







基本思路:
1、初始化一个或者多个入口链接为初始状态到链接表
2、爬虫爬取的黑名单和白名单,只有匹配白名单中的某一个且不匹配黑名单中的任何一个的链接才能通过
3、从链接表中取链接并置为下载状态,下载该链接的网页
4、把下载到的网页插入到内容表
5、从获取的网页中解析出链接,根据2中的规则过滤不需要的链接,把需要的链接以初始状态插入到连接表
6、把该链接置为已下载状态
然后循环步骤3、4、5、6,如果步骤3下载失败,则链接处于下载状态,并跳过该链接继续循环
代码实现
黑白名单
package com.data;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
*
* @author yun
* @date 2015年3月25日
* @time 上午11:01:57
* @todo 黑白名单
*
*/
public class Regex {
private List<String> blackList = new ArrayList<String>();
private List<String> whiteList = new ArrayList<String>();
public Regex(String blackPath, String whitePath) {
try (FileInputStream fis = new FileInputStream(blackPath);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr)) {
String line;
while ((line = br.readLine()) != null) {
line = line.trim();
if (line.length() == 0) {
continue;
}
blackList.add(line);
}
} catch (Exception e) {
System.out.println("读取黑名单出现异常:" + e.getMessage());
}
try (FileInputStream fis = new FileInputStream(whitePath);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr)) {
String line;
while ((line = br.readLine()) != null) {
line = line.trim();
if (line.length() == 0) {
continue;
}
whiteList.add(line);
}
} catch (Exception e) {
System.out.println("读取黑名单出现异常:" + e.getMessage());
}
}
public List<String> getBlackList() {
return blackList;
}
public void setBlackList(List<String> blackList) {
this.blackList = blackList;
}
public List<String> getWhiteList() {
return whiteList;
}
public void setWhiteList(List<String> whiteList) {
this.whiteList = whiteList;
}
}正则匹配
package com.data;
/**
*
* @author yun
* @date 2015年3月25日
* @time 上午11:02:01
* @todo 规则匹配
*
*/
public class Global {
public static boolean regex(String target, Regex regex) {
for (String black : regex.getBlackList()) {
if (!matches(target, black)) {
continue;
}
return false;
}
for (String white : regex.getWhiteList()) {
if (!matches(target, white)) {
continue;
}
return true;
}
return false;
}
private static boolean matches(String target, String regex) {
String[] splits = regex.split("\\{");
if (splits.length == 0) {
return target.equals(regex);
}
if (splits[0].length() != 0 && !target.startsWith(splits[0])) {
return false;
}
target = target.substring(splits[0].length());
if (splits.length < 2) {
return true;
}
for (int x = 1; x < splits.length; x++) {
target = matcheSplit(target, splits[x]);
if (target == null) {
return false;
}
}
if (target.length() != 0) {
return false;
}
return true;
}
private static String matcheSplit(String target, String split) {
String regex = getMatches(split.substring(0, split.indexOf("}")));
if (regex == null) {
return null;
}
String splitEnd = split.substring(split.indexOf("}") + 1);
if (splitEnd.length() == 0) {
return target.matches(regex) ? "" : null;
}
if (!target.contains(splitEnd)) {
return null;
}
String targetStart = target.substring(0, target.indexOf(splitEnd));
target = target.substring(target.indexOf(splitEnd));
if (!targetStart.matches(regex)) {
return null;
}
if (!target.startsWith(splitEnd)) {
return null;
}
return target.substring(splitEnd.length());
}
private static String getMatches(String str) {
switch (str) {
case "d+":
return "\\d+";
case "d":
return "\\d";
case "*":
return ".*";
default:
return null;
}
}
}爬虫类
package com.data;
import java.io.IOException;
import java.net.UnknownHostException;
import java.util.Date;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.data.util.Hash;
import com.data.util.ZLib;
import com.mongodb.BasicDBObject;
import com.mongodb.DBCollection;
import com.mongodb.DBObject;
import com.mongodb.MongoClient;
/**
*
* @author yun
* @date 2015年3月25日
* @time 上午10:54:49
* @todo 爬虫
*
*/
public class Spider {
private BasicDBObject update = new BasicDBObject("$set", new BasicDBObject("status", 1));
private BasicDBObject query = new BasicDBObject("status", 0);
private MongoClient server;
private Regex regex;
public static void main(String[] args) {
try {
new Spider().execute();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
public void execute() throws InterruptedException {
init();
Thread[] threads = new Thread[Config.THREAD_COUNT];
for (int x = 0; x < threads.length; x++) {
threads[x] = new Thread(new Crawl());
threads[x].start();
}
for (int x = 0; x < threads.length; x++) {
threads[x].join();
}
server.close();
System.out.println("end");
}
private void init() {
try {
server = new MongoClient(Config.HOST);
} catch (UnknownHostException e) {
System.out.println(e.getMessage());
return;
}
loadConfig();
}
public synchronized void loadConfig() {
String blackPath = Config.BLACK;
String whitePath = Config.WHITE;
regex = new Regex(blackPath, whitePath);
}
private void analysisUrls(Document doc) {
Elements select = doc.select("a[href]");
for (Element link : select) {
String url = link.absUrl("href");
if (!Global.regex(url, regex)) {
continue;
}
saveUrl(url);
}
}
private void saveUrl(String url) {
if (url.contains("#")) {
url = url.substring(0, url.indexOf("#"));
}
DBCollection collection = server.getDB(Config.DB).getCollection("url");
BasicDBObject doc = new BasicDBObject();
doc.append("url", url);
doc.append("md5", Hash.getMd5String(url.getBytes()));
doc.append("status", 0);
doc.append("date", new Date());
try {
collection.insert(doc);
} catch (Exception e) {
return;
}
}
class Crawl implements Runnable {
@Override
public void run() {
DBCollection collection = server.getDB(Config.DB).getCollection("url");
while (true) {
DBObject find = collection.findAndModify(query, update);
if (find == null) {
break;
}
String url = find.get("url").toString();
Connection connect = Jsoup.connect(url).timeout(30000).followRedirects(true);
Document doc = null;
try {
doc = connect.get();
} catch (IOException e) {
System.out.println("crawl >> " + url + " >> " + e.getMessage());
continue;
}
System.out.println("crawl >> " + url);
if (doc == null) {
continue;
}
commitUrl(url);
analysisUrls(doc);
commitContent(doc.html(), url);
}
}
}
private void commitUrl(String url) {
DBCollection collection = server.getDB(Config.DB).getCollection("url");
BasicDBObject query = new BasicDBObject();
query.put("url", url);
BasicDBObject update = new BasicDBObject();
BasicDBObject modify = new BasicDBObject();
modify.put("status", 2);
update.put("$set", modify);
collection.update(query, update, true, true);
}
private void commitContent(String content, String url) {
try {
DBCollection collection = server.getDB(Config.DB).getCollection("content");
BasicDBObject doc = new BasicDBObject();
doc.append("url", url);
doc.append("data", ZLib.compress(content.getBytes(Config.CHARSET)));
doc.append("md5", Hash.getMd5String(url.getBytes()));
doc.append("date", new Date());
collection.insert(doc);
} catch (Exception e) {
return;
}
}
}配置类
package com.data;
public class Config {
public static String HOST = "192.168.16.215";
public static String DB = "stipo";
public static String ENTRYS = "D:/regex/" + DB + "/entry";
public static String CHARSET = "UTF-8";
public static String BLACK = "D:/regex/" + DB + "/black";
public static String WHITE = "D:/regex/" + DB + "/white";
public static int THREAD_COUNT = 5;
}黑名单(black)
{*}#
mailto{*}
{*}.pdf白名单(white)
http://www.stipo.gov.cn/flfgx.asp?id={d+}&pageno=&lx={*}
http://www.stipo.gov.cn/newx.asp?id={d+}&pageno=&lx={*}
http://www.stipo.gov.cn/sgjfzl.asp?id={d+}&pageno=&lx={*}
http://www.stipo.gov.cn/newx.asp?id={d+}&pageno={d+}&lx={*}入口(entry)
http://www.stipo.gov.cn/flfg.asp
http://www.stipo.gov.cn/new.asp?lb2=%CD%A8%D6%AA%B9%AB%B8%E6
http://www.stipo.gov.cn/sgjf.asp
http://www.stipo.gov.cn/new.asp?lb2=%CD%A8%D6%AA%B9%AB%B8%E6&pageno={2-13}初始化表和入口
package com.data;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.net.UnknownHostException;
import java.util.Date;
import com.data.util.Hash;
import com.mongodb.BasicDBObject;
import com.mongodb.DBCollection;
import com.mongodb.MongoClient;
public class Init {
public static void initUrlCollection(MongoClient server) {
DBCollection collection = server.getDB(Config.DB).getCollection("url");
BasicDBObject url_ = new BasicDBObject();
url_.put("url", 1);
collection.ensureIndex(url_, "url_", true);
BasicDBObject status_ = new BasicDBObject();
status_.put("status", 1);
collection.ensureIndex(status_, "status_");
}
public static void initContentCollection(MongoClient server) {
DBCollection collection = server.getDB(Config.DB).getCollection("content");
BasicDBObject url_ = new BasicDBObject();
url_.put("url", 1);
collection.ensureIndex(url_, "url_", true);
}
public static void initEntry(MongoClient server) {
DBCollection collection = server.getDB(Config.DB).getCollection("url");
try (FileInputStream fis = new FileInputStream(Config.ENTRYS);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr)) {
String line;
while ((line = br.readLine()) != null) {
line = line.trim();
if (line.length() == 0) {
continue;
}
if (line.contains("{")) {
addAll(collection, line);
continue;
}
add(collection, line);
}
} catch (Exception e) {
System.out.println("读取黑名单出现异常:" + e.getMessage());
}
}
private static void addAll(DBCollection collection, String line) {
String se = line.substring(line.indexOf("{") + 1, line.indexOf("}"));
int start = Integer.parseInt(se.substring(0, se.indexOf("-")));
int end = Integer.parseInt(se.substring(se.indexOf("-") + 1));
for (int x = start; x <= end; x++) {
String url = line.replace("{" + se + "}", String.valueOf(x));
add(collection, url);
}
}
private static void add(DBCollection collection, String line) {
BasicDBObject entry = new BasicDBObject();
entry.put("url", line);
entry.put("status", 0);
entry.put("md5", Hash.getMd5String(line.getBytes()));
entry.put("date", new Date());
collection.insert(entry);
}
public static void main(String[] args) throws UnknownHostException {
MongoClient server = new MongoClient(Config.HOST);
System.out.println("初始化链接表...");
initUrlCollection(server);
System.out.println("初始化内容表...");
initContentCollection(server);
System.out.println("初始化入口链接...");
initEntry(server);
}
}初始化后,运行爬虫类
运行步骤如下
1、先运行Init类

2、运行爬虫Spider
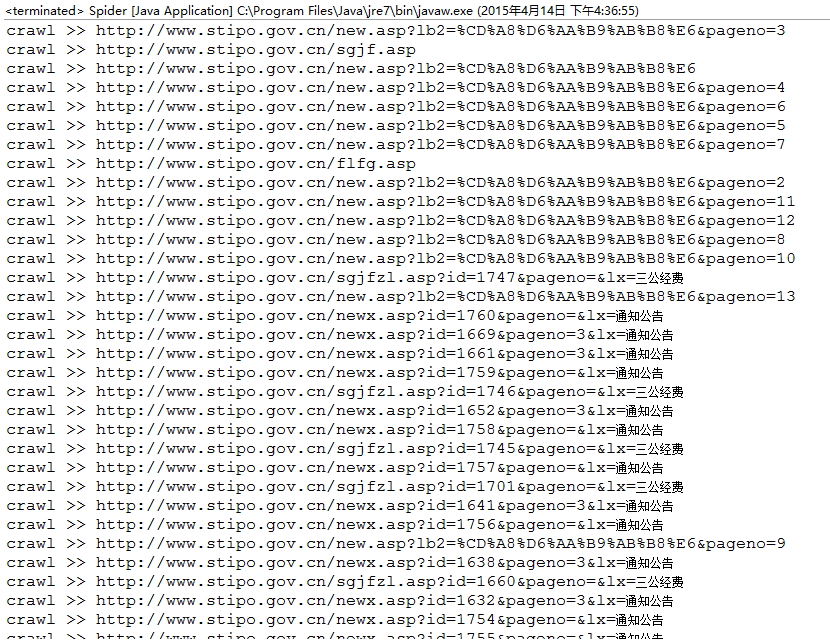
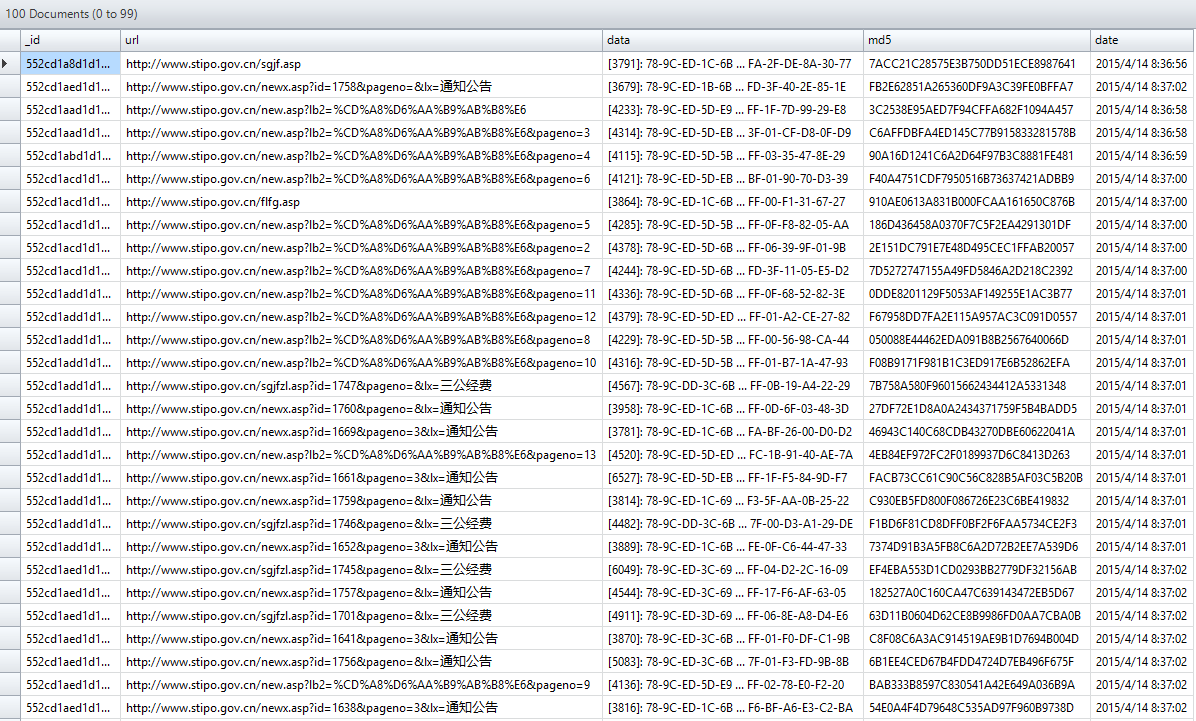
数据库中数据效果如下
总结:
1、全站爬取不适合用于需要登录、需要验证
2、封IP的网站也不太适合,如果这个做成分布式的,可以一定的程度上解决封IP的问题
3、黑名单设置严格些,可以有效的避免无效网页















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









