







Hash数据结构是一种非常常见的数据结构,作为一个程序员,你可能每天都在和它接触, 尽管很多时候你可能没有意识到。Hash在PHP内核中扮演了非常重要的角色,数组、变量作用域、函数参数列表等均是基于Hash实现。所以,在PHP里你能看到各种对于Hash的优化。
Hash数据结构
Hash数据结构,本质上为了解决计算机中真正意义的数组只能使用数字作为索引,而程序员却经常需要使用字符串或者其他更复杂的类型来作为数组key的问题。首先我们需要一个函数能把字符串转成数字。然后,由于数组的长度有限,我们还需要把这个数字映射到数组长度的区间里,一般使用取模操作。最后, 如果两个字符串最终计算出来的Hash值一样,将保存到数组相同的位置上,这种情况叫做Hash冲突。解决冲突的常见办法之一就是拉链法, 就是将Hash冲突的数据维护在一个链表里; 另一种比较常见的解决冲突的办法叫开放寻址。下图所示是一个典型的Hash结构:
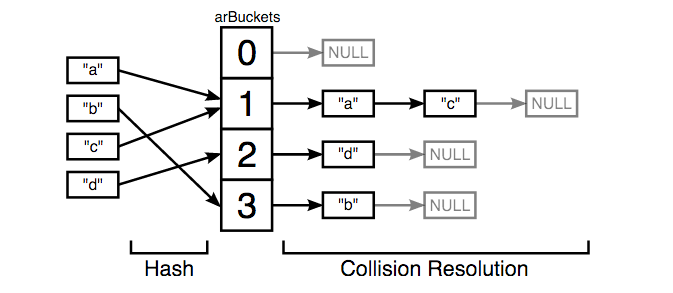
Hash函数的最优情况是,将key平均分布在数组空间中, 这样能获得最大的性能。最坏的情况是完全冲突,这个时候Hash表事实上已经退化为一个链表。前几年比较火的Hash攻击事实上就是构造大量的冲突key,使PHP的POST数组退化为链表,从而耗尽服务器的CPU资源。
因此我们可以得出一个结论, 一个优秀的hash函数应该符合两点:足够随机分布,足够快。
DJB2算法
PHP内核中的hash函数(http://www.cse.yorku.ca/~oz/hash.html)采用的是经典的djb2算法,源码为:

关于这个算法背后其实有很复杂的数学证明,我曾经看到过一篇文章给出了完整证明,受限于数学水平这里我只能从工程的角度来简单说一下结论:
奇数和素数能比偶数得到更随机的结果,所以可以看到hash函数里使用的是5381和33两个数。
为什么是5381?在这个讨论里(https://groups.google.com/forum/#!topic/comp.lang.c/lSKWXiuNOAk)谈到采用一个比255大而又不是特别大的素数都可以,djb2的作者也参与了讨论,他在讨论里说他选择了5381,只是因为5381符合这个条件, 并没有其他特殊的原因。
为什么是33?其实有很多数都可以,采用33是因为n*33可以优化为n << 5 + n,可以把一个耗时的乘法操作优化为移位操作,毕竟hash函数的效率是非常重要的。
我们看下PHP内核中的Hash函数实现:
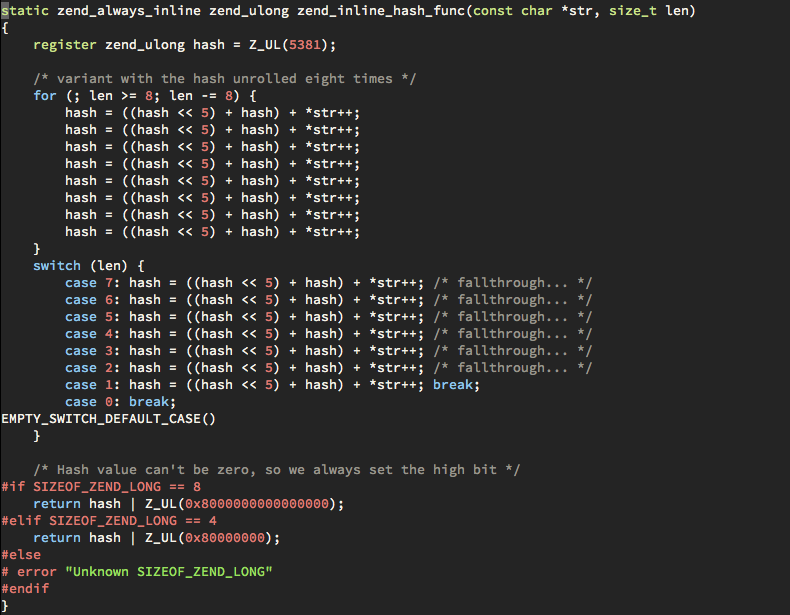
可以看出来PHP采用的就是djb2算法,但是似乎和经典的djb2算法有些差距。其实是PHP内核开发者对这个函数做了进一步的优化。
达夫设备
达夫设备(https://zh.wikipedia.org/wiki/%E8%BE%BE%E5%A4%AB%E8%AE%BE%E5%A4%87)的本质在于减少循环次数。考虑下面的代码:

这段代码的特点是非常简单,简单到循环本身就占用了大多数性能开销,因为每次循环都需要做累减和比较。因此减少循环次数反而成为了优化重点,这种情况在系统底层的内存复制的场景中经常出现。PHP中的Hash函数就采用了达夫设备这种技巧来优化, 循环次数减少为原来的1/8。
顺便说一句,实际上最早的达夫设备程序版本是这样的:

而且这段代码真的能编译通过。
取模优化
计算出来hash值之后我们需要把hash值映射到数组中, 比如hash值为15,数组a长度为10,15%10得到5, 最终保存在a[5]的位置上。但是取模操作在特定条件下是可以优化的。在PHP内核中,hash table的大小会设定为2的n次方。当数组大小为2的n次方时, hash % ht->nTableSize 可以优化为 hash & (ht->nTableSize - 1),也就是把除法操作优化成了位操作。
结语
我们看到,一个简单的hash函数背后都蕴含了如此丰富的优化技巧,难怪都说PHP是世界上最好的语言 :) 。















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









