







一、安装java
①下载并解压java1.7.0_79的tar包到 /usr/local 下并修改文件夹名称为 java7。
tar -xvf java1.7.0_79mv java1.7.0_79 java7②配置环境变量:
vi /etc/profileexport JAVA_HOME=/usr/local/java7
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/binsource /etc/profile
java -version测试一下是否安装成功,如果成功出现以下结果:
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
二、单机模式下安装Hadoop
①下载并解压Hadoop2.8.2的tar包到 /usr/local 下并修改文件夹名称为 hadoop。
②配置环境变量:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/binhadoop version测试一下是否安装成功,如果成功出现以下结果:
Hadoop 2.8.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 66c47f2a01ad9637879e95f80c41f798373828fb
Compiled by jdu on 2017-10-19T20:39Z
Compiled with protoc 2.5.0
From source with checksum dce55e5afe30c210816b39b631a53b1d说明Hadoop在独立模式下工作正常。默认情况下,Hadoop被配置为在非分布式模式的单个机器上运行。
③小例子:
第一步:新建一个input_test文件夹,往里拷贝一些带单词的txt文件,为了方便按照教程方式拷贝。
mkdir input_test
cp $HADOOP_HOME/*.txt input_test
ls -l input_test出现以下结果:
total 120
-rw-r--r-- 1 root root 99253 Nov 19 18:23 LICENSE.txt
-rw-r--r-- 1 root root 15915 Nov 19 18:23 NOTICE.txt
-rw-r--r-- 1 root root 1366 Nov 19 18:23 README.txt第二步:启动hadoop计数程序统计数量,在/usr/local/hadoop/share/hadoop/mapreduce中运行:
hadoop jar hadoop-mapreduce-examples-2.8.2.jar wordcount /usr/local/hadoop/input_test/ output第三步:查看运行的结果output下的part-r-00000文件:
cat output/* 出现以下结果,所有出现的单词以及出现的次数:
......
“License” 1
“Modifications” 1
“Original 1
“Participant”) 1
“Patent 1
“Source 1
“Your”) 1
“You” 2
“commercial 3
“control” 1
三、模拟分布式模式安装Hadoop
SSH设置和密钥生成
下面的命令用于生成使用SSH键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中 :
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \ > cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys①设置hadoop环境变量,修改 /etc/profile 文件并实时生效:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME source /etc/profile②配置hadoop:
为了使用Java开发Hadoop程序, 打开/usr/local/hadoop/etc/hadoop/hadoop-env.sh 设置java环境变量:
export JAVA_HOME=/usr/local/java7core-site.xml
core-site.xml文件中包含如读/写缓冲器用于Hadoop的实例的端口号的信息,分配给文件系统存储,用于存储所述数据存储器的限制和大小。
打开core-site.xml 并在<configuration>,</configuration>标记之间添加以下属性:
<configuration>
<property>
<name>fs.defaultFS</name>
<value> hdfs://机器的IP地址:9000</value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml 文件中包含如复制数据的值,NameNode路径的信息,,本地文件系统的数据节点的路径。这意味着是存储Hadoop基础工具的地方。
打开hdfs-site.xml 并在<configuration>,</configuration>标记之间添加以下属性:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>yarn-site.xml
此文件用于配置成yarn在Hadoop中。
打开 yarn-site.xml 并在<configuration>,</configuration>标记之间添加以下属性:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
此文件用于指定正在使用MapReduce框架。缺省情况下,包含Hadoop的模板yarn-site.xml。首先,它需要从mapred-site.xml复制。获得mapred-site.xml模板文件使用以下命令:
cp mapred-site.xml.template mapred-site.xml打开mapred-site.xml文件,并在此文件中的<configuration></configuration>标签之间添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>③验证hadoop安装, 使用命令“hdfs namenode -format”格式化一个新的分布式文件系统:
hdfs namenode -format 预期的结果如下 :
17/11/19 19:50:04 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = root
STARTUP_MSG: host = ubuntu/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.2
......
......
17/11/19 19:50:08 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/
④验证hadoop的dfs, 启动 NameNode 守护进程和 DataNode 守护进程 :
start-dfs.sh 预期结果如下:
17/11/19 21:52:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-ubuntu.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-ubuntu.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-ubuntu.out
17/11/19 21:53:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable⑤验证Yarn 脚本,执行如下命令用来启动yarn脚本。执行此命令将启动yarn守护进程:
start-yarn.sh 预期如下结果:
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-ubuntu.out
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-ubuntu.out⑥在浏览器访问Hadoop, 默认端口号为50070,使用网址获得浏览器Hadoop服务:
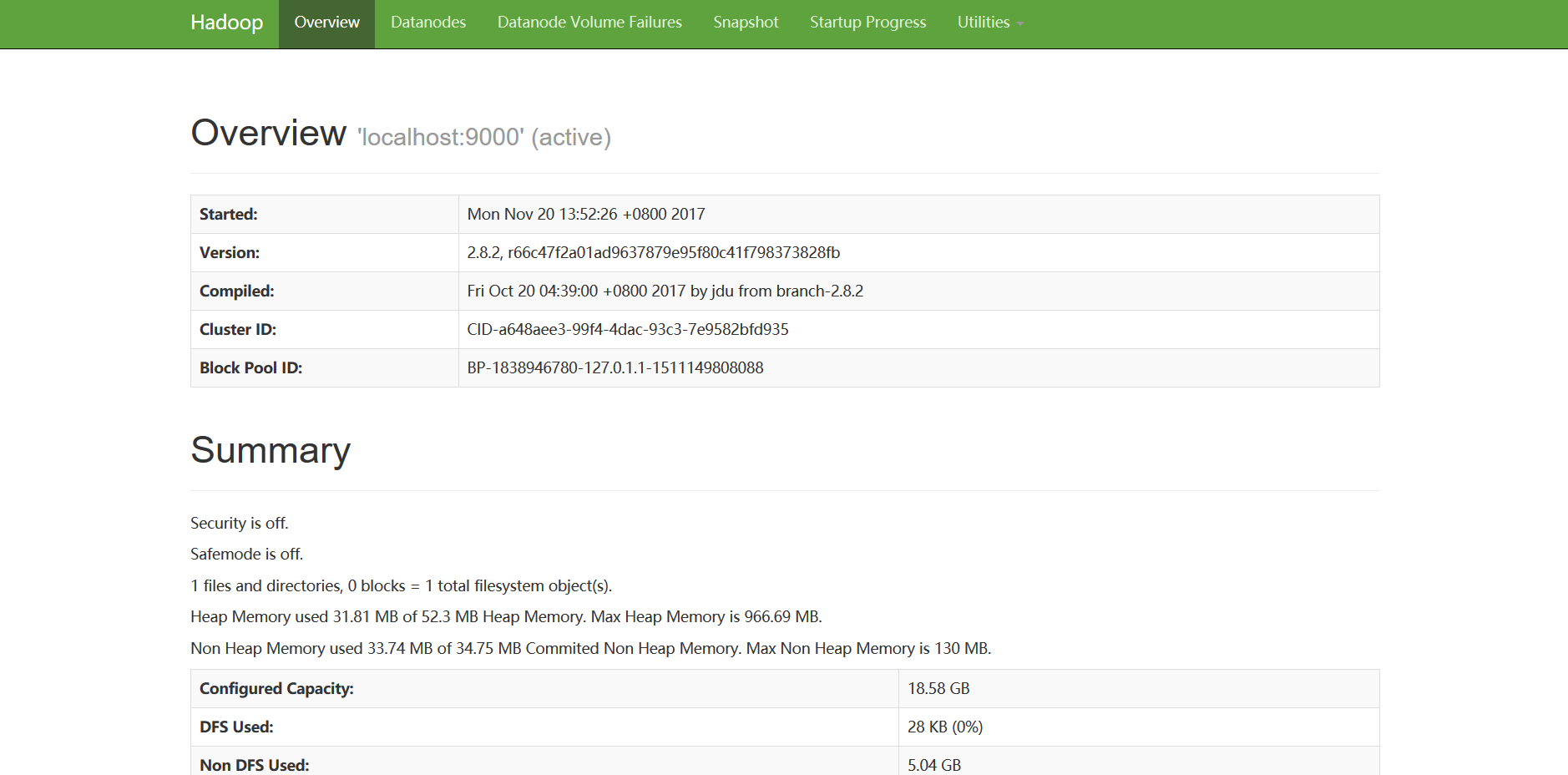
⑦验证所有应用程序的集群, 访问集群中的所有应用程序的默认端口号为8088。使用网址访问该服务:
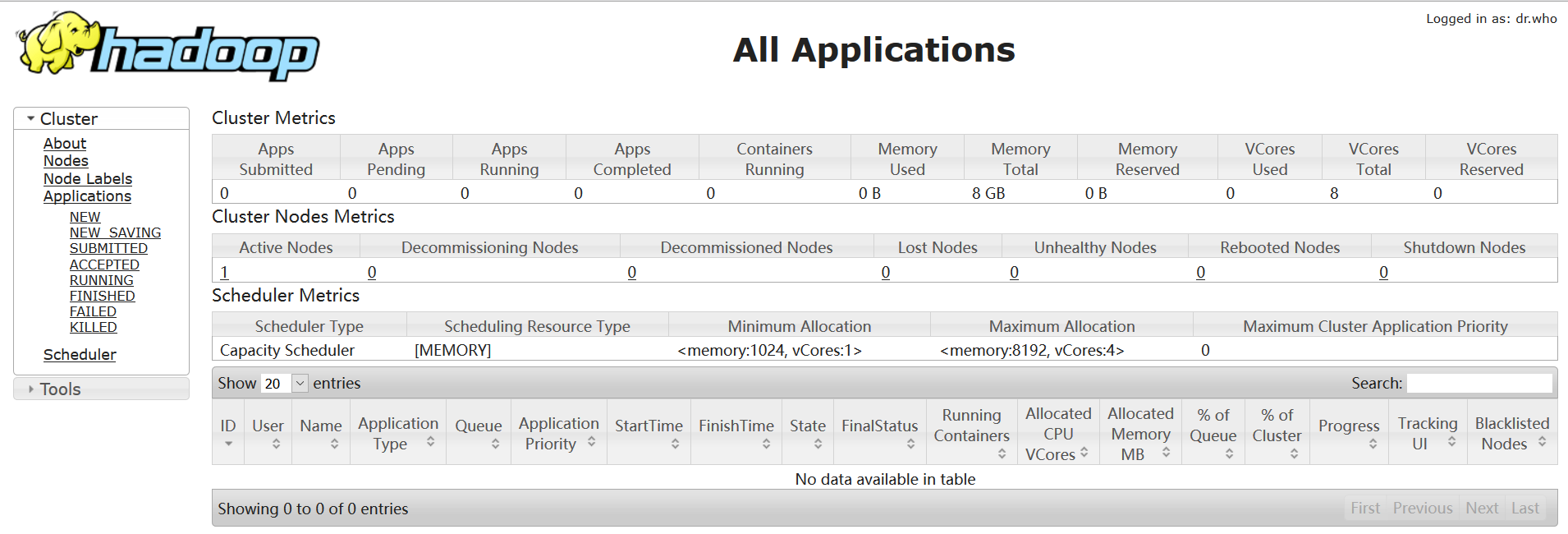















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









