候,有时候不一定是其预期的基地址。那么就需要调整内部指令的相对地址。所有需要调整的地址都存放在.reloc段内。
七、输出Section.
这个Section跟DLL关系比较密切。DLL一般定义两种函数,内部使用的,和输出到外部给其他调用程序使用的。输出到外部的函数就存储在这个Section内。
DLL输出函数分两种方式,通过名称和通过序号输出。当其他程序需要调用DLL的时候,调用GetProcAddress,通过设置需要调用的函数名称或函数序号可以调用DLL内部输出的函数。
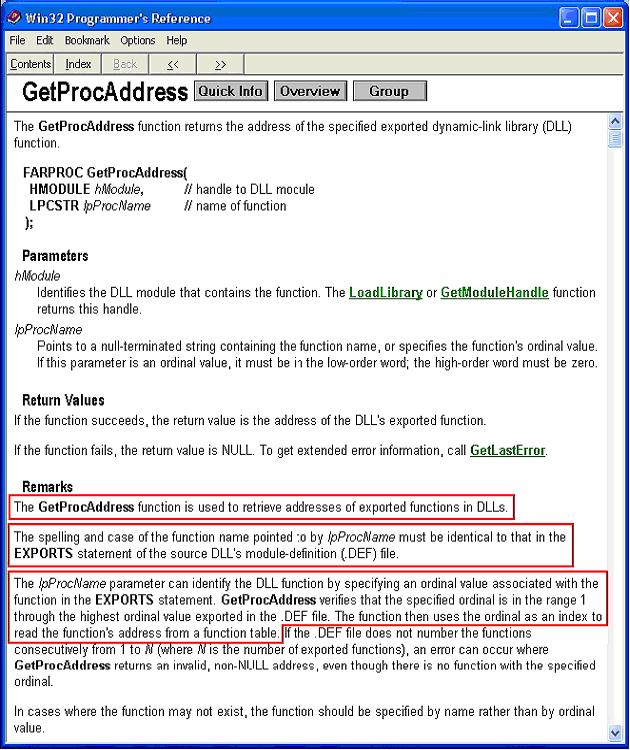
那么GetProcAddress是怎么获取DLL中真正的输出函数地址呢?以下是详细的解说。
PE头的数据目录(DATA DIRECTORY)数组的第一个成员对应的(通过其中的RVA地址可获得)数据结构是IMAGE_EXPORT_DIRECTORY(这里称为输出目录)。
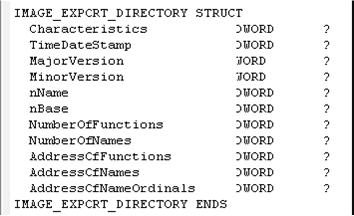
成员
大小
描述
Characteristics
DWORD
未定义,总是0
TimeDateStamp
DWORD
输出表的创建时间。与IMAGE_NT_HEADER.FileHeader.TimeDateStamp有相同的定义
MajorVersion
WORD
输出表的主版本号。未使用,为0
MinorVersion
DWORD
输出表的次版本号。未使用,为0
nName
DWORD
指向一个ASCII字符串的RVA,这个字符串是与这些输出函数关联的DLL的名称(比如,Kernel32.dll)。这个值必须定义,因为如果DLL文件的名称如果被修改,加载器将使用这里的名称。
nBase
DWORD
这个字段包含用于这个可执行文件输出表的起始序数值(基数)。正常情况下为1,但不是一定是。当通过序数来查询一个输出函数时,这个值会被从序数里减去。(比如,如果nBase = 1,被查询的函数的序数是3,那么这个函数在序号表的索引是3 -1 = 2)。
NumberOfFunctions
DWORD
输出地址表(EAT)的条目数。其中一些条目可能是0,意味着这个序数值没有代码和数据输出。
NumberOfNames
DWORD
输出名称表(ENT)的条目数。这个值总是大于或等于NumberOfFunctions。小于的情况发生在符号只通过序数来输出时。另外,当被赋值的序数里有数字间隔时也会有小于的情况。这个值也是输出序数表的长度。
AddressOfFunctions
DWORD
输出地址表(EAT)的RVA。输出地址表本身是一个RVA数组,数组中的每一个非零的RVA都对应一个被输出的符号。
AddressOfNames
DWORD
输出名称表(ENT)的RVA。输出名称表本身是一个RVA数组。数组中的每一个非零的RVA都向一个ASCII字符串。每一个字符串都对应一个通过名称输出的符号。这个表是排序。这允许加栽器在查询一个被输出的符号时可用二进制查找方式。名称的排序是二进制的,而不是按字母。
AddressOfNameOrdinals
DWORD
输出序数表(EOT)的RVA。这个表将ENT中的数组索引映射到相应的输出地址条目。
实际上,IMAGE_EXPORT_DIRECTORY结构指向三个数组和一个ASCII字符串表。其中重要的是输出地址表(EAT,即AddressOfFunctions指向的表), 输出函数地址指针(RVA)构成了这个表。而ENT和EOT则是可以一起合作来获取EAT里对应的地址数据。下图演示了这个过程。
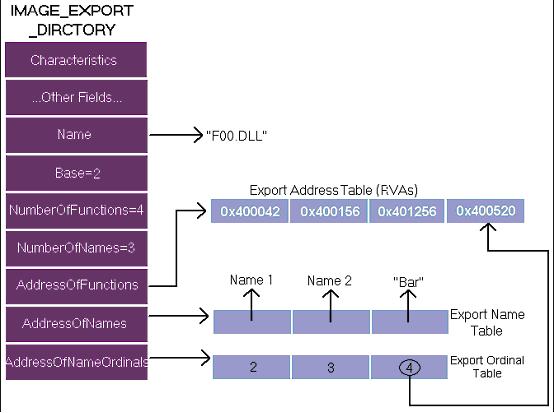
这个被加载的DLL的名称是F00.DLL。总共输出了四个函数,其RVA地址分别为0x400042、0x400156、0x401256和0x400520。一个外部调用程序需要调用其中一个名为”Bar”的函数,那么它先在输出名称表(ENT)里查找名称为Bar的函数,找到后,根据其在输出序号表(EOT)中对应的索引号,获取其中的数值为EAT中的索引值,这里是4,然后从EAT中根据索引4获取其真正的RVA地址0x400520。以下是几个注意点:
l 输出序号表(EOT)的存在就是为了是EAT跟ENT之间产生关联。每一个ENT内的成员(函数名)有且只有一个EAT内的成员(函数地址)对应。但是一个EAT内的成员并不是只有一个ENT内的成员对应。比如,有的函数存在别名的话,就会出现多个ENT内的成员都对应一个EAT内的成员。
l 如果已经获得一个函数的序号值,那么就可以直接到EAT内获得其RVA地址,而不需要经过ENT和EOT进行查找。但是这样的按序号输出的DLL不易于维护。
l 通常情况下,EAT的个数(NumberOfFunctions)必须小于或等于ENT的个数(NumberOfNames)。只有在一个函数按序号输出时(其在ENT和EOT表里没有对应的数据),ENT的数量才有可能少于EAT的数量。比如,总共有70个函数输出,但是在ENT表里只有40个,这就意味着剩余的30个函数是靠序号输出的。那么我们如何知道哪些是直接靠序号输出的呢?只有通过排除法来获得。把存在在EOT表里的序号从EAT里排除出去,剩下的就是靠序号输出的函数。
l 当通过一个序号值来获取EAT内的函数RVA时,需要把这个序号值减去nBase的值来获取在EAT表里真正的索引位置。而通过名称查找则不需要这么做。
l 输出转向。某些时候,你从一个DLL中调用的一个函数可能位于另一个DLL中。这就叫输出转向。比如,Kernel32.dll中的HeapAlloc就是转到调用NTDLL.dll中的RtlAllocHeap。这种转向是在链接的时候,在.DEF文件中定义一个特殊的指令来实现的。那么当一个函数被转向后,在其所在EAT表里对应的数据便不是其地址,而是一个指向表明被转向的DLL和函数的ASCII字符串的地址指针。
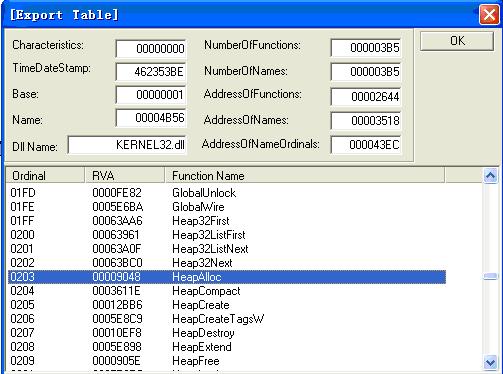
上图就是Kernel32.dll的输出函数表,其中HeapAlloc的RVA值0x00009048就是一个指向“NTDLL.RtlAllocHeap”的指针。
八 、 输入Section.
输入Section通常位于.idata段内。它包含了所有程序需要用到的来自其他DLL的函数的信息。Windows加载器负责加载所有程序用到的DLL到进程空间。然后为进程找到所有其需要用到的函数的地址。下面描述这个过程:
PE头的数据目录(DATA DIRECTORY)数组的第二个成员对应的(通过其中的RVA地址可获得)数据结构是输入表。输入表是一个 IMAGE_IMPORT_DESCRIPTOR数据结构的数组。没有字段表明这个数组的个数,只是它的最后一个成员的数据都为0。每一个数组成员都对应 一个DLL。

成员
大小
描述
OriginalFirstThunk
DWORD
指向输入名称表(INT)的RVA。INT是由IMAGE_THUNK_DATA数据结构构成的数组。数组中的每一个成员定义了一个输入函数的信息,数组最后以一个内容为0的IMAGE_THUNK_DATA结束。
TimeDateStamp
DWORD
当执行文件不与被输入的DLL进行绑定时,这个字段为0。当以旧的方式绑定时,这个字段包括时间/日期。当以新的样式绑定时,这个字段为-1。
ForwarderChain
DWORD
这是第一个被转向的API的索引。老样式绑定的定义。
Name
DWORD
指向被输入DLL的ASCII字符串的RVA。
FirstThunk
DWORD
指向输入地址表(IAT)的RVA。IAT也是一个IMAGE_THUNK_DATA数据结构的数组。
由上表可知,输入表主要是通过IMAGE_THUNK_DATA这个数据结构导入函数。下面是IMAGE_THUNK_DATA的描述:
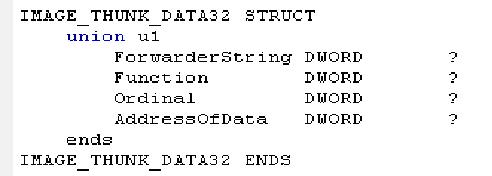
这是一个DWORD联合体数据结构。其实这里对输入表有意义的字段只有两个,Ordinal和 AddressOfData。当这个DWORD数据的最高位为1的时候,代表函数以序号的方式导入,Ordinal的低31位就是输入函数在其DLL内的 导出序号。当这个DWORD的数据最高位为0的时候,代表函数以字符串方式导入。AddressOfData就是一个指向用来导入函数名称的 IMAGE_IMPORT_BY_NAME的数据结构的RVA。(这里用来判断最高位的值0x8000000,预定义值为 IMAGE_ORDINAL_FLAG32。)

l Hint字段也表示函数的序号,主要是用来便与加载器快速查找在导入的DLL的函数导出表,当通过这个序号查找到的函数跟所要导入的函数不匹配时,就改为通过名称查找。不过这个字段是可选的,有些编译器把它设置为0。
l Name1字段定义了导入函数的名称字符串,这是一个以0为结尾的字符串。
整个过程有点复杂,下图给出一个相对清晰的描述。
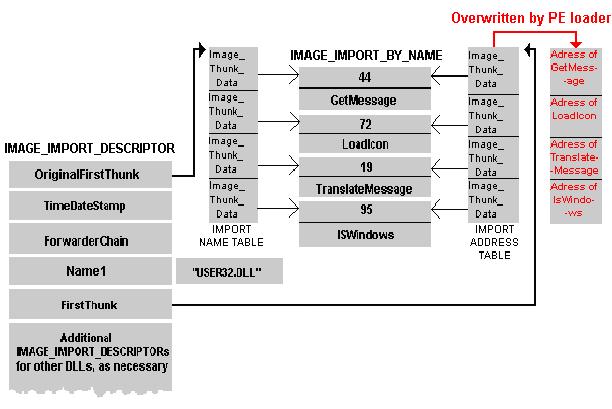
1. 加载器首先读入IMAGE_IMPORT_DESCRIPTOR,获得需要加载的动态库User32.DLL。
2. 加载 器根据OriginalFirstThunk或FirstThunk所指向的IMAGE_THUNK_DATA数组的RVA来获取真正的输入函数名称表 (INT)和输入函数地址表(IAT)。这里这两个表所指向的是同一个IMAGE_IMPORT_BY_NAME数据结构的RVA。
3. 加载器根据IMAGE_IMPORT_BY_NAME的序号或名称到导入的DLL(user32.dll)函数导出表中获取导入函数的地址。然后把这个地址替换掉FirstThunk所指向的函数输入地址表中的数据。
上图已经说明了为什么会存在两个一模一样的IMAGE_THUNK_DATA数组。答案就是在这个PE文件被装 入内存后,FirstThunk所指向的IMAGE_THUNK_DATA内的值将被改为用来存储导入函数的真正的地址。我们称之为IAT(Import Address Table). 其实在数据目录表DATA_DIRECTORY中的第13项(索引为12)直接给出了这个IAT的地址和大小. 可以直接通过数据目录快速获得这个IAT表. 但是这样还不足于说明为什么会存在两个一样的IMAGE_THUNK_DATA数组。INT好象没有存在的 必要。这里要涉及到一个绑定的概念。
绑定:
l 在 加载器加载PE文件的时候,先需要检查输入表获取要输入的DLL的名称,然后把DLL映射到进程的地址空间。再检查IAT表里的 IMAGE_THUNK_DATA数组所指向的字符串获取要输入函数的名称,然后用输入函数的地址替换掉IMAGE_THUNK_DATA数组内的数据。 整个过程需要相对比较长的时间。如果事先在链接的时候就把这些地址写入IAT中,那么就会节省很多时间。这就是绑定的由来。
l 再绑定后,PE文件IAT表里放着是导入DLL输出函数的实际内存地址。要使绑定的结果能正常运行,需要两个条件:
n 在加载PE文件所需的DLL的时候,DLL应该被映射到它们自己PE头里定义好的ImageBase这个地址。
n 被执行绑定后,PE文件所导入DLL的函数导出的函数表里的函数符号的位置不能发生改变。
l 这 两个条件当然很难在长时间内很难满足。比如,这个被导入的DLL发生了变化,增加了新的函数输出。那么其原来输出表内的函数符号的位置发生了变化。那么这 个时候,原先绑定的结果就会发生错误。为了解决这个问题,所以就同时定义了INT这个表。让它做为IAT的备份。一旦预先绑定好的IAT发生了错误,那么 加载器便会从INT里获取所需要的信息。
这就是为什么会存在两个一模一样的IMAGE_THUNK_DATA数组真正的缘由。微软的链接器一般总会在生成IAT的同时生成一个INT;而Borland的链接器却只生成IAT。所以Borland生成的PE文件是不能被绑定的。
那么,当加载器加载PE文件的时候,需要判断当前的绑定是否有效。在数据目录(Data Directory)的第12项(序号为11)所指向的一组数据结构IMAGE_BOUND_IMPORT_DESCRIPTOR就是用来检查这个有效性的。
成员
大小
描述
TimeDateStamp
DWORD
必须与被输入的DLL的PE头内的TimeDateStamp一样,如果不一致,那么加载器就会认为绑定的对象有误,需要重新修补输入表。
OffsetModuleName
WORD
第一个IMAGE_BOUND_IMPORT_DESCRIPTOR结构到被输入DLL名称的偏移(非RVA)。
NumberOfModuleForwarderRefs
WORD
包含紧跟在这个结构后面IMAGE_BOUND_FORWARDER_REF的数目。
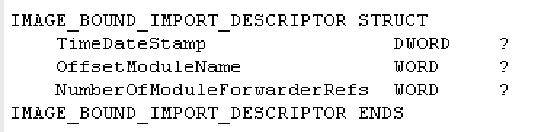
这个结构跟IMAGE_BOUND_IMPORT_DESCRIPTOR其实很象除了最后一个成员。它主要用于,在被导入的DLL中的某一个函数是转向导出时,这个结构就用来给出所转向到的函数的信息。
延迟加载:
除了通过加载器建立IAT表以外,程序调用外部DLL函数还有另外一种方式。就是先通过LoadLibrary动态加载DLL,然后用GetProcAddress获取所需函数的地址。这种方式称之为“延迟加载”。
数据目录(Data Directory)第14个成员(序号是13)IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT条目就是指向延迟加载的数据。这个数据就是由一个名叫ImgDelayDescr数据结构组成的数组。
ImgDelayDescr = packed record
grAttrs: DWORD;
szName: DWORD;
phmod: PDWORD;
pIAT: TImageThunkData32;
pINT: TImageThunkData32;
pBoundIAT: TImageThunkData32;
pUnloadIAT: TImageThunkData32;
dwTimeStamp: DWORD;
end;
成员
描述
grAttrs
设为1的时候,下面的各个成员都是RVA,否则是VA(虚拟地址)。
szName
指向一个DLL名称的RVA。
phmod
指向一个HMODULE的RVA。
pIAT
指向DLL的IAT的RVA。
pINT
指向DLL的INT的RVA。
pBoundIAT
可选的绑定IAT的RVA。
pUnloadIAT
指向DLL的IAT的未绑定拷贝
dwTimeStamp
延迟装载的输入DLL的时间/日期。通常是0。
九、 Windows加载器
加载器读取一个PE文件的过程如下:
1. 先读入PE文件的DOS头,PE头和Section头。
2. 然后根据PE头里的ImageBase所定义的加载地址是否可用,如果已被其他模块占用,则重新分配一块空间。
3. 根据Section头部的信息,把文件的各个Section映射到分配的空间,并根据各个Section定义的数据来修改所映射的页的属性。
4. 如果文件被加载的地址不是ImageBase定义的地址,则重新修正ImageBase。
5. 根据PE文件的输入表加载所需要的DLL到进程空间。
6. 然后替换IAT表内的数据为实际调用函数的地址。
7. 根据PE头内的数据生成初始化的堆和栈。
8. 创建初始化线程,开始运行进程。
这里要提的是加载PE文件所需DLL的过程是建立在六个底层的API上。
LdrpCheckForLoadedDll:检查要加载的模块是否已经存在。
LdrpMapDll:映射模块和所需信息到内存。
LdrpWalkImportDescriptor:遍历模块的输入表来加载其所需的其他模块。
LdrpUpdateLoadCount:计数模块的使用次数。
LdrpRunInitializeRoutines:初始化模块。
LdrpClearLoadInProgress:清楚某些标志,表明加载已经完成。
十、 插入代码到PE文件
有三种方式可以插入代码到PE文件:
1. 把代码加入到一个存在的Section的未用空间里。
2. 扩大一个存在的Section,然后把代码加入。
3. 新增一个Section。
方法一、增加代码到一个存在的Section。
首先我们需要找到一个被映射到一个块有执行权限的Section。最简单的方式就是直接利用CODE Section。
然后我们需要查找这块Section内的多余空间(也就是填满了00h)。我们知道一个Section有两个数据来表示其大小。 VirtualSize和SizeOfRawData。这个VirtualSize代表Section里代码实际所占用的磁盘空间。 SizeOfRawData代表根据磁盘对齐后所占的空间。通常SizeofRawData都会比VirtualSize要大。如下图。
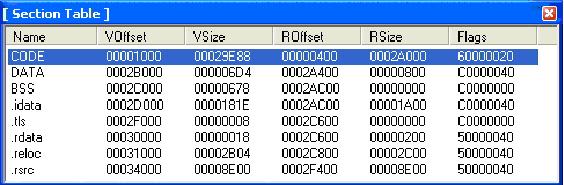
图中的SizeOfRawData是0002A000,而VirtualSize是00029E88。当PE文件被加载到内存的时候,他们之间 的多余空间的数据是不会被加载到内存去。那么如果要把加入到这个间隙中间的代码也被加载到内存去,就需要修改VirtualSize的值,这里把 VirtualSize的值可以改为00029FFF。这样,我们就有了一小段空间加入自己的代码。下面需要做的就是先找到PE文件的入口点 OriginalEntryPoint,比如这个OriginalEntryPoint是0002ADB4,ImageBase是400000,那么入口 点的实际虚拟地址是0042ADB4。然后计算出自己代码的起始RVA,更换掉PE头内的OriginalEntryPoint,在自己的代码最后加上:
MOV EAX,00042ADB4
JMP EAX
这样就可以在PE文件被加载的时候,先运行自己的代码,然后再运行PE文件本身的代码。成功的把代码加入到了PE文件内。
方法二、扩大一个存在的Section来加入代码。
如果在一个Section末尾没有足够的空间存放自己的代码,那么另外一种方法就是扩大一个存在的Section。一般我们只扩大PE文件最尾部的Section,因为这样可以避免很多问题,比如对其他Section的影响。
首先我们的找到最后一个Section使之可读可执行。这可以通过修改其对应Section头部的Characteristics来获得。然后 根据PE头内文件对齐的大小,修改其SizeOfRawData。比如文件对齐的大小是200h,原先SizeOfRawData=00008000h, 那么我们增加的空间大小应该是200h的整数倍,修改完的SizeOfRawData至少是00008200h。增加完空间后,需要修改PE头内的两个字 段的数值,SizeOfCode和SizeOfInitialishedData。分别为它们增加200h的大小。这样我们就成功的扩大了一个 Section,然后根据方法一内的方式把代码加入到增加的空间。
方法三、新增一个Section来加入代码。
如果要加入的代码很多,那么就需要新增一个Section来存放自己的代码。
l 首先,我们需要在PE头内找到NumberOfSections,使之加1。
l 然后,在文件末尾增加一个新的空间,假设为200h,记住起始行到PE文件首部的偏移。假如这个值是00034500h。同时将PE头内的SizeOfImage的值加200h。
l 然后,找到PE头内的Section头部。通常在Section头部结束到Section数据部分开始间会有一些空间,找到Section头部的最后然后加入一个新的头部。假设最后一个Section头部的数据是:
1. Virtual offset : 34000h
2. Virtual size : 8E00h
3. Raw offset: 2F400h
4. Raw size : 8E00h
而文件对齐和Section对齐的数据分别是:
5. Section Alignment : 1000h
6. File Alignment : 200h
l 那么新增加的Section必须与最后一个Section的边界对齐。它的数据分别:
1. Virtual offset : 3D000h (因为最后一个Section的最后边界是34000h + 8E00h = 3CE00h,加上Section对齐,则Virtual offset的值为3D000h)。
2. Virtual size : 200h。
3. Raw offset: 00034500h。
4. Raw size: 200h.
5. Characteristics : E0000060 (可读、可写、可执行)。
l 最后,只需要修改一下PE头内的SizeOfCode和SizeOfInitialishedData两个字段,分别加上200h。
l 剩下的就是按照方法一的方式把代码放入即可。
十一、 增加执行文件的输入表项目。
在一些特殊用途上,我们需要为执行文件或DLL增加其不包含的API。那么可以通过增加这些API在输入表中的注册来达到。
1. 每一个输入的DLL都有一个IMAGE_IMPORT_DESCRIPTOR (IID)与之对应。PE头中的最后一个IID是以全0来表示整个IID数组的结束。
2. 每一个IID至少需要两个字段Name1和FirstThunk。其他字段都可以设置为0。
3. 每一个FirstThunk的数据必须是一个指向IMAGE_THUNK_DATA数组的RVA。每一个IMAGE_THUNK_DATA又包含了指向一个API名称的RVA。
4. 如果IID数组发生改变,那么只需要修改数据目录数组中对应输入表的数据结构IMAGE_DATA_DIRECTORY的iSize。
增加一个新的IID到输入表的末尾,就是把输入表末尾的全是0的IID修改成增加的新的IID,然后在增加一个全0的IID作为输入表新的末 尾。但是如果在输入表末尾没有空间的话,那就需要拷贝整个输入表到一个新的足够的空间,同时修改数据目录数组对应输入表的数据结构 IMAGE_DATA_DIRECTORY的RVA和iSize。
步骤一、增加一个新的IID。
-
把整个IID数组移到一个有足够空间来增加一个新的IID的地方。这个地方可以是.idata段的末尾或是新增一个Section来存放。
-
修改数据目录数组对应输入表的数据结构IMAGE_DATA_DIRECTORY的RVA和iSize。
-
如果必要,将存放新IID数组的Section大小按照Section Alignment向上取整(比如,原来大小是1500h, 而section Alignment为1000h,则调整为2000h)以便于整个段可以被映射到内存。
-
运行移动过IID数组的执行文件,如果正常的话,则进行第二步骤。如果不工作的话,需要检查新增的IID是否已经被映射到内存及IID数组新的偏移位置是否正确。
步骤二、增加一个新的DLL及其需要的函数。
-
-
在.idata节内增加两个以null结尾的字符串,一个用来存放新增的DLL的名字。 一个用来存放需要导入的API的名称。这个字符串前需要增加一个为null的WORD字段来构成一个 Image_Import_By_Name数据结构。
-
计算这个新增的DLL名称字符串的RVA.
-
把这个RVA赋予新增的IID的Name1字段。
-
再找到一个DWORD的空间,来存放Image_Import_by_name的RVA。这个RVA就是新增DLL的IAT表。
-
计算上面DWORD空间的RVA,将其赋予新增IID的FirstThunk字段。
-
运行修改完的程序。
-
====================
-
PE文件基础补注
关键词: PE文件 地址转换 IAT IMAGE_IMPORT_BY_NAME
前言: 最近学习PE, 略有心得, 拿来和大家分享.
感谢: 小虾斑斑, 非安全 ,Bookworm对我的帮助.附件:pe.rar
1.IMAGE_SECTION_HEADER小结:
1.1 获得节表数 :NumberOfSections = NtHeader->FileHeader.NumberOfSections;
1.2 节表获得方法
方法1.因为NT头之后就是节表,故,节表头地址就是nt头地址加上NT结构大小.
SectionHeader=(PIMAGE_SECTION_HEADER)((UINT32)NtHeader+(UINT32)(sizeof(IMAGE_NT_HEADERS)));
方法2.或者用ImageBase+SizeOfHeaders的办法直接定位.
SectionHeader=(PIMAGE_SECTION_HEADER)((UINT32)(NtHeader->OptionalHeader.ImageBase)+
(UINT32)(NtHeader->OptionalHeader.SizeOfHeaders));
方法3.既然节都是连在一起的,那么,也就可以这样:
SectionHeader= (PIMAGE_SECTION_HEADER) (NtHeader + 1),
方法4.论坛里面 hmimys 告诉的办法:
SectionHeader=(PIMAGE_SECTION_HEADER)((UINT32)NtHeader+0x18+
(UINT32)(NtHeader->FileHeader.SizeOfOptionalHeader));
到现在我还没有弄懂为什么 hmimys 说最好要用方法4而不用方法3.
2. IMAGE_IMPORT_DECSRITOR 小结:
2.1:获得引入表结构起始地址:
方法1:ImportDec = (PIMAGE_IMPORT_DESCRIPTOR)(NtHeader->OptionalHeader.DataDirectory[12].VirtualAddress);
这个方法我觉得理论上是对的,但是我在运行的时候总是得不到正确的地址.后来知道,似乎不能用'12',而要用IMAGE_DIRECTORY_ENTRY_IAT这个宏
方法2:ImportDes = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)(NtHeader->OptionalHeader.DataDirectory)+
(DWORD)(sizeof(IMAGE_DATA_DIRECTORY)*12));
方法3 : ImportDes = (PIMAGE_IMPORT_DESCRIPTOR)(NtHeader->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress-
Offset + (PBYTE)pMapping);
注 : 前两种方法都是从 IAT 中得出 IMAGE_IMPORT_DESCRIPTOR,而后面的那个是 非安全 大哥教的. 这里有个疑问:
3种方法都可以得到 IMAGE_IMPORT_DESCRIPTOR 结构,都可以得到函数名, 区别在于前两种方法枚举的函数名不全.
难道说两个结构都指向同一个结构PIMAGE_IMPORT_DESCRIPTOR?
2.2 IMAGE_IMPORT_DESCRIPTOR 结构既不是在Import Symbols中,也不是在IAT (IMAGE_IMPORT_ADDRESS_TABLE)中。它就是一个结构.
我原来说:"IMAGE_IMPORT_DESCRIPTOR 结构不是在Import Symbols中,是在IAT (IMAGE_IMPORT_ADDRESS_TABLE)中。" 有问题.
就是因为这个错误的理解, 让我走了好多死路.
这个是Winnt.h中关于 IMAGE_SYNMBOL的结构信息
typedef struct _IMAGE_SYMBOL {
union {
BYTE ShortName[8];
struct {
DWORD Short; // if 0, use LongName
DWORD Long; // offset into string table
} Name;
PBYTE LongName[2];
} N;
DWORD Value;
SHORT SectionNumber;
WORD Type;
BYTE StorageClass;
BYTE NumberOfAuxSymbols;
} IMAGE_SYMBOL;
typedef IMAGE_SYMBOL UNALIGNED *PIMAGE_SYMBOL;
而下面的是IAT:
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
BYTE Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
};
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
_IMAGE_IMPORT_DESCRIPTOR 结构联合中的OriginalFirstThunk , 就是到IMAGE_THUNK_DATA的RVA.
如果像下面这样写,也许更明白
typedef struct _IMAGE_THUNK_DATA {
union {
PBYTE ForwarderString;
PDWORD Function;
DWORD Ordinal;
PIMAGE_IMPORT_BY_NAME AddressOfData;
} ;
} IMAGE_THUNK_DATA,*PIMAGE_THUNK_DATA;
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
PIMAGE_THUNK_DATA OriginalFirstThunk;
} ;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;
PIMAGE_THUNK_DATA FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR,*PIMAGE_IMPORT_DESCRIPTOR;
3. 地址转换小结(RVAToOffset):
为什么要地址转换, 前人的文章说了很多,下面给出我的转换方法:
3.1 函数,它能给出RVA返回此RVA所在的节,来自 Matt Pietrek的书:
PIMAGE_SECTION_HEADER GetEnclosingSectionHeader(DWORD rva){
unsigned i;
PIMAGE_SECTION_HEADER section = IMAGE_FIRST_SECTION32(NtHeader);
for ( i=0; i < NtHeader->FileHeader.NumberOfSections; i++,section++){
if ( (rva >=section->VirtualAddress) &&
(rva < (section->VirtualAddress + section->Misc.VirtualSize)))
return section;
}
return 0;
}
注: hnhuqiong 给的 ollydump300110 的源码里面也有类似函数,但是,
很明显的有漏洞,那就是若RVA不在任何一个Section那么函数会返回最后
一个Section, 而不是像这里返回 0 .下面是原始连接
http://bbs.pediy.com/showthread.php?threadid=26520
3.2 RVAToOffset:
我一直没有注意的就是'Offset'这个词. Offset其实还是一个偏移,只不过是
在文件中, 要想得到目标文件的IAT, 就要将这个值加上由 MapViewOfFile 返回
的文件基址指针.
Offset的的获得 :
pSection = GetEnclosingSectionHeader(NtHeader->OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IAT].VirtualAddress);
Offset = (DWORD) (pSection->VirtualAddress - pSection->PointerToRawData);
以获得IMAGE_THUNK_DATA结构为例,给出用法:
ThunkData = (PIMAGE_THUNK_DATA)((DWORD)ImportDes->OriginalFirstThunk -
Offset + (PBYTE)pMapping);
呵呵, (DWORD)ImportDes->OriginalFirstThunk -Offset 得到的只是文件中的偏移,
注意加上由 MapViewOfFile 返回的pMapping. 如果你象我原来一样,加上的是
NtHeader->OptionalHeader.ImageBase , 那么恭喜你, 访问错误.
4. 用VC 6.0 + API获得IMAGE_IMPORT_BY_NAME结构的一点问题.
在 VC 里面, 在一个结构指针比如ThunkData后面加上'->'时, vc会自动的列出
结构的成员供你选择, 十分方便. 但是, 通过ThunkData继续想获得IMAGE_IMPORT_BY_NAME
结构的时候, 你在ThunkData后面加'->'时, 出来的是一个'u1'. 此时不要疑惑,
这个'u1'就是 IMAGE_THUNK_DATA 里面的那个 union 的名称, 所以你可以这样得到
IMAGE_IMPORT_BY_NAME结构:
ImportBN = (PIMAGE_IMPORT_BY_NAME)((DWORD)(ThunkData->u1.AddressOfData)-
Offset +(PBYTE)pMapping);
5. Iczelion的PE教程关于导入表的描述没有讲清楚,只是说用IMAGE_THUNK_DATA
的每个数组元素和IMAGE_ORDINAL_FLAG32,比较可以推断如果某个函数是由函数序数引出的,
我就误解成用ImportDes->OriginalFirstThunk或者ImportDes->FirstThunk 判断。是不是错的很远?
参考(【翻译】“PE文件格式”1.9版 完整译文(附注释))http://bbs.pediy.com/showthread.php?threadid=21932,
我们应该用IMAGE_THUNK_DATA结构里面的AddressOfData来判断。下面的代码可行:
while(ThunkData->u1.AddressOfData!=NULL){
ImportBN = (PIMAGE_IMPORT_BY_NAME)((DWORD)(ThunkData->u1.AddressOfData) - Offset +(PBYTE)pMapping);
//显示导入函数
if(((DWORD)ThunkData->u1.AddressOfData & IMAGE_ORDINAL_FLAG32) == 0){
AddText(hEdit,TEXT("%03d: %s\r\n"),i++,ImportBN->Name);
}
else{
AddText(hEdit,TEXT("%03d: Ord by Hint\r\n"),i++);
}
ThunkData ++;
}//End of while
6 导出表:
6.1 导出表的结构,
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
6.2 AddressOfNames 和AddressOfNameOrdinals 是一一对应的,只不过一个用于名字,
一个用于序号, 同一个函数的索引都相同。
6.3 NumberOfFunctions – NumberOfNames 应该就是由序号引出的函数数目了
6.4 对于由序号导出的函数,不知道有没有办法能通过序数找到函数名。个人考虑似乎不可能这样
找函数名字,不然,微软未公开的函数就都被我们通过函数序数枚举出来了? :)
7: 把我的PE查看器修改了下, 原来的在处理用序号引出的函数时会出错.:)- 转http://lwglucky.blog.51cto.com/1228348/283812/
-















 2540
2540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









